
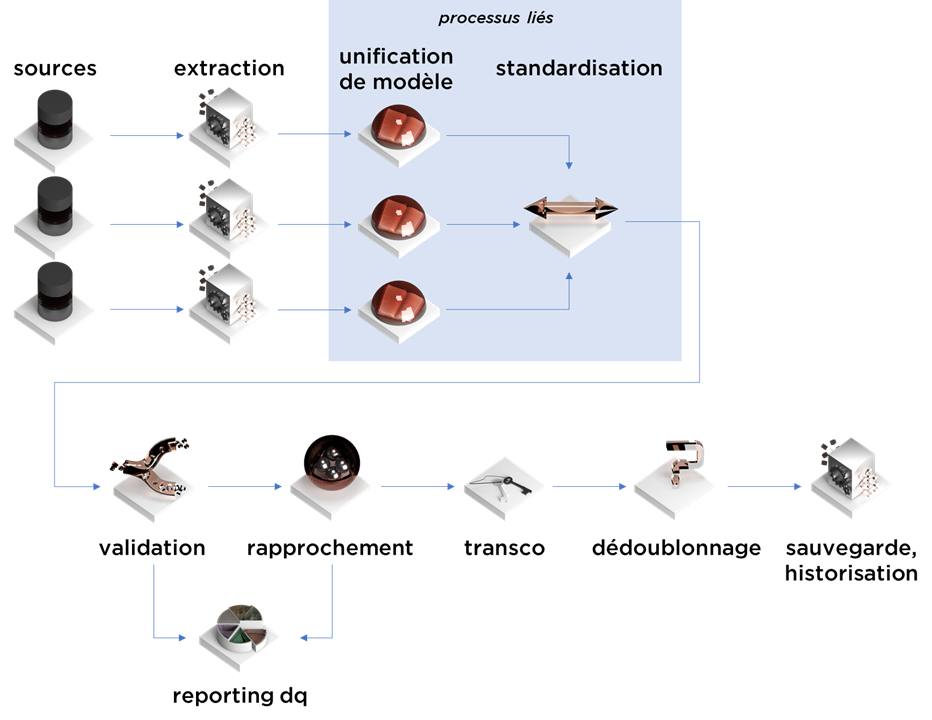
Cet article est la suite et donc quatrième épisode de notre série concernant la consolidation de données. Aujourd’hui nous allons parler de la standardisation :
Notion
La standardisation est un processus de conversion de données en format « standard », dit autrement, on cherche à diminuer l’impact de la « forme » sur le contenu.
Un autre sujet important est l’interprétation de données. Prenons pour l’exemple, le nom d’une société : « Neuro Learn SA ». Ici « Neuro Learn SA » est le « nom » de la société, mais nous pouvons aussi dire que « Neuro Learn » est le nom, alors que « SA » est une forme juridique. Le « humanware » qui saisit dans ses outils informatiques (CRM/ERP/etc) peut ne pas faire de la distinction entre ces deux notions, alors que techniquement, il s’agit bien de deux sujets différents.
Ainsi, il peut se passer qu’au moment du rapprochement de données ou bien au niveau analytique, vous allez avoir besoin de séparer les notions. Bienvenue dans le monde merveilleux de la standardisation des différents formats de données.
Point de vigilance : la standardisation peut faire du bien mais aussi beaucoup de mal. Les algorithmes intelligents de standardisation ne pourront jamais standardiser les données dans tous les cas – on verra des exemples par la suite. Dans cette situation, il va falloir se faire une raison, parfois vous allez devoir utiliser les données en l’état, surtout pour les besoins opérationnels.
Le challenge
Les problèmes démarrent dès la réception de données (nous pouvons utiliser l’expression « standardisation à l’extraction ») :
- les données brutes d’un système informatique peuvent contenir des informations horodatées sur différents fuseaux horaires – nous allons devoir potentiellement faire une « transcodification » en format universel (vérifiez les numéros de semaines aussi – il n’existe pas de définition universelle non plus) ;
- les données textuelles brutes peuvent exister en encodages différents et non-compatibles (c’est pour cela qu’il vaut mieux prévoir l’utilisation d’Unicode) ;
- …par contre, faites attention : les symboles qui ont la même forme sur votre écran peuvent avoir des codes très différents – probablement vous pouvez vouloir les « unifier » aussi (ex. https://www.compart.com/fr/unicode/category/Pd) ;

La « standardisation à l’extraction » est souvent assez basique, c’est plus tard que nous allons avoir besoin « d’intelligence » :
- standardisation du noms des sociétés ;
- standardisation des adresses ;
- standardisation du nom des personnes ;
- standardisation du nom des produits (si possible) ;
- extraction des numéros de contrats, des factures depuis les champs non-formatés ;
- etc…
Parfois, la standardisation se mélange avec le mapping vers le format universel, surtout dans les situations où la standardisation en question est spécifique à SI source spécifique :
- si un type d’erreur n’existe que dans un système bien précis (ex. dans le CRM, les codes TVA historiquement stockés dans un champ « description »);
- si le mapping vers un modèle universel utilise la nomenclature – il peut se passer que vous devrez également la « transcodifier » à l’extraction, mais c’est plutôt une exception.
