
Beaucoup de monde dans le domaine de l’Intégration d’Information utilise le terme Data Hub. Visiblement, les Data Hubs répondent parfaitement aux nombreux besoins – de la BI jusqu’à l’Intégration d’Information. Est-ce vrai ou s’agit d’un nouveau phénomène de mode ? Nous allons tâcher de répondre à cette question dans ce nouvel article.
Tout d’abord, le mot « hub » est une partie de nom du fameux pattern d’architecture « hub and spoke » (i.e. de l’architecture « centralisée » de l’échange de données, où « hub » est la partie centrale qui communique avec les autres systèmes). « Hub and spoke » est le contraire d’intégration « point-to-point » où chaque application « parle » directement avec chaque autre application.

Ainsi, nous pouvons en déduire que le Data Hub n’est qu’un outil qui permet l’échange centralisé des données. Par contre, on va distinguer le moyens de transformation des données et le registre central des données.
- Si nous prenons que la coquille d’échange de données, nous allons obtenir le vieux classique et mature EAI (Entreprise Application Integration).
- Si nous prenons que le « registre » (base de données), il n’a aucune capacité d’intégrer les données « per se ».
- Nous devons parler de couple échange + stockage pour obtenir une solution « intelligente ».

Pour rester assez généraliste dans notre définition de Data Hub, nous n’aborderons pas les définitions « data hub analytique », « data hub d’intégration ». En revanche, nous allons passer par la définition d’interfaces d’échange avec les différentes applications.
Voici un exemple de la classification :
- Par direction :
- Echange uni-directionnel : système soit reçoit, soit envoie les données.
- Echange bi-directionnel : le système « se synchronise » avec le Data Hub et doit en même temps et recevoir et envoyer les données du même type.
- Par vitesse :
- Batch : une fois par heure/jour.
- Mini-batch : une fois par N minutes.
- Temps réel : au moment de la transaction.
- Par complexité d’interaction :
- le système n’est pas conscient de l’existence du Data Hub
- le système est conscient de l’existence du Data Hub et peut demander la validation des transactions à celui-ci. Par exemple, en demandant si les données sont correctes ou bien vérifiant si l’utilisateur ne créé pas un doublon.
Il faut se dire que certaines configurations sont plus risquées que d’autres, par exemple :
- Data Hub bi-directionnel avec un échange en batch est extrêmement risqué. En effet, durant la période, on peut se retrouver avec une accumulation de modifications. Plusieurs systèmes peuvent modifier l’objet de telle manière qu’il ne sera plus synchronisable. Pour exemple, un système A passe le client en état « actif » quand le système B le positionne en « archivé » sans possibilité de revenir en arrière. Ou encore, deux systèmes modifient l’adresse du même client. Le Data Hub doit absolument gérer le conflit.
Conclusion : l’échange bi-directionnel doit fonctionner en temps réel (ou en mini-batches au minimum). - Le Data Hub lorsqu’il reçoit les mêmes objets depuis un système A en temps réel et depuis le système B en batch, il risque de prioriser les données qui arrivent en batch et donc d’écraser les données arrivant en temps réel.
- Le Data Hub en temps réel qui ne reprend jamais les données risque de perdre une partie d’information.
Conclusion : afin de diminuer l’impact de données perdues (à cause d’erreurs de programmes, coupures, etc), le Data Hub en temps réel doit, visiblement, avoir une procédure de re-synchronisation. - Si les systèmes qui reçoivent les données depuis le Data Hub font une validation profonde des données (plus profonde que celle de Data Hub), il y a un risque très important de perte de données.
Exemples :
- Un éditeur très connu propose à ses clients de ré-intégrer les résultats de la consolidation (batch) des données dans les systèmes-producteurs de données. Les clients refusent, l’éditeur ne comprend pas pourquoi.
Raison : les clients font très attention à ces données et comprennent que l’échange bi-directionnel en batch est risqué. - Une société qui a mis en place un Data Hub perd régulièrement les mises à jour dans les systèmes.
Raison : via la décision du DSI, chaque système vérifie que la donnée entrante ne crée pas de « doublon » avec une autre donnée dans ce même système. Vu que cette fonction est exécutée (mal) par le SI et pas du tout par le Data Hub, il se peut qu’une partie des données ne peuvent pas entrer dans certains systèmes, alors qu’elles existent dans les autres.
