
Any sufficiently advanced technology is indistinguishable from magic
Arthur C. Clarke
Bonjour,
Aujourd’hui nous allons parler de bases de données – outils que beaucoup entre vous ont déjà utilisés… outils qui contiennent l’information concernant chacun entre nous. Et pourtant savez-vous comment ils fonctionnent ?
Intro
Les premières bases de données existait depuis les années 1960s, mais les bases relationnelles comme nous les connaissons aujourd’hui sont apparus plus tard, dans les années 1970s suite aux travaux de M. Edgar Frank Codd (fameux IBMer) :

Codd formule les principes qui deviendront le cœur de fonctionnement pour toutes les bases relationnelles (d’ailleurs « relation » dans ce contexte correspond à une ligne de données avec plusieurs attribues et pas du tout à la relation entre les tables).
Si vous ne voulez pas lire l’original, je vous présente brièvement l’idée. Dans la base nous avons des « relations » (aka tables) et quelques opérations : « projection », « join » et autres. L’ensemble est « complet » de point de vu d’algèbre relationnel et remplace facilement des millions de lignes de code dans les grands systèmes.
Le langage SQL (ou SEQUEL) et les bases SQL sont arrivés plus tard (dans les années 70s-80s) en tant qu’une implémentation d’idées (assez abstraites et mathématiques) de M. Codd.

Aujourd’hui il est difficile d’imaginer des bases relationnelles sans SQL, mais tout pouvait tourner autrement.

https://dl.acm.org/doi/pdf/10.1145/361219.361221
Le standard actuel distingue 5 groupes de commandes + (souvent) des extensions :
- DDL (Data Definition Language) : langage de définition de la structure de base de données – commandes « create », « drop », « alter », etc
- DCL (Data Control Language) : définition de droits d’accès – commandes « grant », « revoke »
- DML (Data Manipulation Language) : modification de données dans la structure prédéfinie – commandes « insert », « update », « delete », « merge », etc
- TCL (Transaction Control Language) : gestion des transactions unitaires – commandes « commit », « rollback », etc
- DQL (Data Query Language) : extraction de données – commande « select »
Le langage n’est pas très complexe lui-même, mais il est extrêmement puissant, surtout pour la gestion de données de business.
C’est vraiment magique – pour développer une application sans une base de données, il faut être un pro dans les domaines de complexité d’algorithmes, structures de données, optimisation, etc. Nous n’avons pas besoin de toutes ces compétences pour créer une application avec une base de données.
Comment cette magie marche-t-elle ?

Note. Oui, vous pouvez utiliser un fichier CSV, mais
(1) si vous voulez mettre à jour les données au milieu de fichier, la nouvelle version de données peut être un peu plus longue que la précédente et il faudra réécrire l’ensemble du fichier (pensez aussi à une coupure de courant au moment de réécriture),
(2) il a des problèmes de suppression – pour supprimer dans un CSV il faut réécrire une partie de fichier,
(3) pour chercher les données quelconques il faudra relire l’ensemble du fichier (ce que vite deviendra la limitation d’outil).
Tandis que les commandes SQL « insert », « update », « delete » et « select » le font automagiquement à votre place.
Note. Je sais, il en existent aussi NoSQL, NewSQL, Hadoop, UniVerse et tout, et tout… Ce n’est pas le sujet aujourd’hui. Aujourd’hui la magie ne touche que les bases relationnelles.
Stockage
Objets
Au début nous devons décider ce que nous allons stocker.
Premier candidat est la liste de relations table que nous avons créé avec DDL :
--DDL : create table students ( id int not null, first_name varchar(100), last_name varchar(100), date_of_birth date ); --quasiment rien ne se passe dans le stockage - on a juste défini le modèle --maintenant le DML insert into students(id, first_name, last_name, date_of_birth) values (1, 'Daniel', 'TETU', '2000-02-29'); --et TCL pour confirmer la modification COMMIT; --et nous avons ajouté une ligne - la magie a fonctionné
Tout va bien ? C’est tout ?

