
Cet article est la suite et donc cinquième épisode de notre série concernant la consolidation de données. Aujourd’hui nous allons parler de la validation :
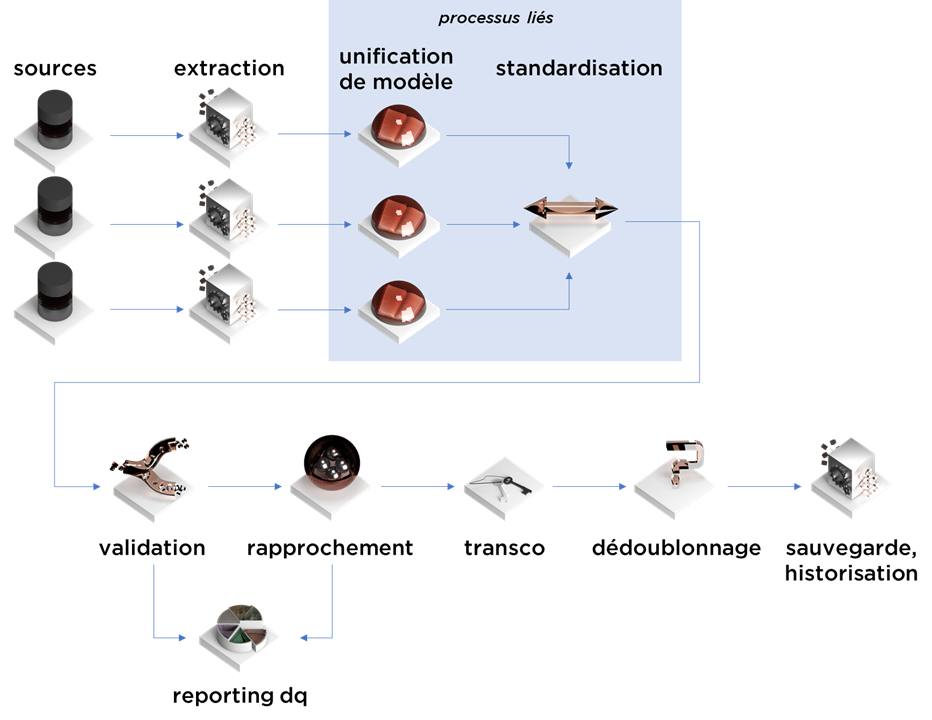
Motivation
La vérification de données est souvent perçue comme une étape qui ne fait pas forcément partie de la consolidation, mais ce n’est pas tout-à-fait vrai pour plusieurs raisons :
- facilité : au moment de la consolidation, nous avons déjà toutes données à notre disposition, il est donc raisonnable de profiter de cet instant ;
- utilité : la validation de certaines données peut simplifier le traitement de l’information à l’étape du rapprochement (par exemple, vous rapprochez les personnes / sociétés et vous avez déjà identifié que certains champs sont erronés – vous pouvez les exclure ou déprioriser) et clarifier l’utilité de données pour les consommateurs ;
- traçabilité : durant la consolidation, vous connaissez la source des données donc les erreurs générés peuvent être attachés à votre modèle final. Ainsi, il vous sera plus facile d’analyser les résultats et les croiser avec les erreurs de validation (contrairement au projets de qualité de données séparés).

Commençons par classifier les erreurs
Il est utile de classifier et cartographier les erreurs potentiels :
- par class d’erreur (https://ithealth.io/data-quality-les-types-derreurs/):
- valeurs incorrects ;
- données incomplètes ;
- données en mauvais format (malgré la standardisation) ;
- données incohérentes ;
- erreurs logiques ;
- etc…
- par niveau de gravité :
- incertain – erreur potentielle (à titre informatif) ;
- confirmé, non-bloquant – erreur certaine avec un impact mineur sur l’utilisation d’information ;
- confirmé, bloquant – erreur importante qui doit être corrigée le plus tôt possible.
Une multitude d’approches
Voici ma collection des méthodes de validation de données conseillées pour détecter les différents types d’erreurs de qualité de données.
Les contrôles basiques
Vous pouvez toujours commencer par les contrôles basiques :
- pour les valeurs numériques – vérifiez la distribution et les données exceptionnelles,
- pour les valeurs de type « date », vous pouvez analysez également la distribution dans le temps, mais il est utile de vérifier aussi la distribution de chaque élément suivant : jour du mois, mois, jour de l’année, année,
- pour les lignes de caractère, nous pouvons toujours analyser la distribution des longueurs, mais il est aussi utile de faire attention aux caractères utilisés dans les valeurs.
Les contrôles par le dictionnaire
Si vous avez un dictionnaire plutôt complet des données, vous pouvez vérifier si l’information obtenue s’y trouve (ex. code postal, code IATA, code pays, préfix de téléphone, code NAF, etc).