Autrement dit, dans la majorité de cas complexes, la standardisation est le processus qui se base sur les lignes de caractères pour :
- vérifier si les valeurs de champs respectent les métadonnées (nom – dans le champ nom, prénom – dans le champ prénom et pas vice versa) ;
- décomposer les lignes de caractères en éléments (parsing) ;
- supprimer les différences inutiles pour une tâche donnée.
À ce stade, pas nécessaire de parler de la gestion de la nomenclature car dans notre processus, elle joue le même rôle que les autres données.
Les outils et les approches
Traitement au niveau des caractères
La méthode de standardisation de données textuelles la plus basique et la plus utilisée consiste à remplacer certains caractères :
- minuscules -> MAJUSCULES ;
- supprimer les accents ;
- translitérer (surtout si vous devez traiter les noms propres en plusieurs langues) ;

- supprimer les symboles qui représentent le « bruit » pour la suite de traitement (par exemple, tiret, virgule, … pour le traitement d’adresse ; tout symbole non-numérique pour la majorité de numéros de téléphones ; tout symbole non-alpha-numérique pour les codes de contrats/factures/etc) ;
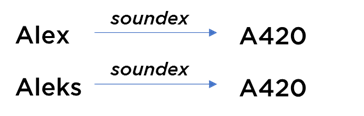
- parfois, pour le futur usage (surtout au niveau de rapprochement de données), il faut également calculer les codes Soundex / NYSIIS / Metaphone qui permettent tolérer la majorité des fautes de saisie (vous pouvez essayer l’algorithme Soundex online vous-mêmes : http://sites.rootsweb.com/~nedodge/transfer/soundexlist.htm) :
Lookup
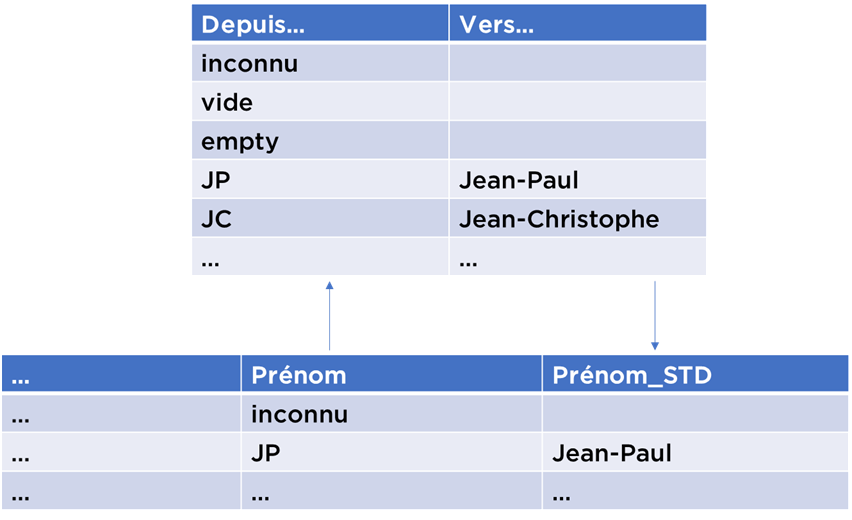
La solution la plus utilisée pour « standardiser » les valeurs c’est d’utiliser une table de substitution. Par exemple, vous savez que certaines valeurs ont des données manquantes ou bien nécessitent d’être corrigées.