Robert Downey Jr. n’est pas d’accord et il a raison. Un problème peut apparaître plus tard… Supposons que nous avons déjà ajouté 50’000 étudiants et maintenant nous voulons mettre à jour la fiche d’un(e) étudiant(e).
update students set last_name='FENEANT' where id=24047; COMMIT;
Pour le moment, notre modèle n’est pas optimisé pour exécuter une telle requêtes. Pourquoi ? Imaginez que la table est une « pile » de données sans moindre ordre (comme dans une chambre d’un enfant). Il peut se passer que les dernières données ajoutées seront quelque part vers la fin de fichier de la base de données (à la sortie de la chambre), mais ce n’est pas garanti.
Donc on doit créer un certain ordre ajouter un index :
create index students_id_idx on students(id);
Cela va créer le deuxième objet (en plus de la table) dans notre base de données – l’index par « id » d’étudiant. Le principe de fonctionnement d’index est le même que celui d’un inventaire bibliothécaire (très approximativement c’est une liste triée selon certains critères).
Mode de stockage
Comment allons-nous stocker nos objets sur un disque (je vais appeler « disques » SSD, HDD et autres technologique ) ?
Malheureusement, la terminologie dans ce domaine est très différente d’un éditeur à l’autre : dans les mondes DB2 et MS SQL on parle de pages et d’extents. Pour Oracle ça sera « extents » et « blocks », pour MySQL/InnoDB – « segments », « extents » et « pages », etc :
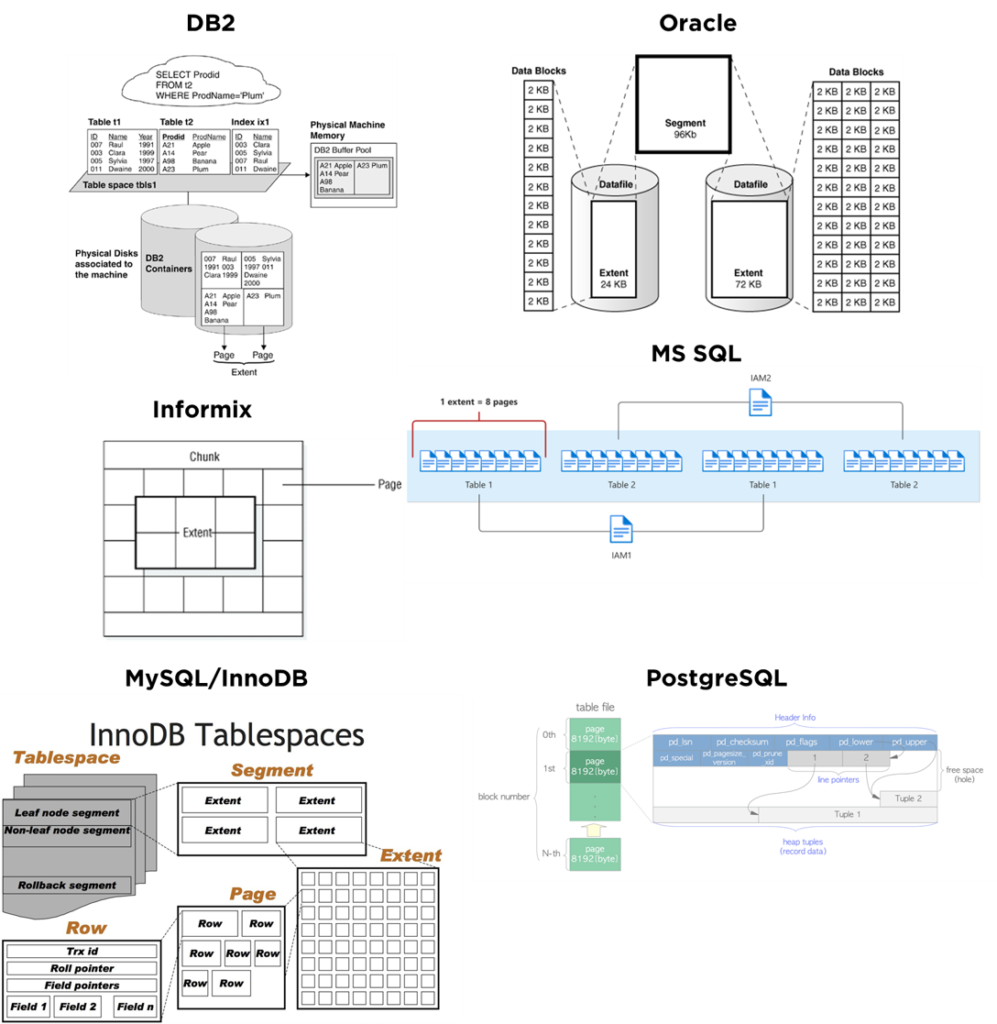
Elles ont toutes néanmoins le point commun: dans chaque base existe un certain niveau (que je vais appeler « page ») qui correspond plus ou moins à l’unité de lecture de données depuis le disque. La page peut faire partie d’une structure avec l’hiérarchie plus élevée (comme une poupée russe) : extent, chunk, datafile, etc, mais cela nous intéresse peu pour le moment.
