
One ring to rule them all, one ring to find them, One ring to bring them all and in the darkness bind them.
J. R. R. Tolkien
Depuis quelques temps, le monde du Master Data Management est obsédé par l’idée du MDM multi-domaine. Ce concept est si alléchant que les analystes du marché ont cessé de produire des rapports pour les différents domaines du MDM en faveur de rapports « complets » présentant les différentes solutions comme « comparables » et bein « plus fortes » ou « moins fortes ».
Le concept est donc repris par les éditeurs eux même et c’est désormais rare d’entendre « MDM pour les produits » ou « MDM Registre », désormais, vous entendez « MDM super puissant et adaptatif ».
Styles
Le Master Data Management peut être implémenté différemment suivant les conditions propre à votre projet, par exemple :
- vous avez des systèmes hétérogènes utilisés par des nombreux départements, mais vous voulez proposer un seul point d’entrée pour la modification et la validation de données ~ style collaboratif;
- vous avez des groupes d’utilisateurs qui doivent pouvoir gérer les données indépendamment, mais votre projet cherche une visibilité cross-système tout en diminuant la quantité de doublons ~ style registre;
- vous avez des « producteurs » de données et vous n’avez pas moyen de modifier leurs processus fonctionnels ni faire les ajustements dans ces systèmes, la seule chose que vous voulez c’est de recycler les données existantes pour les fournir aux systèmes-consommateurs ~ style consolidation;
- vous pouvez modifier les systèmes existants, mais pas les interfaces et la logique de fonctionnement, pourtant vous voulez construire un outil qui pourra les synchroniser ~ hub transactionnel.
En plus de ces approches classiques, il existe des options plus avancées :
- vous construisez l’architecture « from scratch » à la base de « microservices », donc vous auriez probablement besoin de microservice intelligent Master Data, mais le fonctionnement exact de ce microservice sera « plutôt collaboratif » ou « plutôt consolidation » et dépendra de conditions supplémentaires;
- vous passez à la solution ERP commune à l’ensemble d’utilisateurs, mais vous voulez la renforcer pour diminuer le nombre d’erreurs.
J’espère que vous voyez les différentes possibilités et imaginez qu’elles ne sont pas très compatibles entre elles pour être toutes réalisées dans le même outil. Il reste encore un autre point que l’on doit aborder : « est-ce que chaque style de MDM est capable de s’appliquer à tout type de données? ».
Pour argumenter il nous faut un exemple. Prenons un réseau de distribution qui dispose d’un site e-commerce et de plusieurs magasins. Il est fort probable que la gestion des fournisseurs et des produits sera centralisée au niveau HQ. Pourtant nous aurons probablement la Master Data importante non centralisée – la gestion des clients (sous forme de carte de fidélité, etc.). Dans cette situation, il y aura deux approches différentes au niveau de l’architecture de ces deux briques – « collaborative » pour les produits (et probablement fournisseurs) et « consolidation » pour les clients.
Vision technique
Cela étant dit, j’espère que vous êtes désormais convaincus qu’il existe une différence entre les styles. De ce fait, pourquoi je pense qu’il est peu probable qu’un seul et unique outil fera correctement le travail pour tous les styles ?
Pour être plus clair, je vous propose d’analyser chaque style…
Style collaboratif
Le style collaboratif se caractérise par une gestion des référentiels via une seule IHM et la distribution des résultats de saisie à l’ensemble de systèmes. En général, chaque système rétrocède le droit de modifier ses données à un seul système. Le MDM Collaboratif est donc un « single source of truth ».
Cette approche s’applique parfaitement bien à la gestion de l’information concernant les produits (PIM, Product Information Management), mais techniquement, il est applicable à tous les référentiels.