Le dictionnaire +++
Parfois, pas besoin de dictionnaire exhaustif pour détecter les erreurs. Par exemple, vous pouvez détecter les prénoms/noms de famille erronés en les comparant avec les prénoms/noms fréquents de votre base de données.
Si la différence (par un algorithme de Levenshtein) est minimale et le mot en question rare, il est très probable (mais pas certain) que nous avons trouvé une faute de saisie (que nous pouvons aussi automatiquement corriger si nécessaire).
Les contrôles de format
Si vous connaissez les formats attendus de données, vous pouvez les vérifier avec les expressions régulières ou avec les représentations suivantes :
- remplacez chaque lettre par « A » ;
- remplacez chaque chiffre par « 9 » ;
- (option) supprimez les symboles inutiles ;
le résultat obtenu ne dépend plus de contenu – il décrit le « format » de données, par exemple :
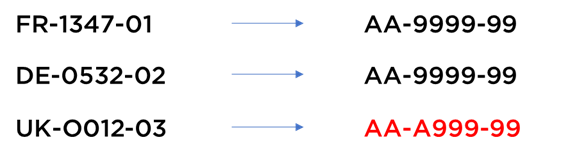
En revanche, si vous ne connaissez pas les formats au début du traitement, vous pouvez quand même détecter les cas spécials en comparant les fréquences des formats.
La validité des codes
Fort pratique, les codes officiels peuvent souvent être vérifiés, i.e. contiennent une certaine « protection » contre les fautes de frappe. Les algorithmes le plus connus utilisent la formule de Luhn (https://fr.wikipedia.org/wiki/Formule_de_Luhn) ou la formule « modulo 97 ».
Si vous avez un code TVA français, il utilise les deux algorithmes à la fois :
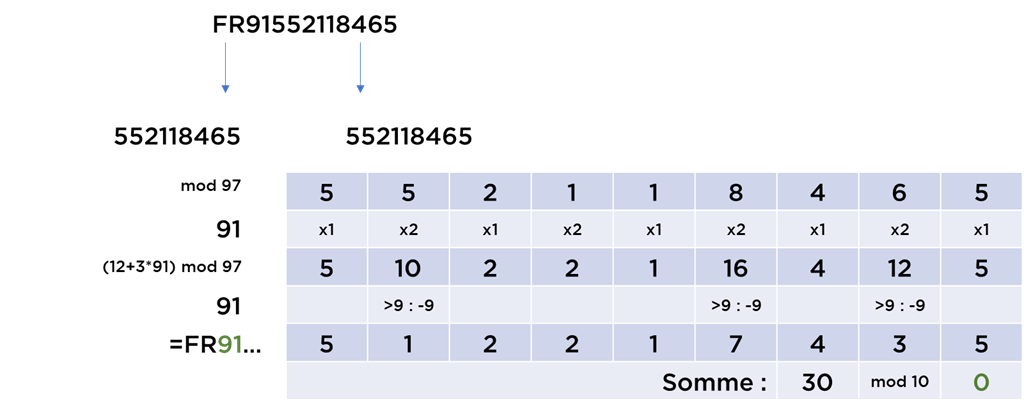
Ici, les derniers 9 chiffres (SIREN) doivent donner 0 après l’application de la formule de Luhn, alors que les deux premiers chiffres (clé de TVA) sont égaux à (12+3*(SIREN mod 97)) mod 97. Si les deux vérifications sont Ok, vous pouvez avoir confiance dans la validité du code (mais pas dans le fait que le TVA est bien attaché au bon objet).
Les règles logiques
C’est une groupe de règles très facile à vérifier qui permette de valider les hypothèses de base :
- du point de vue médical, une femme devenue mère ne peut pas avoir le sexe « homme » (en médecine, il y a souvent bien plus que 2 sexes) ;
- le sexe de la personne ne doit pas (normalement) être différent du sexe encodé dans le numéro de sécurité sociale (voir https://secu-jeunes.fr/dico/numero-de-securite-sociale-nir/ et https://fr.wikipedia.org/wiki/Num%C3%A9ro_de_s%C3%A9curit%C3%A9_sociale_en_France) ;
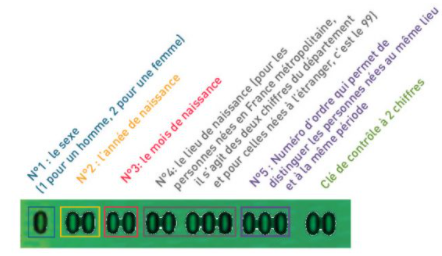
- le date de naissance ne peut pas être dans le futur (sauf pour un SI hospitalier) ;
- en finance, la date de maturité d’un titre ne peut pas être inférieure à la date d’émission ;
- etc.