Vous pouvez utiliser une table clé->valeur pour les remplacer (si les données ne sont pas dans la table, elles ne sont probablement pas remplacées mais copiées telles qu’elles) :
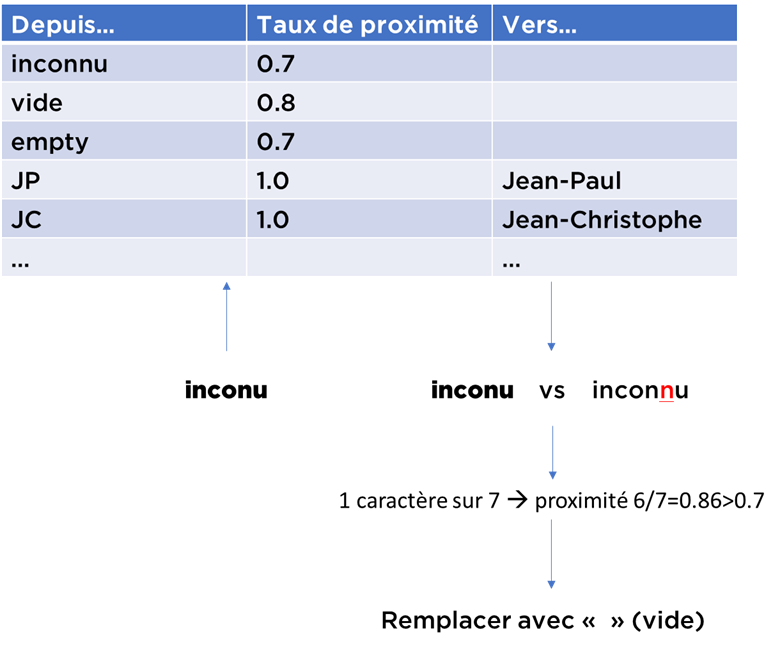
Il est possible de tolérer un certain taux d’erreurs avec une fonction qui décompte le nombre de caractères différents et si la différence est mineure – on utilise la substitution :
Regexp
Les expressions régulières sont très souvent utilisées pour les sujets simples, quand le format attendu est bien défini et la quantité d’erreurs limitée.
Par exemple, si nous avons besoin d’extraire le code TVA français depuis une description, nous pouvons supposer qu’il peut exister en 3 formats : « FR<espace optionnel><deux chiffres><espace><neuf chiffres> », « FR<11 chiffres> » ou encore juste « <11 chiffres sans espaces> ». Dans ce cas, nous pouvons l’extraire avec une expression régulière suivante :
(FR\s?)?[0-9]{2}\s?[0-9]{9}Vous pouvez la tester ici : https://regex101.com/
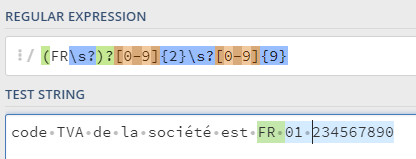
Par contre, si vous anticipez des fautes de saisie dans les données, les expressions régulières ne sont plus adaptées : il suffit de remplacer le « 0 » par « O » (lettre « o ») – et l’expression ne fonctionne plus :
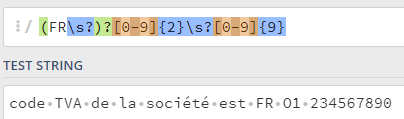
Parsing à base de règles
Pour les cas plus complexes, ex. parsing d’expressions plus proches au langage naturel (noms de sociétés, adresses, noms de produits), il faut mettre en place un système plus avancé.
Supposons que nous voulons extraire les formes juridiques depuis les noms de sociétés. Techniquement, nous pouvons juste faire une liste très longue de formes juridiques fréquentes (https://en.wikipedia.org/wiki/List_of_legal_entity_types_by_country) et les enlever… Sauf qu’il existe des problèmes liés à cette approche :
- Certaines entreprises ont des noms proches des formes juridiques : « SAS SA » ;
- Certaines entreprises ont des noms contenant certaines lettres de forme juridique : SNC (Société en nom collectif) -> SNCF ;
- en analysant attentivement vos bases de données, vous pouvez trouver que :
- parfois dans le nom de la société il y a un nom de contact : « Alex Dupont, IBM » ;
- parfois dans le nom, il y a aussi les heures d’ouverture : « 9h00-18h00, restaurant chez Dan » ;
- …ou le code contrat ;
- …ou un morceau d’adresse ;
- etc.
Nous voulons maintenant enlever tous les éléments non essentiels. C’était notre motivation de départ. On peut voir qu’un petit problème ne semble pas aussi facile à résoudre de façon systématique.