Voici le schéma de fonctionnement :
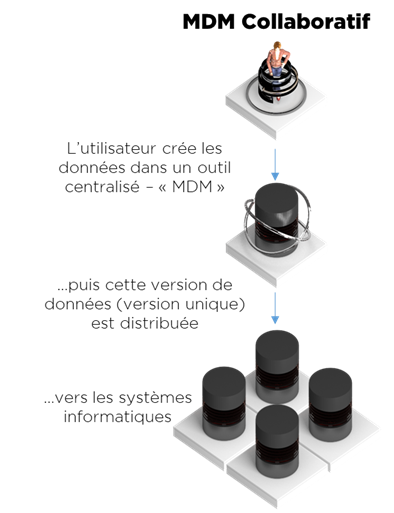
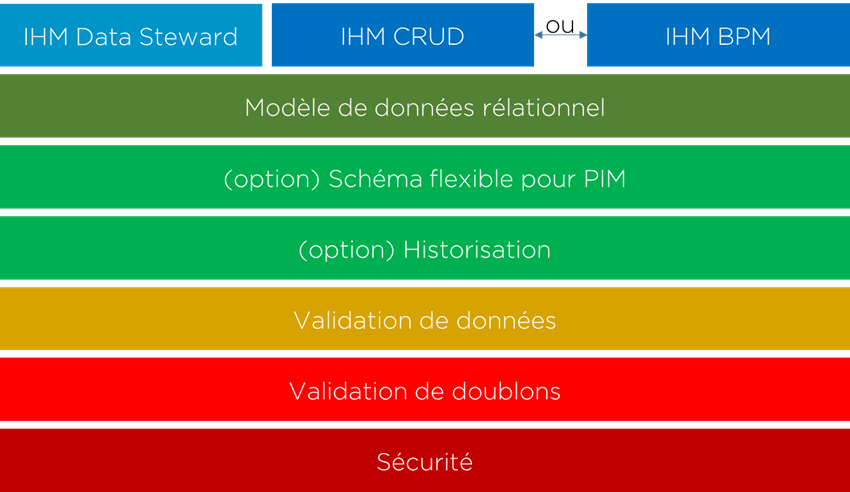
Afin de faire fonctionner ce système, l’outil MDM collaboratif doit proposer les modules suivants :
- IHM Data Steward – pour la résolution des problèmes sur la qualité de données et la gestion des tâches de validation;
- Soit IHM classique de Create/Read/Update/Delete pour la modification de référentiel, soit BPM (Business Process Management) pour les cas plus avancés (où la gestion des données doit être plus stricte);
- Modèle de données (relationnel) pour les référentiels classiques;
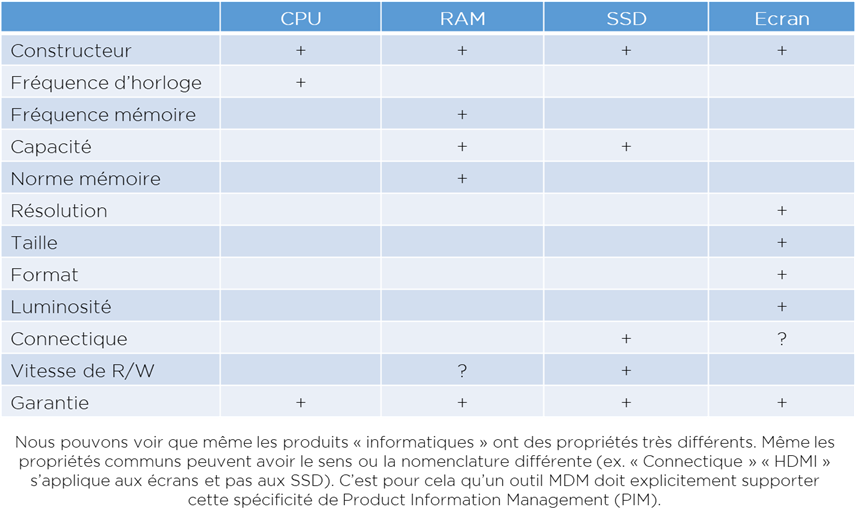
- Modèle plus flexible pour les référentiels produits car le modèle relationnel n’est pas suffisant pour la gestion de ce type de données : les propriétés des produits dépendent de types de produits, donc les outils PIM permettent en général la gestion du nombre de paramètres en condition de type de produit (voir le schéma);
- En option – l’historisation des modifications;
- Validation de données saisies (type, format, nomenclature, etc);
- Validation de doublons (option que je n’ai pas vu dans beaucoup de systèmes de ce class) – pour limiter le nombre de doublons qui ensuite « glissent » dans le référentiel et seront donc distribués à l’ensemble des systèmes;
- Sécurité avancé pour distinguer les droits d’utilisateurs en fonction de cycle de vie de données.
Style registre
Le style registre s’applique notamment dans les situations où il n’est pas possible d’utiliser les autres styles – pour le rapprochement de systèmes gérés par les équipes très différentes qui ne peuvent pas mettre en place le référentiel unique ou dans les situations où la distribution de données n’est pas possible (ex. données personnelles).
