
Aujourd’hui, nous allons aborder des questions d’ordre fonctionnel sur le domaine RH. Cet article s’adresse avant tout aux responsables de SI RH ainsi qu’aux décideurs RH (directeur, responsable, etc.), mais si vous gérez des données de tiers/personne, cet article peut aussi vous intéresser.
Pour rappel, l’état d’esprit d’IT Health est d’encourager la collaboration et la participation de chacun. Dès lors, si vous avez des remarques/suggestions pour corriger/compléter nos propos, envoyez-nous un message via le formulaire « Contactez-nous » ou bien laissez-nous un commentaire sur LinkedIn.
Pour le Master Data Management au niveau de RH, deux sujets majeurs émergent :
- la gestion de l’information personnelle des collaborateurs;
- la gestion d’un référentiel de compétences (spécialement important pour les sociétés de services).
Information personnelle
En termes de gestion de l’information personnelle, la partie probablement la plus importante c’est l’identification des collaborateurs, mutation/changement de poste/de branche, etc. Dans le domaine RH, on utilise le mot « immatriculation » pour ce type de tâche.
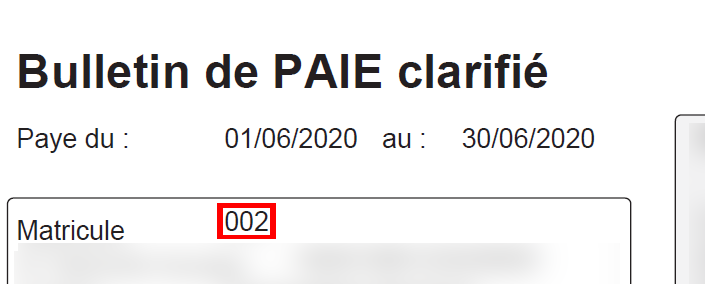
Pour garantir la fiabilité du matricule, le processus d’embauche passe par l’étape d’immatriculation, i.e. de la vérification dans la base collaborateurs du fait que celui-ci n’a pas encore de matricule (rien n’exclut la possibilité qu’il soit parti de la société pour y revenir plus tard). La situation peut être complexe si par exemple la personne a été licenciée pour une faute grave … L’identifier c’est crucial.
Pour l’instant, nous n’avons pas vraiment besoin d’un véritable outil MDM car nous ne faisons que du « rapprochement » de données. En ce sens, nous aurions plutôt besoin d’un moteur de rapprochement, pour en savoir plus : (https://ithealth.io/rapprochement-de-donnees/, « matricule » = « ID unique »).
Dans le cas des grands groupes, si plusieurs systèmes RH coexistent, naturellement, les choses se compliquent. Dans ce cas, deux stratégies s’offrent à nous :
- soit nous pouvons nous contenter avec un matricule « branche » et puis au niveau de RH groupe nous allons ré-créer un matricule groupe,
- soit nous voulons créer un matricule « groupe » dès le début.
Cas 1. Branches indépendantes
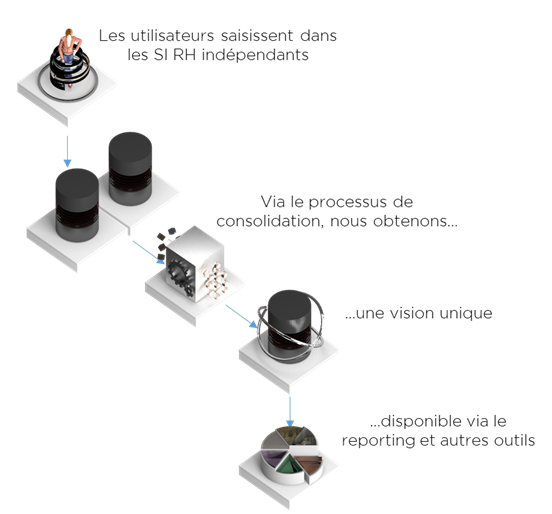
Dans ce premier cas, nous avons plusieurs systèmes indépendants pour de multiples raisons (acquisition, fusion, legacy …). Le seul endroit avec la visibilité sur l’ensemble de collaborateurs se trouve côté BI RH. Le processus de calcul de la dimension « collaborateur » dans la BI RH correspond exactement à l’approche du MDM Consolidation (même si cela peut être sous une responsabilité d’équipe BI). Pour plus d’information concernant les styles de MDM : https://ithealth.io/mdm-ce-que-ibm-semarchy-informatica-et-ebx-vous-cachent/ .
