
Cet article est la suite et donc le troisième épisode de notre série concernant la consolidation de données.
Comme vous l’avez probablement compris, aujourd’hui nous allons parler de l’unification du modèle de données, soit l’étape 2 du processus de consolidation :
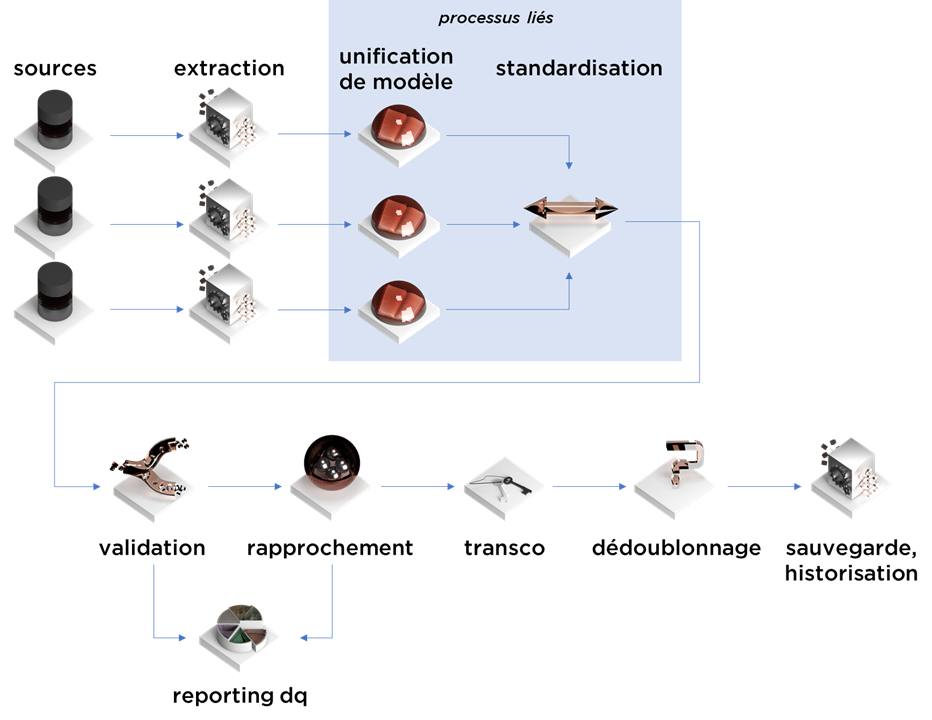
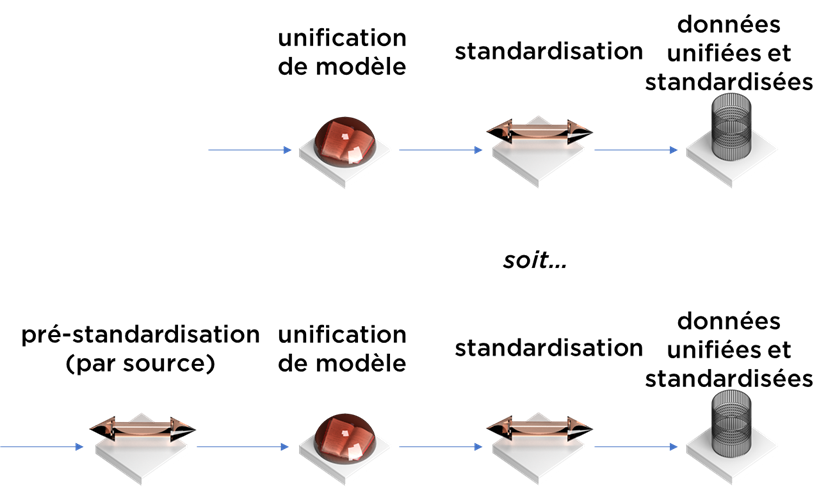
Avant de commencer, il faut avoir à l’esprit que l’étape d’unification de modèle peut se mélanger avec la standardisation – les limites sont un peu floues.
