Bonjour,
Aujourd’hui je voudrais partager mon ressenti concernant cette nouvelle bête – le Reporing Factory.
La terminologie IT s’est mélangée avec le marketing autant que maintenant il est aussi compliqué de décrypter le nouveau terme que les numéros des CPUs d’Intel, mais il y a des grandes lignes :
- si nous voyons X factory – nous lisons « centralisation » (données, flux, effort),
- si nous voyons X mesh – nous lisons « décentralisation » (données, flux, effort),
- peu importe le X, assez souvent c’est encore un rebranding d’ancien concept devenu démodé.
Du coup, Reporting Factory = centralisation de développement des rapports… ou presque… 😉 De ce point de vu, ce n’est que la suite de renommages MIS-DSS-BI-RF avec certains ajustements (évolutifs) sur la composition de chaque notion…
Voici ce que nous dit la théorie :
- certaines organisations ont des problèmes de reporting (dont les plus impactés mais différemment sont les multinationales et les banques) :
- multinationales : il est difficile de gérer chaque équipe de chaque pays avec une approche personnalisée – il est plus simple de forcer des processus / KPIs standards ;
- banques : il y a un paquet des rapports réglementaires qui répètent les mêmes informations et nous voulons bien garantir la cohérence de ces différents rapports ;
- Data Lakes n’aident pas car la conséquence d’utilisation de données brutes est que chacun doit re-traiter ces données soi-même – cela ajoute des différences et des incohérences ;
- self-service peut être problématique car le but de self-service (ad hoc) est d’explorer des données et de trouver les axes d’amélioration ; self-service est « trop intelligent » et les organisations à certain niveau ont besoin de reproductibilité des résultats plus que l’intelligence (style « armée ») ;

- dans cette situation, la centralisation d’effort de production de certains rapports peut être une bonne idée (d’où Reporting Factory) ;
…ce que la théorie ne dit pas, mais laisse sous-entendre, c’est que vous pouvez traiter les autres cas selon vos préférences ; - pour centraliser l’effort, il faut avoir certaines compétences métier + techniques (flux, technologies de stockage, data quality, modélisation, présentation de données, documentation de données et de processus, transparence de règles, etc) ;
- du coup, si vous n’avez pas d’ensemble de ces compétences ou manquez en qualité de service, au lieu du monde de bisounours, vous allez vous retrouver dans un Mordor informatique où personne ne veut vôtre service et chacun tire le reporting dans son fichier Excel.

I.e. si vous avez une seule source de données propres (i.e. pas un Data Lake), si vous contrôlez les processus de façon centralisé et vous avez de l’expertise technique et fonctionnelle, tout marchera bien. Quelle surprise !
Maintenant regardons ce que les eXperts nous disent (généralement j’évite des jugements personnelles, mais là, il faut absolument que je cite mes sources) :
- il est proposé de mettre l’IT de côté (au lieu d’améliorer la communication) [Chappuis Halder] :
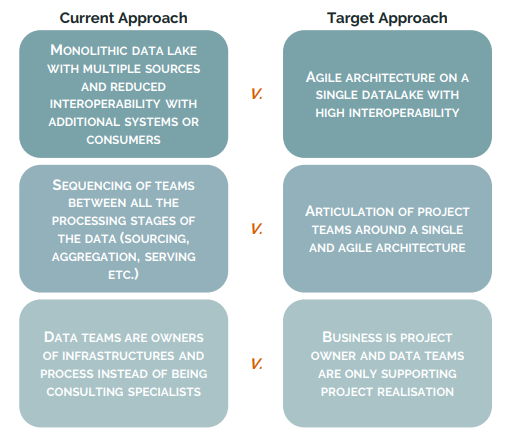
- …soit au minima créer des nouvelles équipes dédiées [offres de service / offres d’emploi] ;
- il est proposé d’utiliser partout des microservices / API [Chappuis Halder] (cette même organisation semble ne pas comprendre la notion du Data Lake) :

- il semble que pour traiter la DQ, il faut faire du « cleansing » (comme si d’autres approches n’existent pas) ;
- cette même organisation ne voit pas de risques liés à l’approche et pense garantir l’optimisation du temps, alors que le reporting ad hoc (qu’on tente éviter ici) est justement le moyen d’optimiser le temps

- certains autres sont d’accord avec le fait que RF optimise le temps [KPMG] : « Start-ups : Gagnez du temps avec Reporting Factory »

- certains [Redwood] pensent que le reporting sera plus rapide à produire, il sera de meilleure qualité et moins chère en même temps :

- tous les offres de service semblent dire que le Reporting Factory ne peut pas vivre à côté (dans le même environnement) que le reporting ad hoc, i.e. il faut absolument tout casser et refaire…
Bullshit total et voici pourquoi Je pense que ce n’est pas tout-à-fait vrai :
- Si les équipes techniques sont seulement les réalisateurs, comment pouvons-nous obtenir de l’expertise ? Les principes d’Agile sont-ils déjà morts ?
- Depuis quand le métier sait modéliser, produire, industrialiser, tester des solutions techniques ?
- Pourquoi la nouvelle équipe dédiée sera meilleure que l’existante ? C’est bien possible, mais je n’ai vu aucun levier permettant de garantir cela.
- Microservices ne donnent rien à l’approche lui-même, i.e. ils n’apportent pas de valeur pour l’utilisateur final du Data Factory (et personne n’a annulé les lois de la physique car la localité de données = performance) ;
- Sinon, du point de vue long-termiste, DQ doit être proactif et pas du tout réactif – c’est ridicule de corriger les erreurs si nous pouvons les éviter.
Conclusions
- Data Factory a la raison d’exister dans certaines circonstances ;
- visiblement, le DF ne peut être ni unique ni même le majeur moyen de production d’analyses ;
- la proposition du Data Factory n’est pas vraiment technique, mais plutôt organisationnelle ;
- pour mettre en place le Data Factory, vous n’êtes pas forcément obligés de tout casser et de tout refaire – ça peut être un changement d’offre d’équipe BI (ou Data Warehouse, Data Hub, Data Mesh, Data-whatever-else) existante.
Bonne santé à vous et à vos équipes.