Cas 2. Branches unies
Dans ce deuxième cas, l’objectif est de proposer un service unique à l’ensemble de systèmes RH.
Il existe deux pistes possibles :
- soit on force toutes branches à saisir les données dans un seul et même outil (MDM Collaboratif),
- soit nous pouvons laisser les systèmes exister indépendamment tout en unifiant le processus d’immatriculation (MDM Registre).
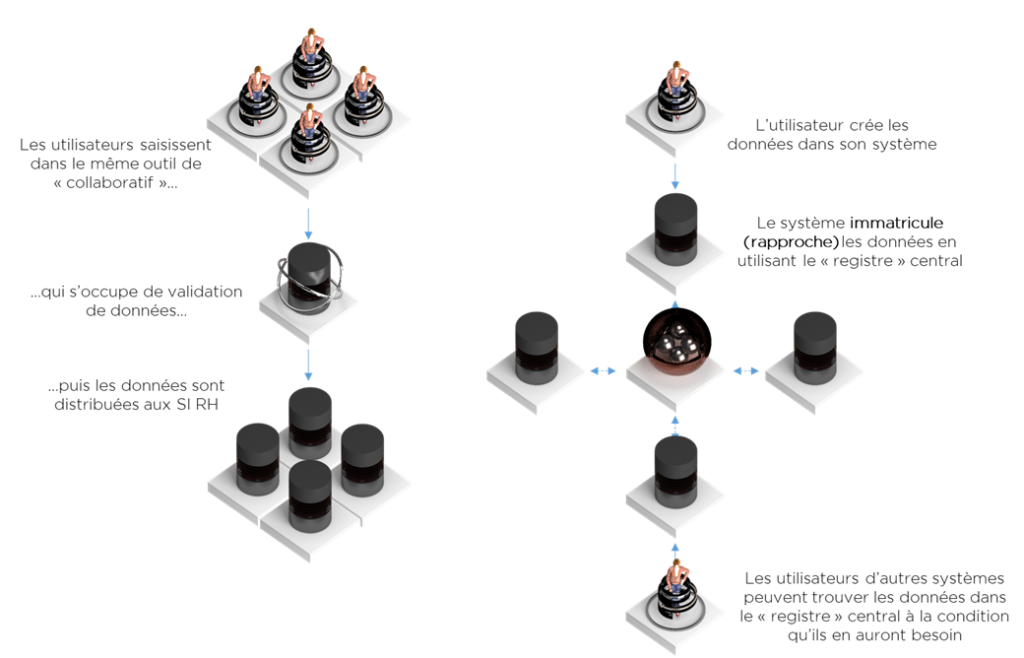
Par expérience, il est peu probable qu’un projet de MDM Collaboratif sous cette configuration soit accepté (du point de vue utilisateur, il n’est pas raisonnable de mettre en place une saisie centralisée, alors que 99% de cette information sera utilisée dans un seul SI RH). Par contre, le service « registre » qui ouvre la fenêtre dans les autres systèmes sans copier les données peut être la bonne solution.
Pour rappel, le MDM Registre est un moteur d’immatriculation et/ou de rapprochement avec des capacités de recherche de données en temps réel. Dans cette configuration, il n’y a plus besoin de « consolidation » complexe au niveau de BI car le rapprochement est accompli au niveau du groupe. Ainsi, chaque collaborateur dispose d’un matricule « groupe ».
Gestion des compétences
Prenons un exemple pour mieux comprendre les difficultés de la gestion d’un référentiel de compétences.
Si notre but final, par exemple, c’est d’estimer le niveau de nos consultants en informatique, nous pouvons commencer par lister les compétences :
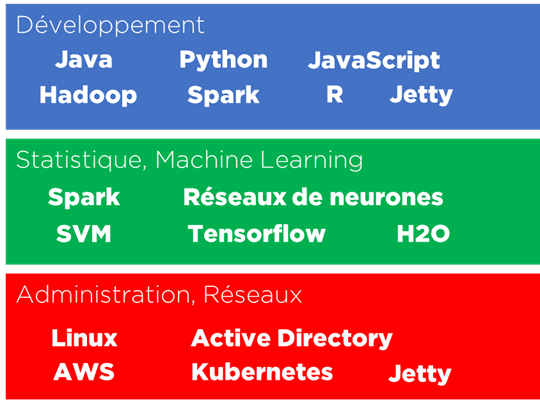
Oups. Houston, nous avons des problèmes !