Nous pouvons procéder avec l’algorithme suivant :
- créer des dictionnaires (SAS, SA, SNC, etc -> forme juridiques; DUPONT, IVANOV, etc -> noms fréquents; 8h00, 9h00 -> heures; etc) ;
- analyser les données et créer des règles d’interprétation, par exemple si nous trouvons que la ligne correspond à un certain pattern, on peut la traiter de façon spécifique à ce pattern :
- <mot inconnu> <forme juridique>
- considérer le « mot inconnu » comme un nom de la société
- considérer la « forme juridique » comme une forme juridique;
- <mot inconnu><forme juridique><mot inconnu><forme juridique> :
- premiers 3 mots -> dans le nom de la société;
- dernière forme juridique -> dans la forme juridique ;
- etc.
- <mot inconnu> <forme juridique>
- appliquer ces règles aux données pour la standardisation.
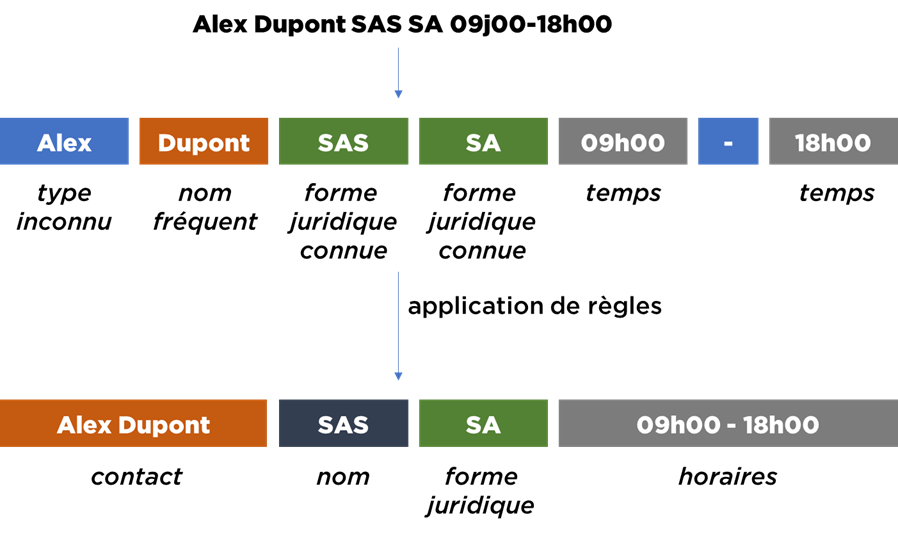
Cet algorithme permet de prendre en compte le contexte d’utilisation de chaque « mot » (token) en gardant la traçabilité de son fonctionnement (i.e. techniquement vous pouvez expliquer, pourquoi dans chaque situation les données ont été traitées de cette manière et ajuster l’algorithme si nécessaire).
La seule difficulté ici c’est de posséder des dictionnaires suffisamment vastes avec des règles qui couvrent la majorité des cas de figure. Malheureusement, il existera toujours des cas non analysables.
À noter que vous pouvez combiner l’algorithme de parsing à la base des règles avec les tables de substitution et parser / remplacer en même temps (exemple : le mot « av. » dans le champ « adresse » si elle est identifiée en tant que type de rue peut être remplacée par « avenue » en sortie).
L’approche qui utilise les règles de gestion est la méthode standard pour les deux outils les plus connus sur le marché français : IBM QualityStage et Informatica Data Quality (IDQ). La différence entre le deux se situe sur la manière de décrire les règles : QualityStage utilise son propre langage spécialisé, alors que IDQ propose une interface graphique. Il est difficile de dire ce que est mieux pour les algorithmes complexes.
En tout cas, vous avez toujours la possibilité de proposer votre propre solution en Python/Java/Scala/Groovy/Kotlin/etc.
Je dois vous prévenir : cette méthode ne peut pas traiter tous les cas, surtout en cas d’ambiguïté. Par exemple, la standardisation de noms/descriptions de produits est tout sauf évidente. Un test ? Comment classifier le mot (token) « V6 » pour les produits suivants ?

Rapprochement avec les sources externes
Il est parfois possible de remplacer l’algorithme complexe de la standardisation « intelligente » par un rapprochement avec les sources externes.
Par exemple, au lieu de standardiser les adresses, vous pouvez utiliser le service de géocodage de Google pour obtenir une version « standardisée » avec en plus les coordonnées GPS.
Sinon, pour les sociétés françaises vous pouvez utiliser les « open data » de SIRENE et comparer votre référentiel au « ground truth ». Vous allez en plus SIRENiser / SIRETiser vos données.
Cette approche peut être moins chère que les solutions de standardisation.
