
Depuis 1 an j’essaie de réorganiser mes connaissances en BI afin de proposer « une meilleure formation BI au monde ». 🙂
Bien évidemment, dans ma formation j’ai du expliquer la modélisation « BUS » de Kimball (ce qu’on appelle « constellation » en France)… et j’étais tellement inspiré par « Probability Theory: The Logic of Science » de Jaynes que j’ai décidé de piétiner les canons de la formation BI et de déduire les règles de Kimball à partir des paramètres souhaités (desiderata) du système final.

Intéressant, n’est-ce pas ? Si on savait le faire, les futurs consultants/chefs de projets n’auraient pas besoin d’apprendre les règles – ils les comprendraient (et seraient motivés de les appliquer)…
Alors, on va essayer de déduire ces règles.
Règle #1
Prenons la première règle de modélisation de Kimball : toutes les tables dans le modèle sont classifiées en tables de faits et en tables de dimension

Pourquoi ? Kimball l’explique très bien – cela nous permet de choisir une table de faits et de descendre par les clés étrangères jusqu’au bout du modèle. Ainsi en descendant par les clés étrangères nous ne pouvons pas changer la granularité du résultat – elle correspond toujours à la granularité de la table de faits.
Cela évite toute frustration des utilisateurs :
Je peux, donc, conclure que cette modélisation doit garantir l’absence de problèmes de granularité (ex. cartésiens) :
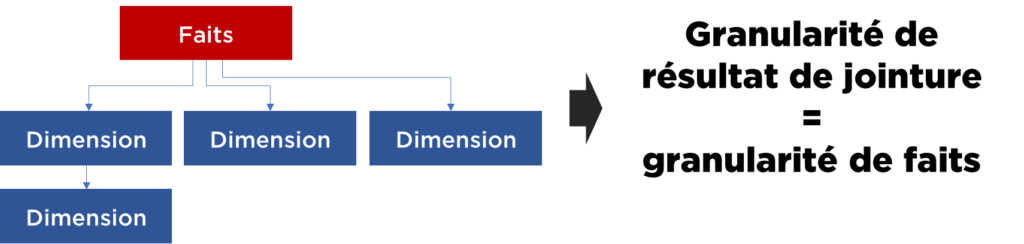
C’est cette même raison qui drive aussi l’idée que toutes les clés étrangères dans le modèle doivent être remplies (nulls remplacés par valeurs en correspondance avec une référence « inconnue »)… car si vous laissez la clé étrangère à null et votre utilisateur applique « inner join » au lieu de « left outer join », il va perdre les données de résultat…

Objection #1
En fait, si mes jointures sont toujours descendantes, mon modèle peut être pré-jointé et aplati en une seule table (quelque chose qui ressemble à un Data Frame / Data Set tellement aimé par les data satanistes).
C’est l’approche qui est exploité par TIBCO Spotfire et par Apache Superset. On peut ignorer complètement le modèle – donnez-moi un objet pré-jointé.

D’ailleurs Kimball utilise cette technique avec les dimensions pour transformer le schéma en flocon vers un schéma en étoile (pour « gagner en performance et en lisibilité »).
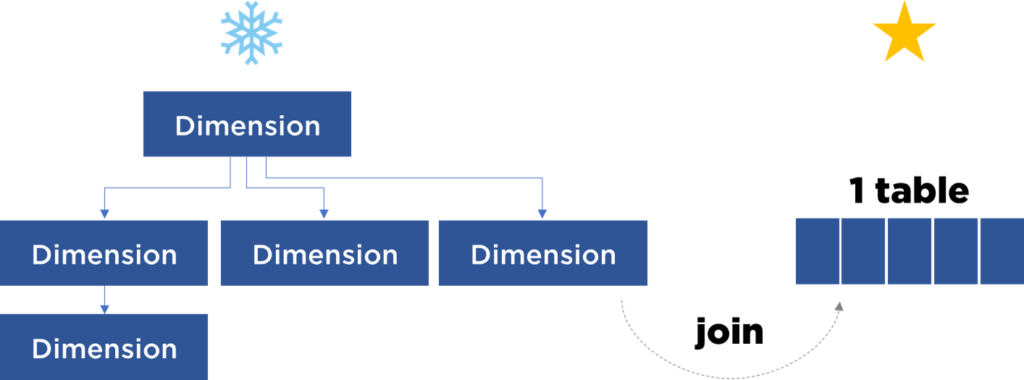
En même temps, Databricks va encore plus loin car elle propose de pré-jointer et de pré-agréger les jeux de données :
Gold tables refer to highly refined, generally aggregate views of the data persisted to Delta Lake. <…> gold table that stores summary statistics <…> this design avoids having to scan and join files from multiple tables every time this data is referenced…
Databricks Academy
I.e. nous ne pouvons pas déduire cette norme à partir de desiderata… 🙁
Objection #1bis
Dans la définition des tables de faits Kimball explicitement précise que les tables de faits ne doivent pas être référencées via les clés étrangères. Pour la même raison – c’est le point d’entrée d’analyse, c’est sa granularité…
IMHO c’est purement intellectuel car si vous savez ce que vous voulez analyser, vous choisissez cette table en tant que le point d’entrée et vous vous limitez par les jointures descendantes (i.e. ma table peut être quelconque, c’est juste pour l’analyse en question elle sera mon point d’entrée) :