Notion
Le modèle unifié (canonical data model) est bien connu dans le domaine de l’intégration d’information (https://www.enterpriseintegrationpatterns.com/patterns/messaging/CanonicalDataModel.html ou https://en.wikipedia.org/wiki/Canonical_model) :
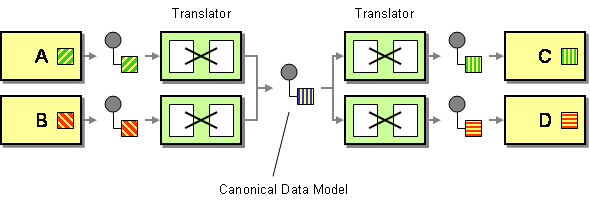
L’idée est le même que dans les autres domaines : il est plus facile de traiter les données de même structure. Sans structure unique, il faudra répéter certaines opérations plusieurs fois sur différentes structures. Il y a fort à parier que votre projet ressemblera à un plat de spaghetti :

Le mapping que nous réalisons correspond donc 1-à-1 au paterne « Message Translator » décrit dans le livre « Enterprise Integration Patterns ».
Le challenge
Nous avons déjà parlé de fait que la consolidation (comme dans le cas du DWH) est liée à des nombreux sujets : https://ithealth.io/pourquoi-bi-a-la-main-dans-le-sac-des-projets/.
L’un de problèmes les plus sous-estimés est la modélisation d’entités fonctionnelles (en lien avec governance dictionary et metadata management) :
Prenons l’exemple suivant : nous cherchons à consolider les données de sociétés juridiques avec, pour cela, à notre disposition, les données de deux systèmes :
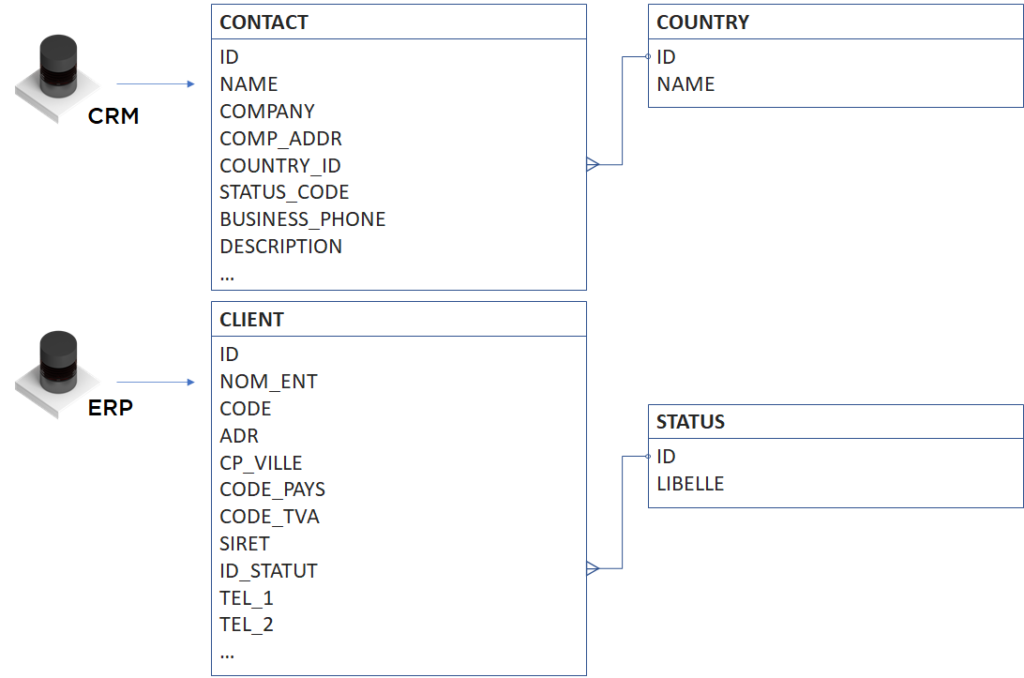
Si nous regardons les données (faisons le « profiling »), nous trouvons que :
- CRM.CONTACT.NAME est le nom de la personne ;
- CRM.CONTACT.COMPANY et ERP.CLIENT.NOM_ENT sont les noms d’entreprise ;
- CRM.CONTACT.COMP_ADDR et ERP.CLIENT.ADR sont les adresses, mais le premier peut contenir le code postal et la ville, lors que pour ERP ces données sont dans ERP.CLIENT.CP_VILLE ;
