
Il était une fois une organisation qui avait besoin d’un Data Hub.
La situation était d’apparence classique :
- plusieurs systèmes;
- un processus fonctionnel;
- besoin de synchroniser les systèmes plus ou moins en « temps réel humain »;
- time to production – « hier » (on a eu 3 à 5 semaines pour la v1 de production);
- pour différentes contraintes, nous ne faisons aucune « data quality ».
Quand nous parlons de synchronisation, nous voulons bien dire que le processus est bi-directionnel, i.e. si dans un système A on crée un « client », il doit apparaître dans le système B automatiquement, puis si on le modifie dans le système B, il doit se mettre à jour automatiquement dans le système A. I.e. nous voulons que les systèmes existants (basés sur différentes technologies) se comportent comme si c’était le même système. Ça fait une vraie différence avec un « ODS » ou un « Data Hub de distribution ».
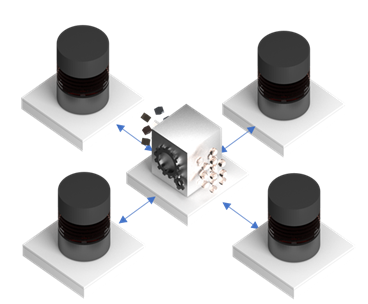
Voici ce qu’on a demandé :
- vérifier que chaque table dans les systèmes dispose d’une clé unique et non-modifiable (i.e. une fois la ligne est créée, la PK ne se change plus);
- vérifier si les modèles de données sont logiquement « compatibles », i.e. il n’y a pas d’ambiguïtés quelle donnée doit aller où (en fait, c’est très rare quand c’est le cas pour l’ensemble du modèle, donc on ne peut pas garantir qu’on peut toujours tout synchroniser);
exemple : si dans un système le nom et le prénom sont stockés dans un champ et dans un autre – dans différents, vous ne pouvez pas garantir la synchronisation sans erreur (et si vous pensez le contraire – essayez de « parser » « Cédric Martin » avec 100% de certitude); - vérifier si les types sont plus ou moins compatibles (sauf pour les clés étrangères);
- faire un mapping entre les nomenclatures et ce mapping doit être un-à-un (sinon, la mission de 5 semaines est impossible) – heureusement pour nous, c’était faisable (presque partout);
exemple : vous ne voulez pas essayer de « déduire » via les règles complexes si « Chine » du système A = « Chine » ou « Hong Kong » dans système B; - les systèmes ne doivent pas rejeter les données valables pour les autres systèmes (homogénéité de contrôle);
- avoir la possibilité d’ajouter un champ technique dans chaque table;
- alléger la contrainte de « temps réel » à « dizaines de secondes ou quelques minutes » (c’était plus que faisable).
Pourquoi ces demandes :
- les cinq premières demandes sont les conditions suffisantes pour pouvoir synchroniser les données dans les deux sens entre chaque système et chaque autre (suffisantes = plus que nécessaires);
- le champ technique est un « must » si vous êtes limités technologiquement (le CIO a oublié de nous demander quelle technologie on préfère pour ce genre de projet – ETL/ELT a été imposé);
- pour la même raison il était impossible de tenir la promesse de temps réel – on partait sur les micro-batches de synchronisation via un ETL/ELT.