Par contre, il se trouve que l’organisation de la page est importante pour la performance de la base de données. Il en existent 3 stratégies d’organisation majeures :
- stockage en ligne – « NSM » (« N-Ary Storage Model », classique);
- stockage mixte – « PAX » (« Partition Attributes Across »);
- stockage en colonne – « DSM » (« Decomposed Storage Model »).
Stockage en ligne (NSM)
Dans le cas le plus simple, la « page » aura la structure suivante :
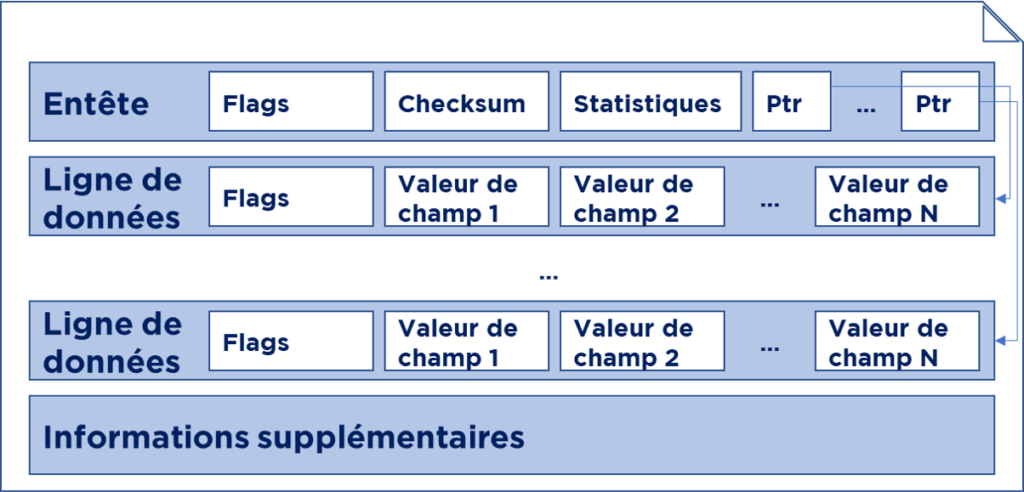
Chaque page a :
- une entête où on garde les informations concernant l’état de la page, la checksum (pour vérifier si les données ne sont pas endommagés), statistiques et parfois les « pointers » vers les données sur la page (cela dépend d’organisation de la page);
- lignes de données : chacune avec une petite entête et contenant les valeurs des champs;
- à la fin de la page on peut optionnellement trouver des infos supplémentaires.
Note. L’entête de la ligne peut contenir, par exemple un flag de suppression – quand on supprime les données, la base ne fait que flaguer les lignes en question et la suppression physique se passe durant la maintenance et la « réorganisation » de stockage.
Pour certaines bases de données (Oracle, PostgreSQL) même un « update » se transforme en « delete+insert » (c’est lié à la gestion d’accès concurrent de plusieurs utilisateurs à la même base de données).
Chaque ligne dans chaque table naturellement aura un certain adresse indiquant où elle est stockée (par exemple, ligne de table « students » avec id=24047 est stockée dans une page #3847, position #14, donc son adresse peut être #38470014). Bien évidemment, la manière de construction d’adresse est spécifique à chaque base de données :