Unicité
Nous allons évoquer le processus de rapprochement/dédoublonnage de données bientôt, mais il existe des règles de gestion non-automatisées qui peuvent nous aider trouver des cas particuliers :
- la règle « le code de la facture est unique par société et par année » nécessite une validation simple – et nous savons que c’est n’est pas toujours le cas et que les données en question contiennent des contre-passations (facture dupliquée avec signe inversé) ou que certaines sociétés envoient des factures en double ;
- les règles « chaque personne a un numéro sécurité sociale unique » et « le champ NUM_SECU est le numéro de sécurité sociale de la personne » peuvent être validées ensemble en faisant la décompte du nombre d’occurrences de chaque numéro dans la base de données (ex. RH) – et parfois les données contiennent des doublons, ou bien les enfants en stage dans la société de leurs parents utilisent leur numéro sécurité sociale…
Ces informations peuvent nous aider « corriger » les données ou en apprendre plus concernant les processus fonctionnels de la société.
La validation externe
Il n’y a pas de meilleur algorithme que l’algorithme qui n’existe pas… donc vous pouvez utiliser les services externes pour la validation de données.
Les cas classiques :
- utilisation du service de géocodage pour la standardisation, puis utilisation de retour concernant la précision pour la validation de la qualité de résultats ;
- utilisation de services professionnels pour la vérification de données concernant les sociétés / établissements.
Complétude pour rapprocher
Une autre technique consiste à utiliser le moteur de rapprochement de données pour vérifier si les données sont suffisamment complètes.
Les meilleures techniques de rapprochement utilisent une notion de « score » de rapprochement (liée à la probabilité que deux objets A et B représentent la même entité fonctionnelle).
Vous pouvez calculer les scores d’objets avec eux-mêmes et cela vous donne une idée du score maximal de rapprochement avec d’autres objets. Si ce score est bas, l’objet est potentiellement « incomplet » du point de vue fonctionnel car il n’est pas « identifiable » parmi les autres informations.
Les yeux des utilisateurs
Un autre argument en faveur d’une approche combinée pour gérer la qualité de données dans le reporting / dataviz – vous allez avoir « gratuitement » des personnes motivées qui, lors de leur exploration des données, sont susceptibles de remarquer les erreurs.

Il est important dans ce cas de figure de ne surtout pas ignorer l’information remontée par vos utilisateurs. C’est certain, vous aurez des fausses alertes car il est parfois difficile de percevoir correctement l’information, mais soyez patient – à la longue, vous obtiendrez des retours sur la qualité de données avec les priorités de traitement.
Comment traiter les erreurs ?
Très bien, maintenant nous savons vérifier les données. Qu’est-ce qu’on fera avec les fautes (ou bien les cas suspects) trouvées ?
Plusieurs approches en la matière, dont les plus standards sont :
- rejeter les données erronées et attendre le moment de la correction (d’où la fameuse reprise après la correction) ;
- garder la trace des données, mais supprimer les valeurs erronées ;
- garder les données telles qu’elles, mais flaguer les valeurs erronées ;
- essayer de corriger les données ;
- arrêter la consolidation (i.e. interrompre le processus de consolidation tant que les erreurs bloquantes ne sont pas corrigées).
À mon avis, la perte de données (même erronées) est surement plus risquée que le fait d’utiliser des valeurs en erreur. Dans ce cas, si vous ne pouvez pas corriger les informations automatiquement (oui, la correction automatique est une approche valable), vous devez garder l’information en place au moins pour ne pas fausser (encore plus) les autres informations.
Pour la correction, vous avez deux tactiques majeures :
- corriger les données au moment de la consolidation
- revenir vers SI sources et corriger directement l’information
Il est clair que le deuxième approche apporte plus de valeur à l’entreprise, mais elle est parfois complexe à mettre en œuvre pour plusieurs raisons : direction différente, sujet organisationnel, budgétaire, etc. Dans ce cas, nous pouvons utiliser les UIs de « sur-chargement » de données.
Par contre, durant le « sur-chargement », i.e. la correction durant la consolidation, de nouveaux problèmes apparaissent, notamment :
- durée de sur-chargement (est-ce que votre correction s’applique à vie ou bien à chaque nouvelle modification de données) ;
- non-traçabilité des données (votre nouvelle version ne correspondra à aucune réalité dans les SI sources) ;
- etc.
Conclusion
La validation est une étape majeure dans le processus de consolidation des données. Il peut servir à la fois à l’améliorer les algorithmes de rapprochement, à contrôler la qualité de données avant la distribution de l’information, à mieux comprendre les processus fonctionnels, etc.
Si vous utilisez d’autres techniques – n’hésitez pas à compléter la liste – envoyez-nous un message via la formulaire de contact ou commentez sur LinkedIn.
Bonne santé à vous et à vos systèmes.