Solution
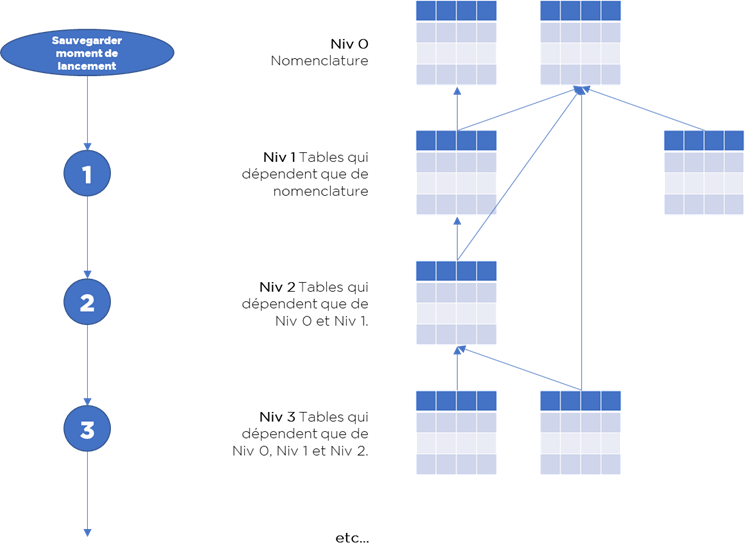
L’idée c’est de mettre en place un modèle de développement plus simple et le plus reproductible possible, voici ce qu’il faut faire pour chaque table (sauf pour la nomenclature – elle n’est pas synchronisée automatiquement) :
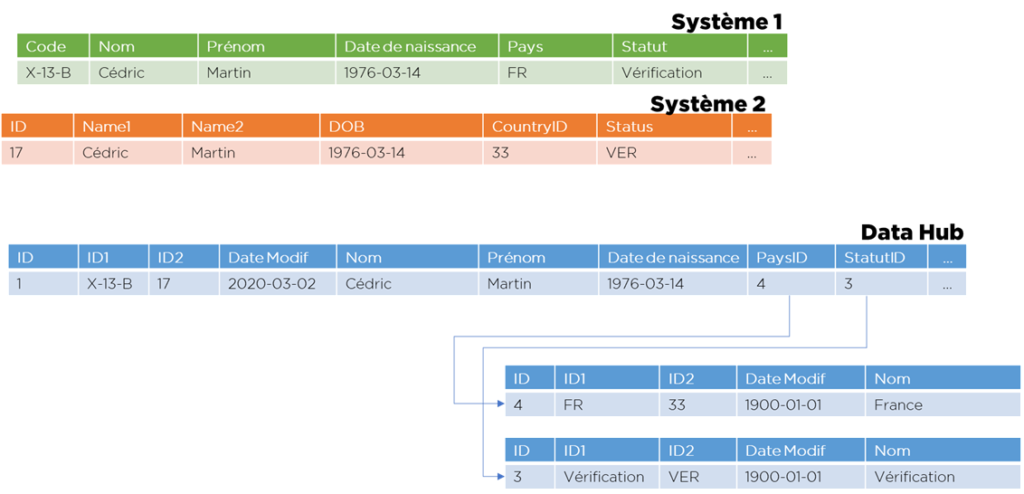
- Créer un modèle « universel » de données avec :
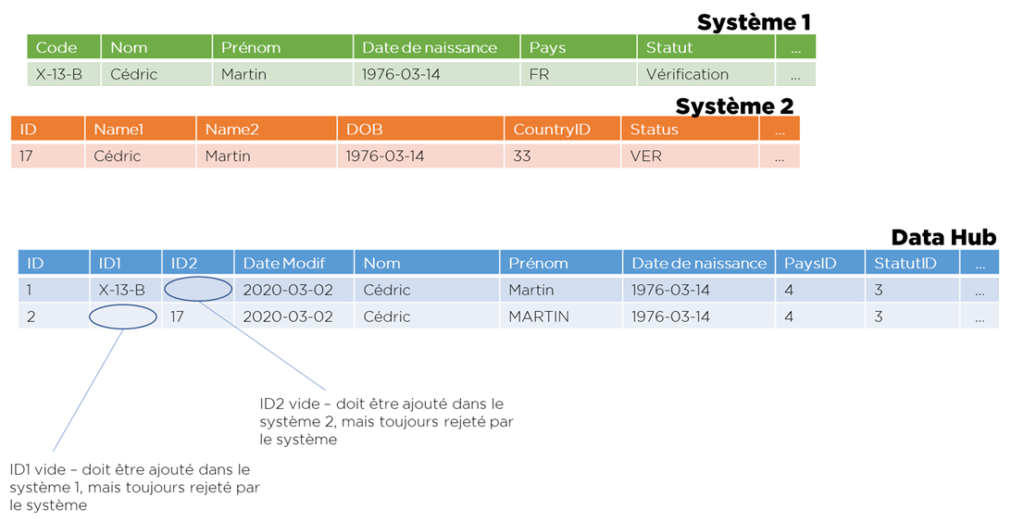
- une clé technique interne à Data Hub, automatiquement générée;
- une date de modification;
- un champ nullable pour chaque système pour stocker les IDs (plus un indexe unique sur chaque champ, nulls non-uniques);
- un timestamp de modification;
- champs de toutes clés étrangères transformées en entier (par la suite transcodifiés vers les IDs de Data Hub);
- les autres champs (dates, varchars, chiffres)…
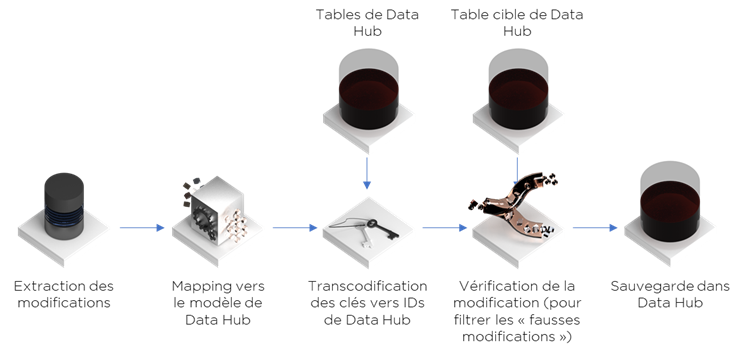
- Créer un flux « direct » vers Data Hub (incrémental) qui récupère les modifications depuis le système et les charge dans notre Data Hub, ce flux doit remplacer les clés étrangères par les identifiants internes de Data Hub, tout erreur de transcodification doit produire un rejet; pas de reprise de rejets – on redémarra le flux avec la même date pour la reprise :