Presque la même structure de la page peut être utilisée pour stocker les indexes. Avec une petite différence: les indexes vont contenir les #adresse de la ligne où les données sont stockées :

Nous pouvons maintenant exécuter assez facilement des requêtes classiques pour les systèmes transactionnels :
select * from students where id=24047; --rapide grâce à l'indexe update students set last_name='FENEANT' where id=24047; COMMIT; --aussi rapide grâce à l'indexe
Un seul bémol – à chaque changement de la table nous avons besoin de mettre à jour non seulement la table elle-même, mais aussi les indexes.
Par contre, ce problème de l’extraction/mise à jour d’une ligne par id est vraiment une bagatelle par rapport au cas que nous allons étudier maintenant.
Faisons une requête suivante :
select count(*) from students where date_of_birth between '2001-01-01' and '2001-12-31';
Si nous n’avons pas d’indexe sur « date_of_birth », la base de données devra lire toutes lignes de la table, mais pire encore, elle devra lire toutes les colonnes (l’ensemble de pages), rien que pour y trouver cette date de naissance. Et puis la base de données devra faire le filtre et le calcul… I.e. si pour stocker la date on a besoin de 2 ou 4 octets, est si l’ensemble de la ligne de données sera de ~30 octets en moyenne, on va perdre plus de 93% de temps de lecture sur le traitement des infos inutiles.

Ce n’est pas catastrophique pour le moment – c’est juste une perte de ressources, mais si la table est large (dizaines ou centaines de colonnes), ça va couter cher.
Pourquoi ? Il y a plusieurs raisons, mais la plus importante c’est que le disque est la partie la plus lente d’ordinateur. Si on compare le temps d’accès au disque avec le temps d’accès aux registres de CPU, la différence de magnitudes sera la même qu’entre le diamètre de Paris et la taille d’un fourmi. Il faut donc qu’on économise l’I/O avec le disque.

Stockage mixte (PAX)
Nous pouvons essayer de mettre plus de données dans la même « page » en utilisant la compression. Ainsi nous allons devoir compresser/décompresser les données à chaque fois, et, donc, il y aura une balance à prendre en compte entre la qualité de la compression et sa vitesse. Alors, l’idée est de diminuer la quantité d’IO avec notre disque sans trop surcharger le CPU.
En revanche, il faut prendre en compte ce qu’il en existent beaucoup de méthodes de compression différentes. Et parfois les méthodes avec la meilleure performance sont spécifiques aux certains types de données :
- si nous avons la liste de nombres avec des valeurs proches, au lieu de stocker la valeur de chaque nombre, nous pouvons stocker le premier nombre et puis les différences entre les nombres consécutifs,
- …la même chose s’applique aux dates, qui peuvent être représentés en tant que nombre de jours depuis une certaine « date de base »,
- …mais cela ne marchera pas pour le texte, qui, lui-même, peut être compressé avec le codage de Huffman, par exemple.
PAX (« Partition Attributes Across ») exploite cette idée en transposant les données et en regroupant les mêmes champs de différentes lignes :

I.e. nous allons stocker chaque champ de chaque ligne indépendamment et les compresser indépendamment (mais toujours sur la même page). Ainsi nous pouvons mettre plus de données dans la même page. En même temps, nous pouvons toujours reconstruire la ligne de données à partir de la même page, mais si, comme dans notre exemple précédent, nous avons besoin que d’un seul champ, nous n’avons pas besoin de décompresser l’ensemble de la page.
Nous obtiendrons également des bonus en termes d’exécution sur les CPUs actuels à cause de la meilleure utilisation des lignes de cache, etc.
Par contre, vous pouvez imaginer que les opérations basiques telles quelles « update », « insert » et « delete » doivent devenir plus « lourdes ». Alors, il faut mettre à jour les pages de façon intelligente. Par exemple, il vaut mieux attendre plusieurs mises à jours et les appliquer et même temps. I.e. pour la performance on paie par l’augmentation de la complexité des algos de la base de données.
Pas mal, mais on doit aller plus loin.

