
Il était une fois un chef de projet qui réalisait un projet majeur pour une grande société internationale de crédit-bail. J’ai été invité en tant qu’expert BI et MDM/Data Quality pour répondre aux questions sur l’utilisation de systèmes spécialisés au sein du projet.
Le chef de projet m’a posé une question qui m’a interloqué au début : « pour ce nouveau projet devons-nous utiliser un outil MDM/DQ ou non et si oui – quand commencer ».
Les éditeurs d’outils de Data Quality vont répondront toujours que la BI sans DQ est impossible, mais e voulais comprendre le raisonnement derrière cette question.
Du point de vue de ce chef de projet :
- les outils de Data Quality vont diminuer son budget (achat ou dev d’outil) et augmenter les charges,
- il a besoin de spécifier des processus complexes de nettoyage et de rapprochement de données,
- alors que les utilisateurs attendent les rapports – et vite.

Vous pouvez facilement comprendre l’hésitation de ce chef de projet. Pour répondre bien à cette question, il nous faut comprendre 2 choses :
- quel ROI clair la société peut-elle tirer de l’usage de la DQ/MDM dans la BI (étant donné qu’il n’existe pas encore de projet MDM au sein de ladite société),
- quand nous pouvons introduire cette fonctionnalité (étant donné que la première vague du projet aura probablement d’autres priorités).
ROI
Le ROI le plus évident pour la société de crédit-bail c’est de gérer les risques de non-paiement, de dépassement de credit limit, de gestion de fraude potentielle et enfin, suivre un CRM multicanal.
Bref, ce que le chef de projet doit garantir c’est la qualité de la dimension « client » qui participe dans plus de 90% d’analyses. Pour être au plus précis, ce qui compte finalement c’est de pouvoir identifier les doublons – les petits erreurs dans les champs ne feront pas beaucoup de différence, mais si nous avons beaucoup des doublons dans la dimension client – c’est une catastrophe.
Pourquoi on en parle encore en 2020
La stratégie classique de la BI c’est d’utiliser l’approche suivante :
- choisir une clé fonctionnelle, i.e. ce qui doit être « unique » pour déterminer un objet, par exemple :
- pour personne : nom+prénom+date de naissance,
- pour société : code TVA ou SIREN,
- pour établissement de la société : SIRET,
- pour un contrat : code de contrat;
- pour facture – ID société, code facture et mois;
- etc…
- créer un index unique sur la clé choisie;
- « standardiser » les données pour enlever le bruit de formatage (supprimer les espaces en double, mettre en majuscule, enlever les accents, remplacer les mots, etc);
- croiser les doigts en espérant que les données ne contiennent pas trop de fautes de frappe.

Il est probable que la majorité de données sera bien traitée, mais il y aura forcément des doublons qui vont s’infiltrer dans les dimensions si on applique un algorithme aussi basique (prenez juste une faute de frappe dans le prénom), mais encore pire – certaines sources ne seront pas « intégrables » à cause de manque de données dans les champs de la clé.
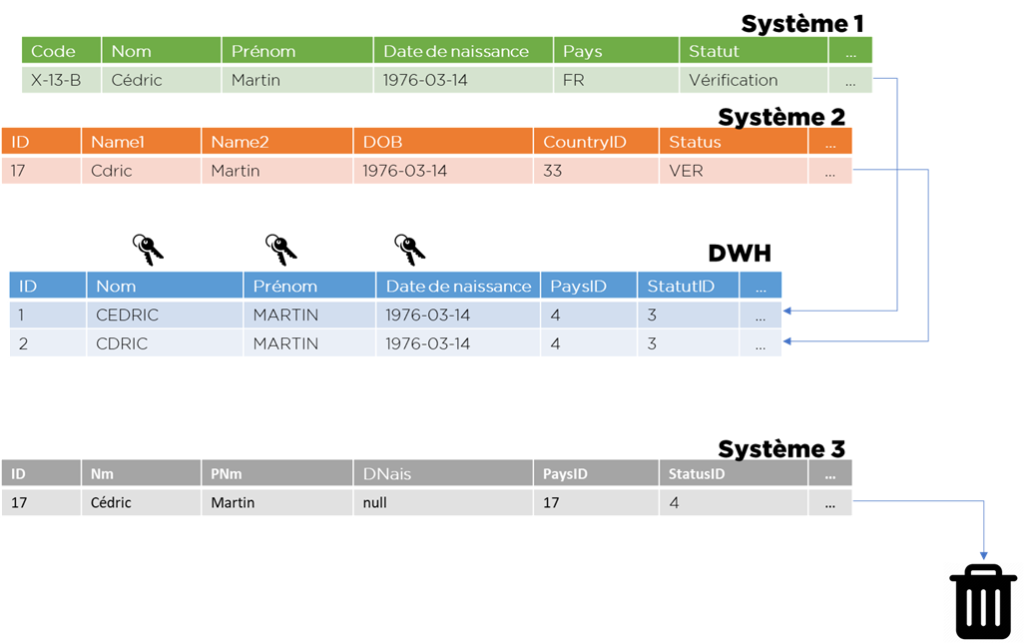
Il ne faut pas oublier que pour toute table de fait (ou toute dimension de niveau « plus haut » dans le flocon il faudra prévoir la transcodification d’IDs de systèmes source vers les IDs de l’entrepôt et pour cela on utilise l’algorithme suivant :
- pour chaque table remplacer les IDs techniques par les clés fonctionnelles;
- chercher les clés fonctionnelles dans les dimensions pour obtenir les IDs techniques internes au DWH.