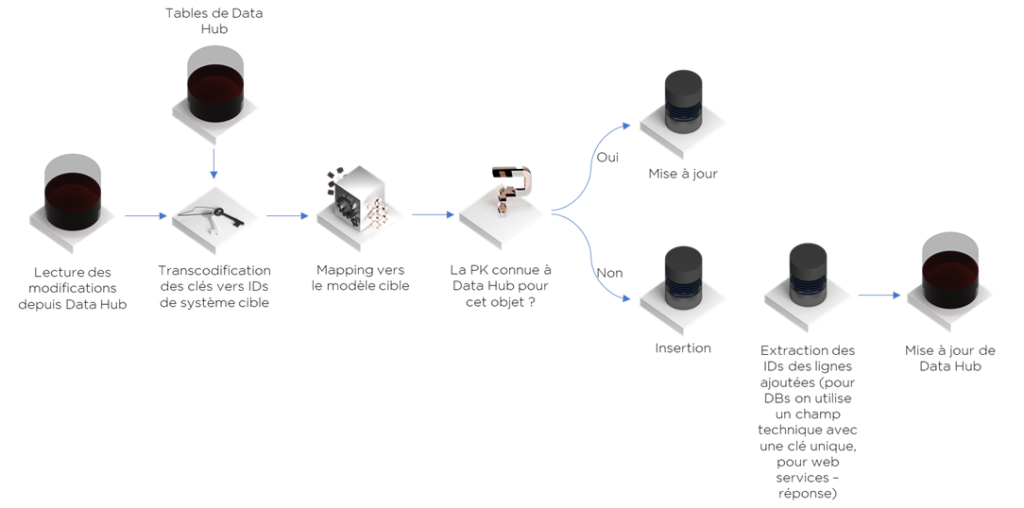
- Créer un flux inverse (attention : rejet d’erreurs) :
- Séquencer les flux, suivant ce modèle :
- Au début – capture de timestamp de début de traitement,
- Exécution de tous les flux depuis le dernier moment connu comme « Ok » en ordre de clés étrangères :
- au début – les flux d’import,
- puis – les flux d’export,
- Si aucun rejet – à la fin on sauvegarde le timestamp capturé au début en tant que « dernier Ok »,
- Si la différence de dates devient importante – envoi d’un e-mail de suivi.
Note. Les optimisations sont possibles : nous pouvons ne pas lancer l’ensemble de traitements (on peut couper la tête des flux, mais pas la base), dans certaines situations on peut lancer les parties de façon asynchrone (à la condition qu’on gère correctement les rejets liés à l’intégrité du référentiel et des données).
Analyse
La partie sensible de ce modèle – mapping « direct » et « inverse » doivent être précisément inverses, sinon Data Hub et les systèmes peuvent commencer un « ping-pong » infini de données.