I.e. je peux remplacer une contrainte de modélisation par une norme d’exploitation…
Règle #2
Dans les cas où l’analyse mono-fait est trop limitant, pour croiser plusieurs faits Kimball propose l’algorithme suivant :
- chaque table de faits est jointée avec les dimensions communes,
- chaque mesure est agrégée jusqu’au dimensions communes,
- résultat est jointé.
Autrement dit, pour éviter la démultiplication et les cartésiens, il faut faire la jointure seulement entre les tables de faits déjà agrégées.

Cette technique est optimisable (en termes de temps de calcul), mais pas mauvaise méthodologiquement.
Objection #2
Et voilà ! Une fois il y a une moindre complexité – il faut définir les normes d’exploitation au lieu de normes de modélisation.
D’ailleurs, il ne suffit pas joindre sur les mêmes tables de dimension. Il faut que les rôles de dimensions correspondent. Si vous avez DIM_TIERS référencé pas FAIT_VENTES et aussi par FAIT_ENTREE_STOCK, assez certainement il n’y a aucune raison de les croiser car dans un cas on parle de clients et dans l’autre – de fournisseurs. Malheureusement Kimball ne l’avait pas précisé et beaucoup de consultants (et outils) l’ignorent.
Sinon, voici le même schéma adapté pour un outil orienté Data Frames / Data Sets (ou même n’importe quel autre modèle) :
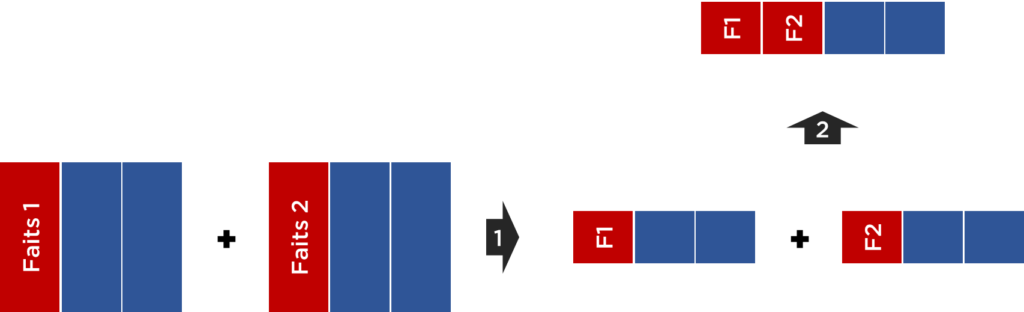
Règle #3
Encore une règle : les faits doivent contenir des mesures et des liens vers les dimensions, il ne faut pas ajouter beaucoup d’autres attribues dans les tables de faits…
Raison ? Performance de la lecture depuis le disque dur, i.e. si la base de données est « orientée ligne » (NSM, PAX) chaque nouveau champ stocké augmentera la quantité de données à lire à chaque requête (qu’on utilise le champ supplémentaire ou pas).
Objection #3
Sybase IQ ? DB2 BLU ? Toute autre base analytique ?

La règle était raisonnable pour les bases de données classiques (i.e. celles où les données sont physiquement stockées en forme de lignes). Aujourd’hui quand chaque base de données sait stocker en colonnes (oui, même MS SQL) il n’y a plus aucune raison pour ce genre de limitations.
Règle #4
…et dans les dimensions il faut convertir les données quantitatives en qualitatives
I.e. si vous avez un « nombre d’employés » dans votre DIM_CLIENT (ex. assurance, BTP), Kimball propose de les diviser en strates et de remplacer le nombre par le code ou par une libellé de la strate…
Raison ? Si vous avez des chiffres au niveau de « dimensions », elles se démultiplient après la jointure et vous ne devez pas les utiliser dans les agrégats.
Pas de chiffres – pas de problèmes.
Objection #4
Encore une fois notre modèle essaie de nous protéger contre certaines bêtises en limitant le scope d’application de notre modèle de données.
Premièrement, il suffit de former les utilisateurs ou faire en sort que les outils BI « comprennent » le contexte d’utilisation de chiffres. Car généralement il ne faut pas additionner les nombres stockés dans les champs qui ne sont pas 1-à-1 avec la granularité d’analyse :