- CRM.CONTACT.COUNTRY_ID et ERP.CLIENT.CODE_PAYS jouent le même rôle – identification de pays d’adresse, mais dans un cas nous avons la nomenclature dans une table CRM.COUNTRY et dans un autre – la nomenclature est embarquée dans l’application (ex. en forme de la liste de codes ISO) ;
- nous allons découvrir les deux statuts dans les deux tables, mais sont-ils identiques – cela reste à découvrir ;
- nous avons les téléphones : BUSINESS_PHONE pour CRM et TEL_1/TEL_2 pour ERP ;
- dans l’ERP, nous avons également les codes CODE_TVA et SIRET… qui au premier regard n’existent pas dans le CRM, mais si votre outil de profiling (application ou votre cerveau) est assez performant, vous pouvez probablement trouver que dans le CRM certains codes TVA sont stockés dans le champ CRM.CLIENT.DESCRIPTION.
Il est clair qu’à partir de ces tables nous pouvons extraire les informations concernant les objets métier suivants :
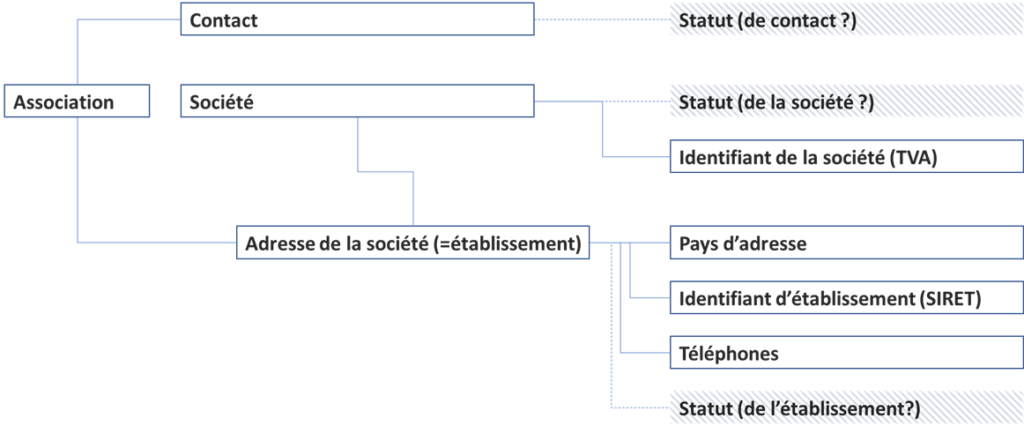
Comment ai-je obtenu les « établissements » ? Chaque société est juste une structure juridique. Par contre, la société peut avoir plusieurs adresses (les adresses de ses bureaux dans N villes, adresses d’entrepôts, d’usines, etc). Quand nous parlons de la société à l’adresse, nous parlons d’établissement.
En France, les établissements sont identifiés par les codes SIRET (mais ce n’est pas le cas pour les autres pays). Les sociétés ont des codes SIREN et TVA (encore SIREN est une invention française, mais la notion de code TVA est internationale).
À cette étape, je n’essaie pas d’imaginer la structure finale de données – pour le moment nous parlons d’objets métier qui peuvent être modélisés (ou pas) et si modélisés – en forme de tables / champs / objets / etc.