Si nous appliquons le style registre, les systèmes existants restent toujours indépendants, aucune donnée n’est distribuée aux autres systèmes, mais les systèmes obtiennent la possibilité de consulter (à la demande) un registre centralisé afin d’y trouver les données dont ils ont besoin. Le registre est donc un « microservice » intelligent de rapprochement et de recherche de données en temps réel.
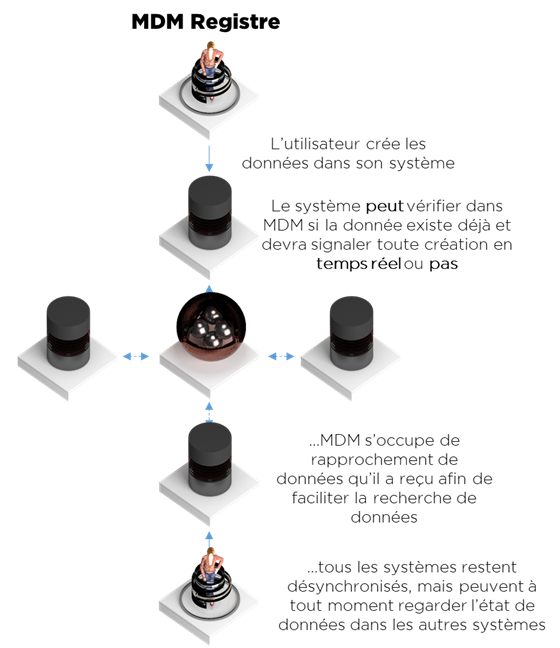
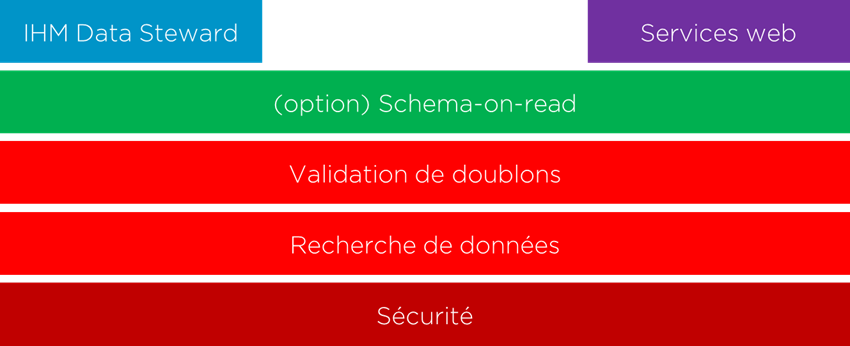
Voici les modules nécessaires pour cette solution :
- Les services web pour l’interaction avec les systèmes existants;
- IHM Data Steward pour la gestion des doublons;
- Le schéma de données peut être fixe ou fonctionner en mode « schéma-on-read » (afin de permettre l’ajout d’informations supplémentaires, spécifiques à chaque système – cela permet d’éviter une partie de problèmes du schéma universel);
- La validation des doublons en temps réel (rapprochement de données);
- Recherche de données;
- Les règles de sécurité afin de limiter l’accès aux données sensibles si nécessaire.
Style consolidation
Style consolidation, parfois aussi appelé « style BI » s’applique dans les situations où nous pouvons distinguer deux types de systèmes : les systèmes-producteurs et les systèmes-consommateurs. À noter que ce style (contrairement aux deux précédents) n’améliore pas directement la qualité de données dans les systèmes-producteurs car son but c’est de proposer des données qualifiées aux systèmes-consommateurs. (Note : MDM Registre en mode proactif permet de diminuer la quantité de doublons.)
Ainsi, le MDM s’approvisionne de données dans les systèmes-producteurs (upstream), traite ces données et ensuite distribue la « golden record » (ou « single version of truth ») aux systèmes-consommateurs (downstream).

Pour aller plus loin, nous avons évoqué le schéma de fonctionnement dit de consolidation ici : https://ithealth.io/anatomie-dun-entrepot-de-donnees-efficient/.