Méthodes plus complexes
Dans un monde de machine learning et d’algorithmes complexes, il n’y a pas de raison de s’arrêter sur les approches basiques si vous êtes persuadés que vos efforts vont avoir un impact positif sur les processus fonctionnels.
Vous connaissez probablement les méthodes de RNN/LSTM/Transformers et autres types de réseaux de neurones – dès lors, vous avez les moyens pour assembler un grand jeu d’exemples et entraîner des modèles, vous pouvez obtenir le résultat meilleur qu’avec parsing à la base de règles manuelles.
Sinon, il y a des algorithmes NLP (Natural Language Processing) de parsing (tagging) qui n’ont pas besoin d’autant d’informations en entrée que les réseaux de neurones. Comme l’algorithme de Viterbi qui est généralement appliqué pour rechercher la nature des mots (Part of Speech Tagging). Il peut être utilisé pour le parsing dans des cas généralistes (si vous voulez, vous pouvez trouver l’explication de l’algorithme ici : https://www.youtube.com/watch?v=mHEKZ8jv2SY).
Note sur les approches
La standardisation est la Cendrillon de votre consolidation. Il ne faut pas être trop puriste sur les tâches qu’on prépare pour cette étape. En plus de l’extraction, du remplacement et de la suppression de données, la standardisation a le droit d’apporter les nouvelles données, par exemple :
- durant le parsing d’adresse, ajouter les coordonnées géographiques ou un code postal manquant ;
- durant le remplacement des prénoms – identifier le sexe si possible ;
- durant l’extraction du code TVA – identifier le pays si possible ;
- etc.

Traçabilité
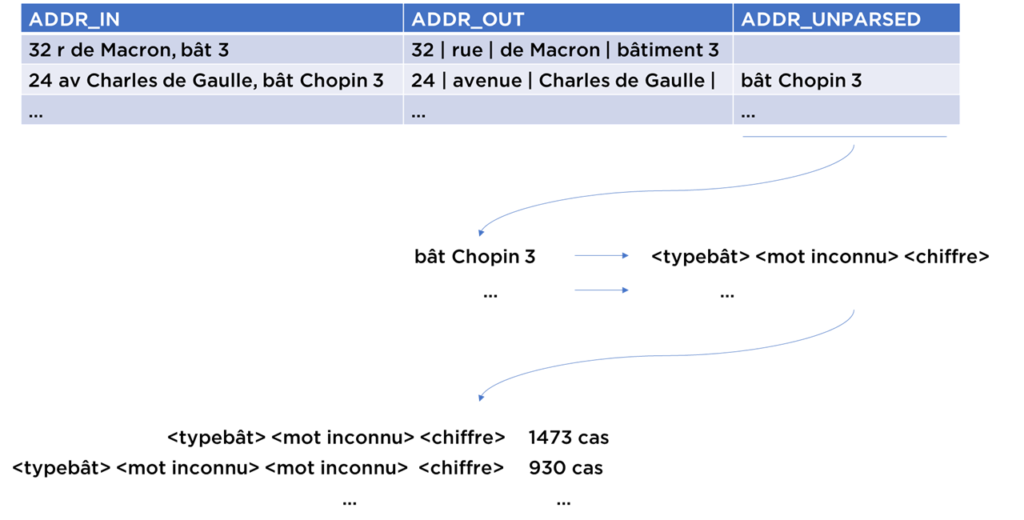
Durant le développement / débug d’algorithmes complexes, il est très utile d’avoir la traçabilité des données :
- pouvoir analyser les entrées et les sorties ;
- pouvoir analyser les « rejets » d’algorithme (ex. tokens non-identifiés, champs qui deviennent vides après la standardisation, etc).
Pour organiser le suivi de la standardisation, voici deux méthodes classiques :
- préserver les données intermédiaires, i.e. en plus de entrée-sortie sauvegarder les flags ou les résultats de calcul de chaque étape pour pouvoir y revenir et analyser les cas non-traités ;
- calculer les statistiques sur les valeurs que l’algorithme ne peut pas classifier/remplacer – il vaut mieux savoir que parmi les données non-traitées il y a 3 cas fréquents qui ne sont pas pris en compte plutôt que 2543 lignes impactées.
Conclusion
La standardisation est une étape complexe, mais très importante pour toute consolidation de données : elle permet de diminuer les différences entre les représentations possibles de mêmes données et simplifie par la suite le rapprochement, l’analyse et la consommation de l’information.
Se souvenir, par contre, que la standardisation ne pourra jamais être parfaite, ce processus est itératif et perpétuel !
Bonne santé à vous et à vos systèmes !