Désormais, notre sujet c’est de comprendre à quoi sont liés les statuts et si nous avons besoin d’ensemble des objets (notamment la distinction entre « société » et « établissement »). C’est une partie que nous ne pouvons pas faire uniquement en regardant sur le modèle – il faut parler avec le métier.

En parlant avec le métier donc, nous apprenons que les sociétés sont presque toujours 1-à-1 avec les adresses (et surtout les adresses que nous avons correspondent aux centres de facturation). Celui-ci ajoute qu’il existe « de grands clients qui ont plusieurs adresses de facturation ». Nous sommes obligés de garder la structure à 3 niveaux : Client-Etablissement-Contact.
Un contact peut être situé à la même adresse que son adresse de facturation ou pas… donc il faudra être vigilant au moment du rapprochement. Le sujet de statut étant résolu, donc voici notre diagramme final :
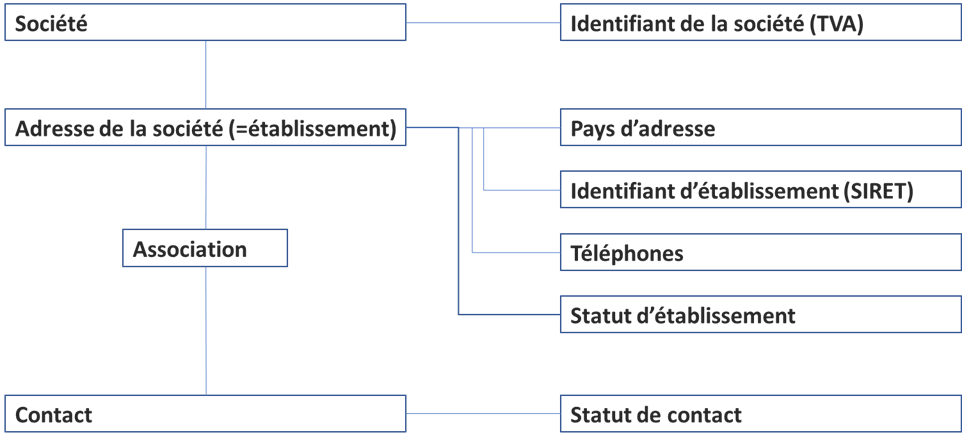
Nous sommes obligés de laisser l’association entre le contact et l’établissement car nous avons trouvé quelques contacts « en double » qui sont liés aux différentes sociétés.
À partir du diagramme, nous pouvons créer un modèle unifié normalisé en prenant des décisions concernant la flexibilité future (je vous laisse imaginer le processus) :
- nous pouvons mettre le code TVA en tant que champ dans la table « société » si nous ne prévoyons pas en futur la gestion de codes DUNs, les codes SIREN et autres ;
- nous pouvons répéter le nom de la société dans notre objet « adresse » car techniquement l’établissement peut avoir un nom propre, alors que pour l’instant la seule information que nous avons c’est le nom de la société ;
- par contre, nous sommes obligés de garder les téléphones (ou plus généralement « les moyens de contact ») à l’extérieur de nos objets car nous ne savons pas comment cela va évoluer.
Il existe une règle intéressante sur ce point : le « 0, 1 et infini » qui énonce que « si dans votre modèle vous avez 2 objets ou plus de nature identique, anticipez que le nombre de ces objets peut être quelconque ». Regardez, cela fonctionne même avec les parents. Un jour, vous allez devoir modéliser quelque chose du style « parents X et Y, mais habite chez les grands-parents A et B ».