Maintenant, vous pouvez constater que les choix d’architecture sont multiples et vous avez un aperçu des difficultés attendues dans un projet de création d’un Data Hub.
Je vous propose de considérer quelques exemples :
- Hub de consolidation
- Hub basique de synchronisation
- Hub intelligent de synchronisation
Hub de consolidation
Supposons que tous les systèmes branchés sur une certaine structure de votre hub se divisent en deux parties :
- producteurs de données, ils produisent uniquement de l’information, aucune consommation depuis la structure.
- consommateurs de données, ils consomment les données, sans pouvoir de modification.
Dans ce cas, votre hub ne propose aucun service pour les producteurs (sauf retours concernant l’état de qualité de données), mais peut proposer les meilleures données aux consommateurs.
Ce patern est très connu sous plusieurs appelations dans différents domaines :
- BI : Corporate Information Factory (CIF, ODS Inmonien),
- MDM : MDM de consolidation.
Cette configuration est à priori non-risquée car vos producteurs vont toujours garder la main sur les données, donc vous ne perdez jamais les données à cause du Data Hub. Les erreurs dans celui-ci impacteront seulement les systèmes cibles et c’est à cet endroit précis que le risque existe. Si vous le maîtrisez – vous pouvez lire nos articles pour avoir plus de détails (sachant que par définition, vous allez créer un ODS) :
- Anatomie d’un entrepôt de données : https://ithealth.io/anatomie-dun-entrepot-de-donnees-efficient/
- Rapprochement de données : https://ithealth.io/rapprochement-de-donnees/
Conclusion : cette architecture est relativement facile à mettre en place, mais n’offre pas toutes les garanties dont nous avons besoin, notamment la synchronisation de tous les systèmes.
Hub basique de synchronisation
Hub de synchronisation par définition doit permettre l’échange bi-directionnel entre les applications. La version la plus simple d’un tel outil permet de garder les systèmes synchronisées, mais ne garantit pas la qualité des données.
Les conditions de mise en place d’un « hub basique » :
- toute nomenclature (pays, statuts, marques, etc) doit avoir une correspondance une-à-une entre vos systèmes, i.e. vous devez pouvoir faire une conversion de format d’un système à l’autre et à l’inverse sans perte d’information.
- les données synchronisées bi-directionellement doivent avoir un format de données compatible.
Si les modifications dans les systèmes sont lentes (i.e. si il y a une probabilité très petite de modification simultanée de même donnée), vous pouvez utiliser la méthode ultra-simple :
- Il faut créer un modèle « universel » de données (vos formats sont compatibles).
- Chaque table de ce modèle doit contenir une clé primaire en forme d’ID généré automatiquement par le Data Hub.
- Toutes références entre les tables doivent passer par ces IDs (et non par les IDs des systèmes).
- A côté de ces IDs, il y aura également l’information concernant les IDs des systèmes participants à l’échange. Si l’ID n’est pas rempli pour l’un des systèmes, ce système devra insérer l’objet en question et rendre l’ID dans la table.
- Chaque flux de chaque système viendra mettre à jour les données et récupérer les information dont il a besoin.
- Chaque mise à jour doit aussi modifier la date de modification des données qui sert aux flux pour retrouver les modifications.
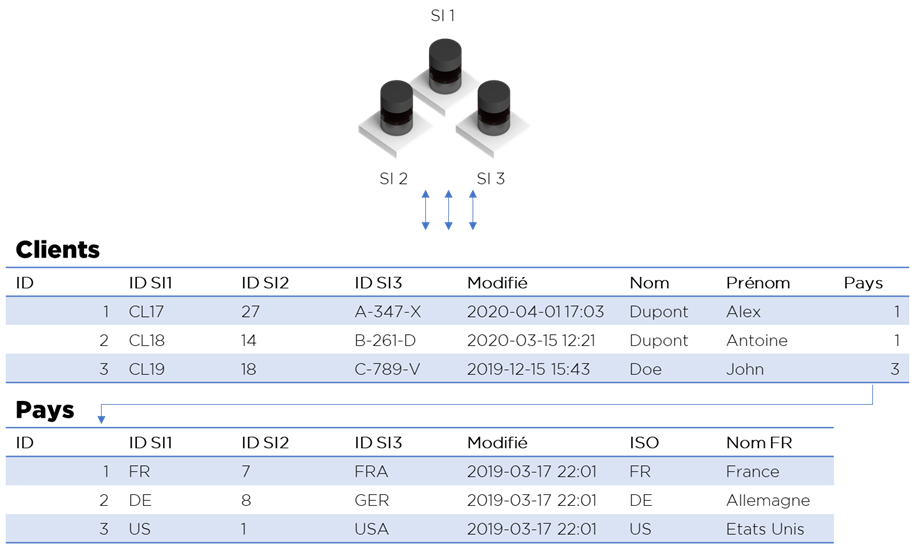
Cependant, cette approche facile à mettre en place ne garantit pas :
- la qualité de données – chaque système est libre d’envoyer n’importe quelle donnée.