Petite histoire : assez souvent je dois parler avec les candidat(e)s au poste « Consultant(e) BI ». Si je vois que la personne en face est vraiment expérimentée, je demande si la « FACTURE » est un fait ou une dimension. Au début 100% de candidates disent que c’est un fait.
Après je demande si dans ce cas « LIGNE DE LA FACTURE » (i.e. le détail de la facture) est une dimension ou un fait. C’est à ce moment que la plupart a du mal à me répondre… et par la suite je vois la compréhension venir : « FACTURE » est un fait dans un cas et une dimension dans un autre…
I.e. si je dois suivre Kimball à la lettre, dans un cas je dois mettre les chiffres et dans l’autre – strates. 🙁
Sinon, il y en a d’autres personnes qui disent que :
– la « FACTURE » est un objet inutile dans ce cas… et c’est faux,
– il faut dissocier ces deux tables et supprimer le lien qui existe entre elles… et ça ne marche pas toujours.
Règle #5
…et si dans la constellation il faut modéliser une relation N-à-N entre les dimensions, on utilise le « bridge »…
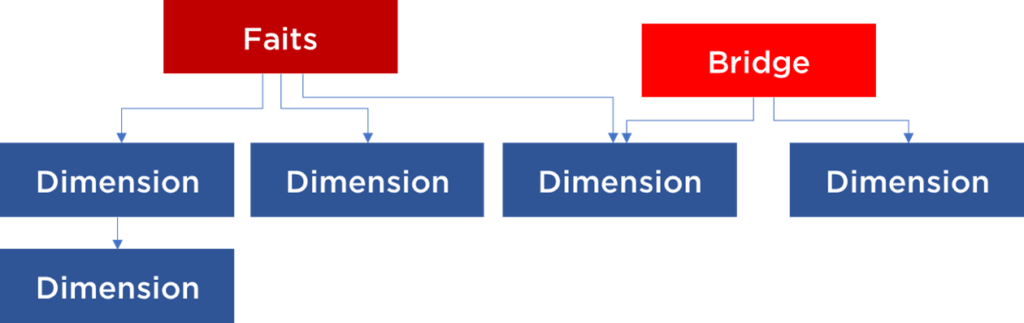
Le bridge c’est un hack qui nous permet de faire les analyses très avancés. Par contre, beaucoup d’outils BI ne savent pas l’utiliser correctement : au lieu d’une jointure ascendante (généralement interdite!), il faut utiliser une condition avec un « IN » (where champ IN (select … from Bridge where …)).
Objection #5
Dans le monde où il n’y a pas de faits ni de dimensions, il suffit de dire que les jointures ascendantes sont interdites, mais si nécessaire on peut faire un filtre avec un « IN »… et encore il y a des cas très spécifiques où on peut se permettre une jointure ascendante si nous acceptons la présence des effets de bord (exemple : analyse géographique des clients qui peuvent avoir plusieurs habitations).
<etc>
Conclusions
Je peux continuer, mais je pense avoir prouvé que la modélisation « style Kimball » n’est pas une pratique aussi bonne qu’on nous explique. Il y a cert beaucoup de points positifs… il peut se passer même que votre outil analytique exige une telle modélisation, mais généralement on peut remplacer les règles de modélisation par des règles d’exploitation sans perdre en fonctionnalité :
- toutes les tables sont comme elles sont (ni faits ni dimensions),
- on utilise les bases de données analytiques (XXI siècle !),
- tout analyse se commence par le choix de la granularité d’analyse,
- toutes autres données sont obtenues en descendant les FKs de la table avec la granularité choisie,
- utilisez LEFT OUTER JOIN si FK est nullable,
- si on doit remonter dans le modèle pour un filtre -> on utilise un « IN » au lieu de « JOIN »,
- dans les tables autres que celle de la granularité d’analyse, on utilise les nombres que pour filtrer et (presque) jamais pour agréger,
- si l’analyse croise deux granularités très différentes (ex. VENTES vs GARANTIE), il faut au début agréger jusqu’au niveau commun (à faire attention aux rôles),
- etc
Par contre, il y a beaucoup d’idées de Kimball qui sont très importantes :
- modèle bien pensé pour l’analyse spécifique simplifiera les requêtes (pour un contre-exemple – voir Data Vault),
- modèle dénormalisé peut donner la meilleure performance (moins de jointures),
- l’utilisation des clés techniques dans toutes tables est un MUST, mais pas pour des raisons de la performance – pour permettre la détection de doublons,
- etc
Malgré tout, je pense que la meilleure chose que je peux conseiller c’est « juste faites votre modèle et arrêtez vous enquêter concernant l’avis de Kimball ».
Bonne santé à vous et à vos systèmes.
PS. Si vous avez besoin de formations bien pensées, n’hésitez pas à me contacter.