Voici une partie de travail déjà accomplie : le modèle + mapping (pour notre exemple on montre qu’un morceau de modèle final) :
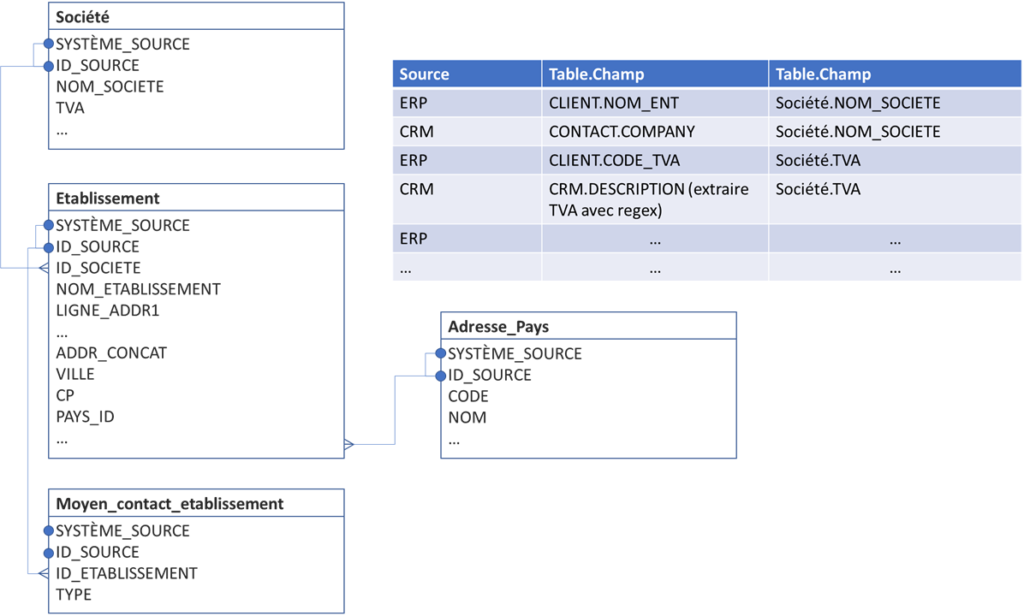
Une fois nous avons dérivé ce modèle, nous avons aussi les mappings des sources vers ce modèle. À ne pas oublier qu’à cette étape, nous laissons les données telles qu’elles, donc :
- dans chaque table il faut prévoir les champs « système source de données » et « clé unique de données dans SI source » (i.e. chaque clé primaire et secondaire sera composée de deux champs : code SI source et clé de SI source – potentiellement concaténée, probablement en varchar) ;
- la structure des champs peut être encore imparfaite car certaines données peuvent être concaténées (vous vous rappelez que nos adresses sont mal formattées et qu’il y a les codes SIREN/SIRET/TVA dans CRM.CLIENT.DESCRIPTION), donc soit vous prévoyez des champs supplémentaires dans votre modèle (ils seront supprimés après la standardisation), soit vous devez faire la pré-standardisation spécifique à chaque source au moment de mapping, i.e. :
Question restante : comment va-t-on charger la nomenclature manquante ? Dans notre modèle il y a un objet nommé « pays d’adresse » qu’on souhaite transformer en table de nomenclature dans le modèle final. Par contre, nous pouvons la charger depuis le CRM, mais pas depuis notre ERP.