- la synchronisation, si certains systèmes rejettent les données des autres.
- la résolution des conflits si il y en a (surtout si vos flux ne fonctionnent pas durant un certain temps).
Conclusion : cette architecture est relativement facile à mettre en place ne donne pas toutes garanties dont nous avons besoin, notamment la qualité de données.
Hub intelligent de synchronisation
Si nous voulons pouvoir traiter les erreurs potentiels dans les données, nous ne pouvons pas juste créer des règles dans les systèmes qui participent à l’échange.
Pour illustrer cela, voici un exemple : durant le période d’indisponibilité du Data Hub, on décide de saisir le même client dans deux systèmes, puis on lance la synchronisation. Malheureusement, l’enregistrement du système A ne peut pas être créé dans le système B, ni l’enregistrement du système B – dans le système A. « Deadlock ».
Dans ce cas, il faut que ce soit le Data Hub qui exécute la logique de rapprochement des données. Vous le savez probablement, le rapprochement de données est probabiliste et voici quelques cas potentiels :
- Le rapprochement relie automatiquement les doublons (OK).
- Le rapprochement n’arrive pas à identifier le doublon (faux négatif).
- Le rapprochement identifie deux lignes comme étant un doublon alors que ce n’est en réalité pas le cas (faux positif).
- Le rapprochement « hésite » entre les deux dernières décisions ci-dessus.
Dans ce cas, vous ne pouvez pas créer un système de rapprochement 100% automatique. C’est juste impossible.
Que pouvons-nous faire pour notre Data Hub ? Nous pouvons ajouter les processus complexes de gestion de différents cas, mais il reste préférable que le Data Hub devienne « proactif ». I.e. durant la création d’objets synchronisés de façon bidirectionnel, le système doit demander au Data Hub s’il est « OK » pour réaliser cette transaction. Le Data Hub doit pouvoir remonter les doublons potentiels (s’il y en a) à l’utilisateur du système. De la même manière, il peut également remonter d’autres types d’erreurs.
Cela doit fonctionner pour les objets de référentiel, mais aussi pour d’autres objets qu’on ne considère pas comme Master Data, notamment factures, nomenclature des pays, différents statuts, etc. Dans ce cas, quand le Data Hub s’occupe de prévenir les erreurs (mieux vaut prévenir que guérir comme le dit parfaitement l’adage), tout deviens plus facile ! En revanche, tous vos systèmes doivent pouvoir se connecter aiu Data Hub et vérifier ses actions via ses services – l’impact sur vos systèmes n’est pas négligeable. En plus, tout Data Hub intelligent doit pouvoir traiter quand même les erreurs qui parviennent à passer par toutes vérifications.
Conclusion : cette architecture peut tenir toutes les promesses du « hype » autour du Data Hub, mais au vu de la complexité d’approche, il est peu probable qu’il soit déployé à grande échelle.
Quelques réflexions & conclusions
Contrairement à la « hype » actuel, je ne pense pas que les Data Hubs plus ou moins intelligent vont se généraliser. En cause, la complexité de la mise en place. Certes, c’est une approche intéressante, mais pour la rendre aussi flexible que souhaitée, il faudra travailler très dur.
Par contre, les solutions de consolidation ou de synchronisation basique sont relativement faciles à mettre en place, mais nous devrons oublier la partie « intelligente » ou « bidirectionnelle » de l’approche.
Nous n’avons pas considéré les Data Lakes car ce sont des concepts différents. Et vous, connaissez-vous une architecture qui permet de résoudre les problèmes avec les Data Hubs ? Ecrivez-nous !
Bonne santé à vous et à vos systèmes !
Pingback: Video des petits experts : Master-Slave & Data Hubs – Ordre d'informaticiens