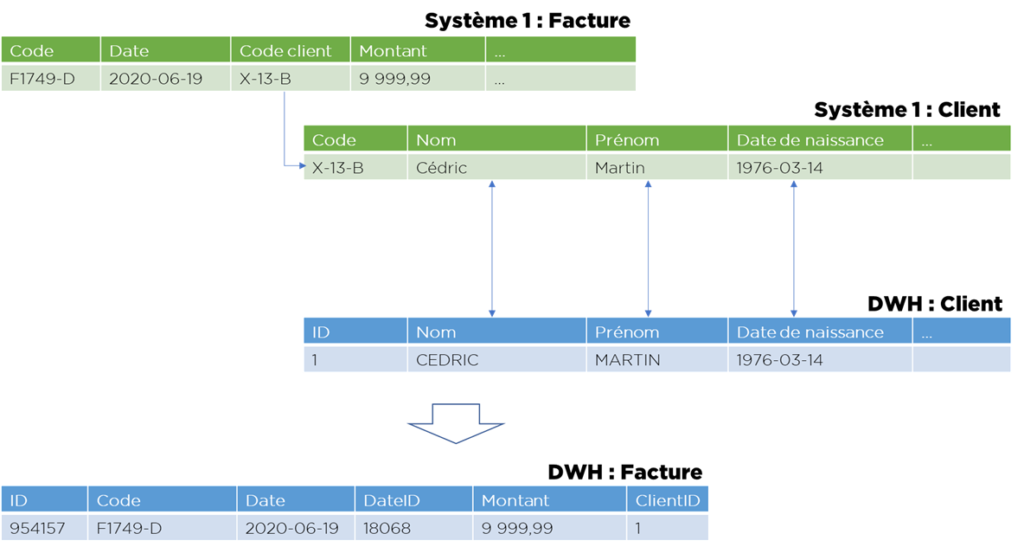
Cet ensemble de règles est facile à implémenter, mais je vais vous prouver qu’il est généralement incorrect et voici pourquoi :
- quand on utilise la clé fonctionnelle on mélange 2 sujets : stockage de données et identification de doublons (indexe unique);
- quand on cherche les IDs techniques de DWH dans la table de dimension par une clé fonctionnelle, on mélange 2 sujets : stockage de données et la transcodification.
Tout informaticien connait les conséquences de violation de SoC (Separation of Concerns, en francais : SdP, https://fr.wikipedia.org/wiki/S%C3%A9paration_des_pr%C3%A9occupations). Pour des raisons de simplicité, par contre, nous avons l’habitude d’ignorer ce fait en BI.
Imaginons la situation suivante : vous devez changer l’algorithme de rapprochement, par exemple, vous devez modifier votre clé fonctionnelle … Dans ce cas, vous allez devoir ajuster pas seulement le flux de chargement de la dimension, mais également tous les flux de chargement des faits qui utilisent cette dimension !
Comment faire, donc
Il existe un certain nombre de solutions à ce problème, mais tout revient à séparer les responsabilités, notamment stocker la transcodification séparément avec les données rapprochées :

Maintenant, nous pouvons séparer les traitements :
- Le traitement de chargement de dimension client peut être divisé en parties :
- Préparation de données (génère les données « normalisées » à partir de différentes sources, i.e. format « Pivot »),
- Rapprochement de données (utilise les données « Pivot » et les données de la dimension et génère la table de transco),
- Flux de dédoublonnage et de chargement (utilise les données « Pivot » et la table de transco et génère la table finale).
- Les traitements de chargement des tables de faits utilisent juste la table transco de la dimension et ne connaissent rien de l’algorithme qui l’avait généré.