Sinon, c’est un modèle ultra-simple à mettre en place, à debuguer et à faire évoluer… et oui, on a pu respecter le délai de la livraison, même si cela semble impossible.
Bien sûr, sur ce projet il y eu une surprise… Un jour, le CIO a décidé qu’il faut mettre en place un filtre « contre » les doublons – et il a demandé de créer les indexes uniques sur les systèmes – et cela viole le principe de non-rejet de données… donc une partie de données a commencé se perdre. Pourquoi ? Il y avait des problèmes techniques (firewall ou quelqu’un a changé le mot de passe d’utilisateur technique) – les flux ont été « down », donc entre temps les utilisateurs ont ajouté les mêmes clients dans certains autres systèmes à la main… et cela a donné la situation quand le Data Hub ne pouvait pas mettre à jour les données. La solution est simple – mettre à jour les transcodifications à la main, mais ce n’est pas très joli. De plus, les règles d’unicité des clients ont été différentes entre les systèmes – et cela est devenu récurrent.
Note. Pourquoi ne pas laisser le Data Hub identifier les doublons automatiquement? Il y a plusieurs raisons : (1) ce type de Data Hub n’est pas prêt pour le faire; (2) pour identifier tous les doublons, il faut prévoir également des doublons internes à chaque système, donc mapping many-to-many entre les records de différents systèmes (pas prévu, plus compliqué au niveau des flux), (3) la fonction de rapprochement automatique est en général impossible à servir avec 100% de précision/rappel (les raisons sont décrites ici : https://ithealth.io/rapprochement-de-donnees/), donc pour proposer quelque chose de solide, il faut imaginer les processus de traitement d’erreurs, donc interfaces de Data Stewardship, etc – bien trop compliqué pour un projet « lambda ».
Pour illustrer les difficultés de rapprochement en mode automatique, voici un exercice – essayez de trouver les doublons dans la liste suivante :
Cédric Martin, avec date de naissance 14/03/1976
C. Martin, avec date de naissance 14/03/1976
Caroline Martin, avec date de naissance 14/03/1976
Caroline Martin, avec date de naissance 13/04/1976
Carolin Martin, avec date de naissance 13/04/1976
Caroline Dupont, avec date de naissance 13/04/1976
Quelle est la solution correcte à ce problème de doublons en prenant les conditions du projet ? Eh bien, nous avons vu que c’est compliqué à faire parfaitement, mais au moins on peut ne pas « forcer » les règles via les indexes, mais utiliser une approche plus « soft » en utilisant un moteur de type MDM registre (qu’on a mis en place en forme de PoC) et être aussi « proactif » et même plus « intelligent » en détection de doublons, mais plus « soft » en réalisation.
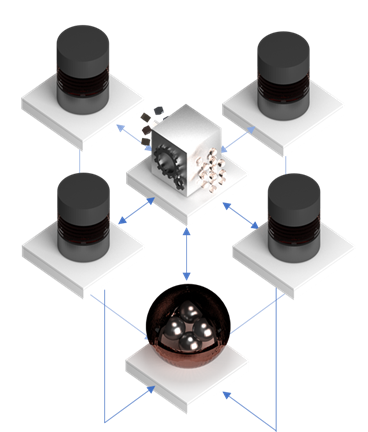
Ici nous avons un hub simple avec en plus des services de recherche de doublons exposés aux systèmes. Chaque système avant de créer les données dans le référentiel peut les chercher via les services web – et si les données existent déjà – rejeter la création ou importer les informations.
Conclusions
L’architecture simplifiée proposée permet d’accomplir l’intégration avec un minimum d’effort, mais nécessite le respect d’un nombre de prérequis.
Morale #0. Un peu de mathématique simple + un peu de chance + modèles de données suffisamment normalisées = intégration rapide et efficace.
Morale #1. Le timing de quelques semaines pour aller en Production n’est pas impossible, mais l’organisation doit être prête pour aller aussi vite et je dois dire que les « Ops » ont été au top aussi bien que notre « lobby » (je n’arrive pas à l’appeler « chef de projet » dans ces circonstances).
Morale #2. Quand le CIO a la main directement sur les spécifications et il contourne les équipes spécialisées – ça peut faire mal. Ça fait encore plus mal s’il n’est pas prêt à accepter ces erreurs.
Bonne santé à vous et à vos systèmes.