Stockage en colonne – « DSM »
Nous pouvons remarquer qu’il en existe toute une classe de systèmes avec le fort déséquilibre entre les attentes de vitesse de chargement de données et les attentes de vitesse de lecture de données… Business Intelligence, par exemple… Et pour résoudre ce problème le stockage en colonne peut être une bonne solution.
On sait qu’en BI les tables souvent contiennent BEAUCOUP d’attribues, mais à chaque requête nous utilisons qu’un petit jeu de champs. Par exemple, un contrat de crédit peut contenir les attribues suivants: code, client, valeur, ICNE, somme payée,… Mais dans une requête nous pouvons vouloir afficher seulement la somme d’ICNE par client – deux champs alors :
select id_client,sum(icne) from fait_contrat group by id_client
DSM (« Decomposed Storage Model », stockage en colonne) a trouvé la solution suivante : on découpe l’ensemble de notre table en colonnes et ensuite on stocke les colonnes indépendamment sur les pages différentes. De cette manière nous pouvons lire uniquement les pages dont nous avons besoin :
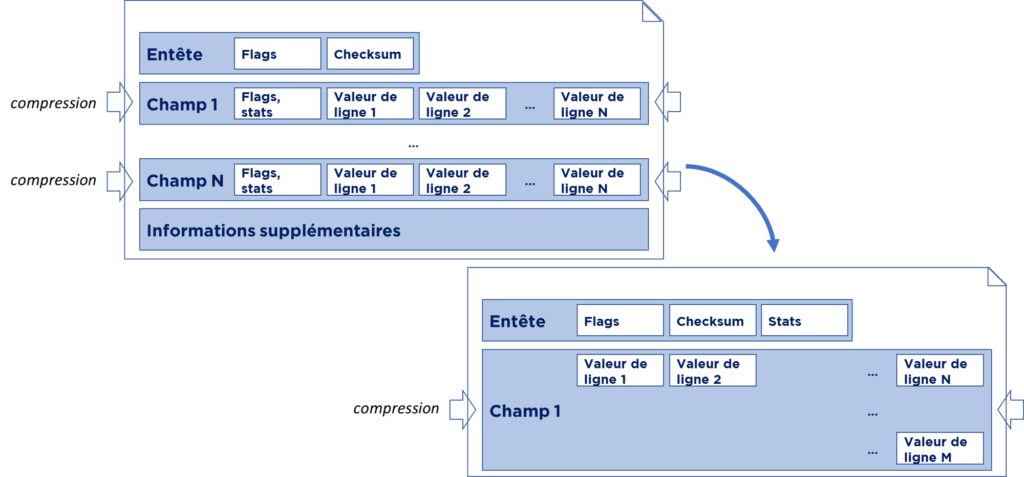
En fait, cela correspond presque entièrement (à delta de compression) au stockage d’indexe. I.e. toute notre table est juste un jeu d’indexes par chaque champ.
Points forts de cette solution :
- compression peut être encore plus efficace ;
- on diminue fortement la quantité d’I/O avec disque si nous choisissons qu’un sous-ensemble de champs;
- si on garde les statistiques (valeur minimal-maximal, filtre de Bloom, etc) nous pouvons ignorer des pages dont nous n’avons pas besoin (data skipping).
Résultat : requêtes de x3 à x10 plus rapides (parfois x40-x100).
Faiblesse : actions comme ajouter/modifier/supprimer une ligne seront des ordres de magnitude plus lent que dans une base utilisant NSM/PAX… Mais ce n’est pas si grave car si nous utilisons les chargements en masse, il es possible de mettre à jour le stockage de façon beaucoup plus optimal. Heureusement c’est ce qu’on fait dans le domaine de BI en général.
Conclusions
Nous avons vu 3 types de stockage pour les différentes charges : opérationnelles (transactionnelles) et analytiques.
Beaucoup de bases de données ont cette « spécialisation » (opérationnelle ou transactionnelle) et proposent des différentes garanties en termes de performance. C’est l’une des raisons, pourquoi Oracle performe souvent moins bien que, par exemple, Sybase IQ dans le domaine de Business Intelligence.

Par contre, il y a des bases de données qui, d’une manière ou d’une autre, ont implémenté les deux stockages dans le même moteur. Par exemple DB2 BLU propose différents types de stockage, MS SQL permet de créer les tables en colonne avec « columnstore indexes ».
Choisissez bien vos outils.
Bonne santé à vous et à vos systèmes.
A bientôt.