Premièrement, les compétences liées au même outil peuvent être différentes : une personne utilise Jetty dans ses développements, une autre – connaît tous les modules et peut les administrer sans regarder dans la documentation. Ce sont deux jeux de compétences très différents. Dans un autre cas, un chef de projet connaît « très bien » le SQL et un administrateur de bases de données connaît « très bien » le SQL, mais ce sont deux connaissances très différentes.
Deuxièmement, nous avons des compétences de différents niveaux : un spécialiste en Tensorflow ne connaît par forcément tous les résultats de recherche dans le domaine des réseaux de neurones et vice versa, un expert en mathématique des réseaux peut utiliser Torch au lieu de Tensorflow… et on mélange tout dans le même groupe ?
Troisièmement, il n’existe pas, a priori, d’experts qui connaissent toutes capacités de Cloud Amazon ou de GCP, pourtant les certifications sont souvent généralistes (« Architecte AWS »). Même réflexion concernant Python : on imagine que la personne qui connaît Python doit forcément connaître aussi ses packages : pandas, numpy, tensorflow, etc, alors que ce n’est pas explicitement spécifié dans notre classificateur.
Tout cela signifie que notre classificateur est assez flou et malgré nos efforts, il ne sera jamais parfait. Observez, les nombreuses intersections dans les groupes de compétences :
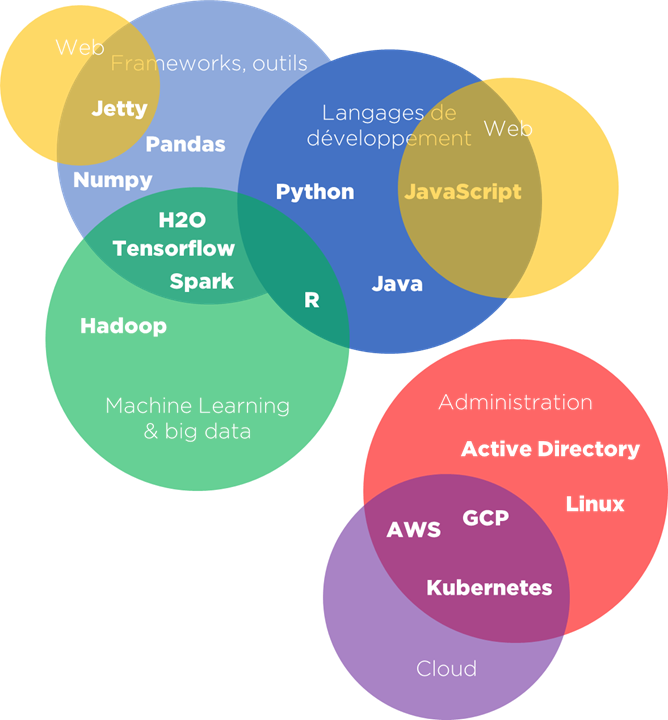
Si vous voyez deux fois la même compétence, cela ne veut pas dire qu’elle a la même signification. Cela veut dire que nous ne pouvons pas « rapprocher » ou « consolider » les compétences correctement entre les systèmes.
Si nous essayons d’utiliser le « registre », nous allons trouver les occurrences de mêmes compétences/groupes de compétences (ou pas… à cause d’un « wording » différent), mais cela ne signifie pas que le résultat sera exploitable car les petites subtilités sémantiques vont mettre notre référentiel en pièce.
Si nous essayons d’utiliser la « consolidation », cela ne fonctionnera pas non plus pour les mêmes raisons.
Il ne nous reste qu’utiliser l’approche « Collaboratif » pour ces données, i.e. imposer à toutes nos branches un classificateur commun… si c’est possible.
Conclusions
Nous avons considéré deux types de données :
- information personnelle – peut profiter du MDM Registre pour l’immatriculation en temps réel au niveau de groupe. Si ce n’est pas possible – le MDM de Consolidation au niveau de BI;
- référentiel de compétences – très intéressant pour une société, mais le seul style applicable à ce type de données est le MDM Collaboratif.
Qu’en pensez-vous ? Avez-vous d’autres exemples ?
Bonne santé à vous et à vos données !