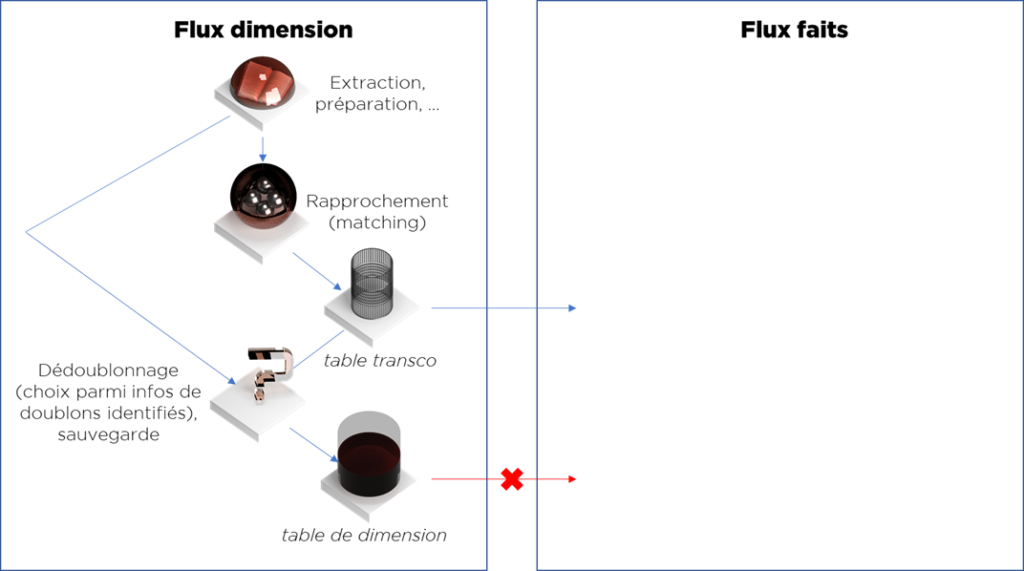
Ce flux a été décrit en détail dans notre l’article suivant : https://ithealth.io/anatomie-dun-entrepot-de-donnees-efficient/
Si nous n’avons pas les moyens pour mettre en place un rapprochement intelligent, nous pouvons utiliser les clés fonctionnelles, mais nous ne devons pas afficher cette information aux autres flux – les autres flux doivent juste consommer la table de transcodification et ne pas se baser sur les hypothèses d’algorithme de rapprochement.
Qu’est-ce que cela nous donne ?
- Nous pouvons remplacer un algorithme de rapprochement par un autre à tout moment (clé fonctionnelle -> modèle statistique -> import depuis un outil MDM),
- Nous pouvons stocker les données dans un format qu’on veut (pas d’obligation de mettre dans la dimension une clé formatée de même manière),
- Nous avons gratuitement une traçabilité de rapprochement (via transco).
Maintenant nous pouvons répondre à l’une des questions de ce chef de projet : si les flux sont bien structurés, nous pouvons changer l’avis concernant l’approche de rapprochement/dédoublonnage à tout moment. Par contre, si on décide de simplifier les flux, on aura tout à refaire plus tard.
Comment estimer l’ampleur de problème : revenons vers le ROI
Et si nous avons très peu de doublons – nous n’avons pas besoin d’aller dans ces détails, n’est pas ?
Voici une méthode facile que vous pouvez appliquer pour estimer l’ordre de la quantité de doublons (sur un exemple de dimension clients) :
- prenez toutes données disponibles actuellement (mélangez les données de tous les systèmes disponibles – ça sera votre base de travail/audit),
- prenez par hasard 100-200 lignes,
- pour chaque ligne cherchez les doublons manuellement dans l’ensemble de la base (par nom, par téléphone, par nom de la rue, etc) et notez les doublons trouvés,
- analysez :
- le pourcentage de doublons,
- la complexité de doublons (si vous pouvez « corriger » automatiquement les différences entre les lignes avec un algorithme de standardisation).
Dans notre cas, j’ai pris à peu près 200 lignes et j’ai retrouvé autour de 50 doublons, donc nous avons un taux de 50/(200+50) = 20%. Parmi ces 50 doublons il y avait ~10 assez complexes (10/210 = 4,8%).
Conclusion : si nous ne faisons rien, nous aurons probablement 20% de doublons et si on utilise juste la clé fonctionnelle, dans la dimension finale il y aura certainement autour de 4-5% de doublons.
Ce sont les faits avec lesquels nous pouvons adresser le métier afin de vérifier si c’est un niveau de qualité acceptable (spoiler : c’est une catastrophe à long terme car cela veut dire qu’on ne gère pas correctement 5% de la masse de prêts).
Pourquoi du coup un MDM ou un outil DQ
Assez certainement, les débutants en rapprochement de données ont pour première idée d’implémenter un algorithme de Levenshtein … Mais le rapprochement de données fait bien est beaucoup plus complexe.
L’auteur de cet article vous déconseille d’essayer de le faire vous-même sauf si vous avez vraiment bien étudié le sujet (dans ce cas n’oubliez pas l’interface de data stewardship).
Pour plus de détails vous pouvez lire notre article : https://ithealth.io/rapprochement-de-donnees/.
Conclusions
- Kimball se trompe.
- Parfois un expert implémente plusieurs flux là où un débutant en ferait un seul – et l’expert a raison.
- La structure de flux est aussi l’architecture.
- Si vous êtes du bon côté de la force vous mettrez en place une solution modulaire avec la liberté d’utiliser une approche itérative. Sinon – un jour, vous en paierez le prix !
Bonne santé à vous et à vos systèmes !