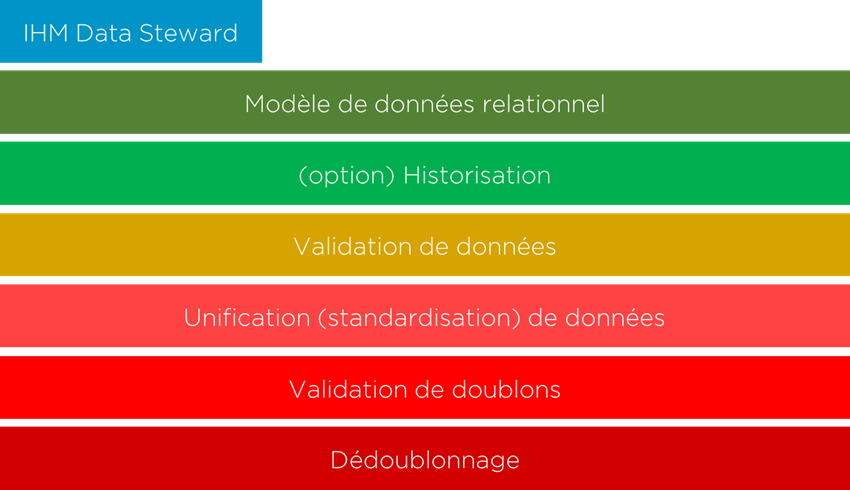
L’outil MDM de ce style doit avoir les modules suivants (à noter que la consolidation fonctionne souvent en « batch » et non en « temps réel ». D’un point de vue purement technique, les services web ne sont pas obligatoires).
- Afin que le système fonctionne correctement, il doit être surveillé par des Data Stewards (d’où l’IHM technique destiné aux DS), mais contrairement au MDM registre, l’interface ne sert pas seulement à valider le rapprochement, mais aussi pour « corriger » (« surcharger ») les résultats de dédoublonnage;
- Modèle de données relationnel;
- En option, nous pouvons historiser les données consolidées afin d’avoir la traçabilité des modifications effectuées, mais cela reste une option;
- La validation des données est utile afin de choisir la version des données la plus pertinente;
- L’unification/standardisation est nécessaire afin d’obtenir une structure homogène de l’information;
- La validation/identification des doublons est un module nécessaire, mais contrairement au MDM Registre, il peut fonctionner « en batch »;
- Le dédoublonnage (choix de la meilleure version des données) est l’une des dernières étapes qui se base sur les règles de gestion afin de proposer (automatiquement) une seule version des données à partir de plusieurs doublons identifiés;
- Nous n’abordons pas la sécurité car elle ne joue pas un rôle aussi important que pour les autres styles même si elle doit être présente au moins pour l’authentification des Data Stewards.
Style transactionnel
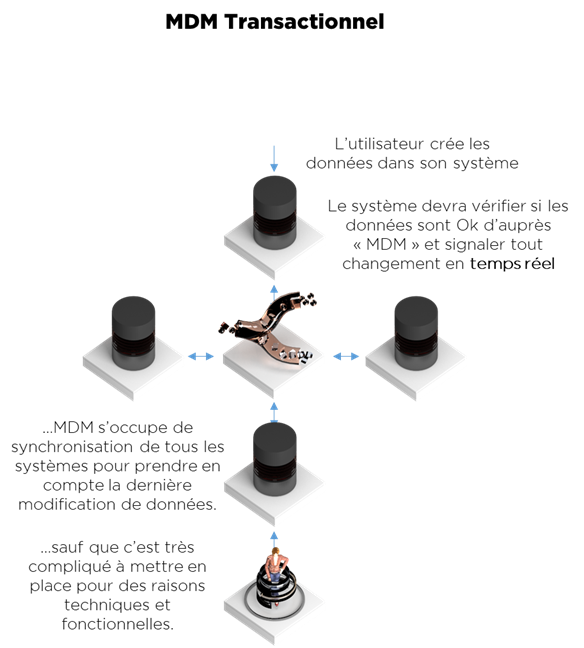
Le style transactionnel de MDM est l’un des plus complexes à mettre en place, c’est pour cela qu’il est rarement appliqué en pratique. L’idée d’un hub transactionnel c’est de synchroniser les SI en temps réel (comme le Data Hub) en appliquant les règles de validation, de sécurité, d’identification de doublons au moment de l’éxécution de la transaction dans chaque système.
Dans le cas où nous voulons garder les SI indépendants en terme d’utilisation de données, mais nous voulons les synchroniser, ces systèmes doivent obligatoirement consulter le hub avant de sauvegarder les données. De plus, le hub doit être en capacité de transmettre toute modification à chaque système. Cela nécessite la modification de tous les systèmes qui participent à l’échange.
Le Master Data a la spécificité de fonctionner avec des règles strictes (sécurité, validation, etc) qui doivent absolument être respectées pour un bon fonctionnement. Dès lors, on ne peut considérer le MDM transactionnel comme un Data Hub de Synchronisation « basique ».
Voici le schéma de fonctionnement (tout échange est bidirectionnel) :
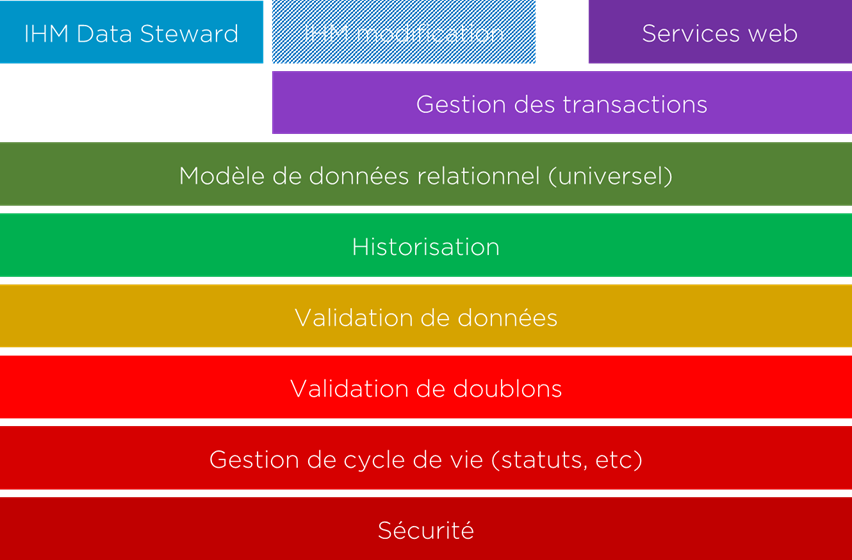
Afin que cette approche fonctionne, l’outil doit proposer un nombre de modules :
- IHM Data Steward (gestion des doublons, correction des doublons, division des faux positifs – cela devient beaucoup plus compliqué pour ce style);
- IHM modification – optionnel, mais utile dans le cas où nous mélangeons l’approche transactionnelle et collaborative;
- Services Web et la gestion des transactions – des modules importants et complexes car ce sont les « portes » d’échange de la solution avec toute application cible pour la validation et la mise à jour des données via les transactions simples ou composées;
- Modèle de données relationnel, universel pour tous les systèmes;
- Historisation – module obligatoire pour permettre la division de données en cas de faux positifs;
- Module de validation;
- Le module de gestion du cycle de vie qui est lié à la gestion de sécurité car il permettra décider si chaque utilisateur/système a le droit de modifier les données à chaque instant;
- La sécurité (complexe) afin de valider le droit de chaque utilisateur à chaque instant de modifier l’ensemble de données ou certains paramètres liés à ces données;
- Nous n’avons pas noté le module de dédoublonnage car pour ce style il faut que le dédoublonnage soit « manuel », donc il fera partie de l’IHM de Data Steward.
Nous pouvons constater que ce style est complexe et pas seulement à cause de sujets techniques, mais aussi à cause de fait que la gestion d’accès sera aussi complexe que les processus fonctionnels et la tension « politique » entre les équipes qui vont brancher ces systèmes au MDM.
Comparaison
Je ne vais pas comparer la disponibilité des différents modules de chaque style. De toute façon, même les modules pour lesquels nous avons utilisé la même définition ne contiennent pas les mêmes fonctionnalités.
Vous pouvez voir, par contre, que seulement deux fonctionnalités sont communes à l’ensemble des approches : recherche/validation/identification des doublons et l’IHM de Data Steward pour la validation. Toutes les autres parties nécessaires pour les différents styles, même les modèles de données sont différents.
De plus, certains styles ne se combinent pas correctement. Par exemple, la combinaison des styles consolidation et collaboratif pour les mêmes données peut provoquer la perte de données.
Conclusion
Désormais, vous comprenez pourquoi, selon nous, les offres de MDM « universels » nous semblent peu pertinentes. Cela est confirmé par une autre observation : le marché est souvent remporté par des outils incomplets grâce à leur simplicité de mise en place (je ne vais pas citer d’exemples, mais si vous faites la comparaison avec la liste de modules nécessaires, vous allez pouvoir identifier ces outils vous-mêmes).
Avec la maturité croissante du marché, on peut qu’espérer voir de plus en plus d’outils complets ou d’approches différentes car le meilleur MDM c’est probablement l’absence de MDM.
Bonne santé à vous et à vos systèmes !
Pingback: La gestion des données RH – Ordre d'informaticiens
Pingback: La gestion de référentiels pour la finance – Ordre d'informaticiens