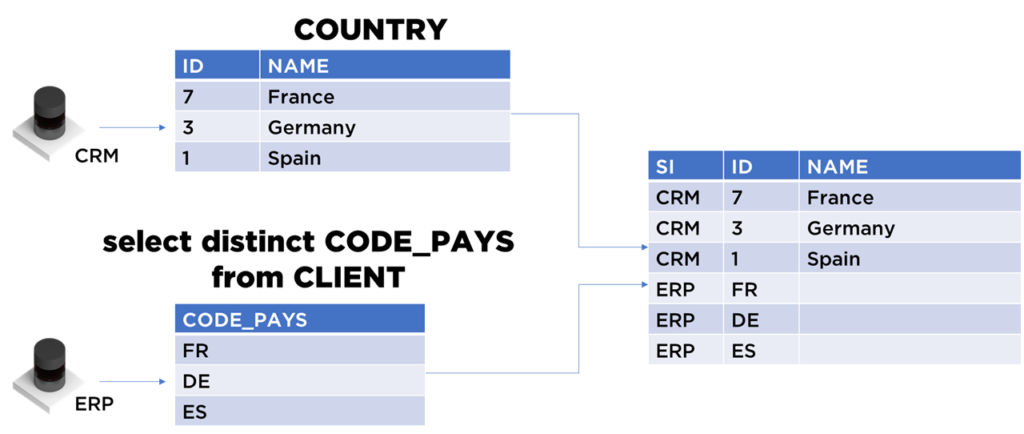
Voici l’approche générale : nous pouvons extraire les pays uniques depuis le référentiel CRM.COUNTRY et nous pouvons déduire le nombre de clés uniques utilisés dans ERP.CLIENT.CODE_PAYS :

À cette étape, il ne faut pas accorder d’importance aux codes, notre objectif est de générer la table du modèle universel :
Si nous sommes chanceux, nous pouvons combiner les données du système transactionnel avec une version de libellés préparée par les équipes ERP :
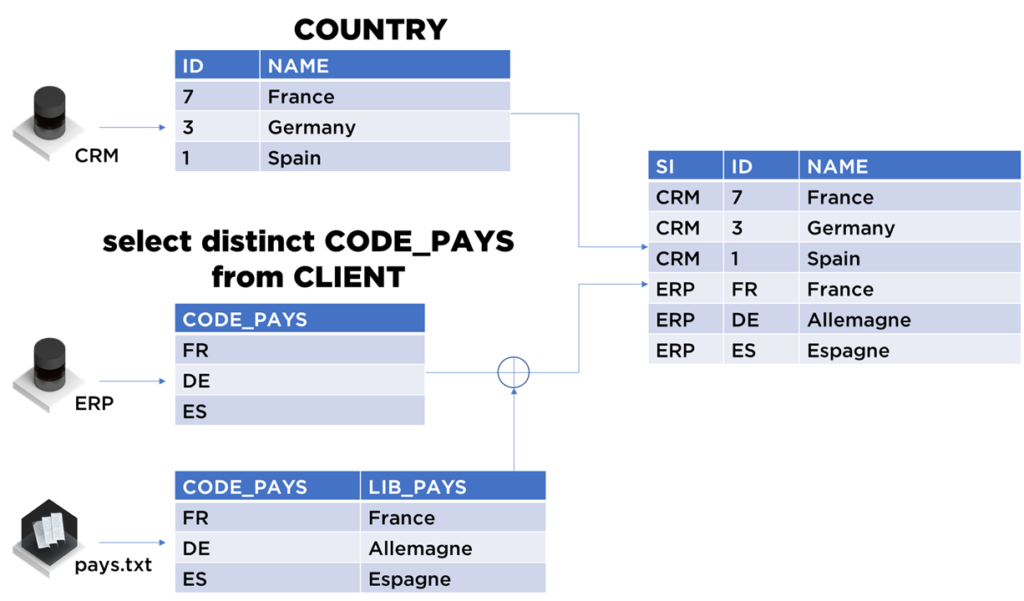
Ce processus est très générique : il faut créer tous les objets qui existent dans le modèle et si les modèles ne se collent pas (données manquantes, dénormalisées, mal structurées), il faut continuer le mapping « mécanique » (ex. déduire ou moins les clés d’objets manquants) car certains problèmes seront automatiquement résolus durant la standardisation ou le rapprochement plus tard dans la chaîne.
…même si nous avons techniquement accompli l’étape de mapping, nous voyons bien que pour la nomenclature nous pouvons avoir les données multi-langues, donc nous pouvons faire encore mieux car nous pouvons préparer le « ground truth » (mais faites attention à ce que les données préparées par vos soins aient du sens sur le plan fonctionnel) :
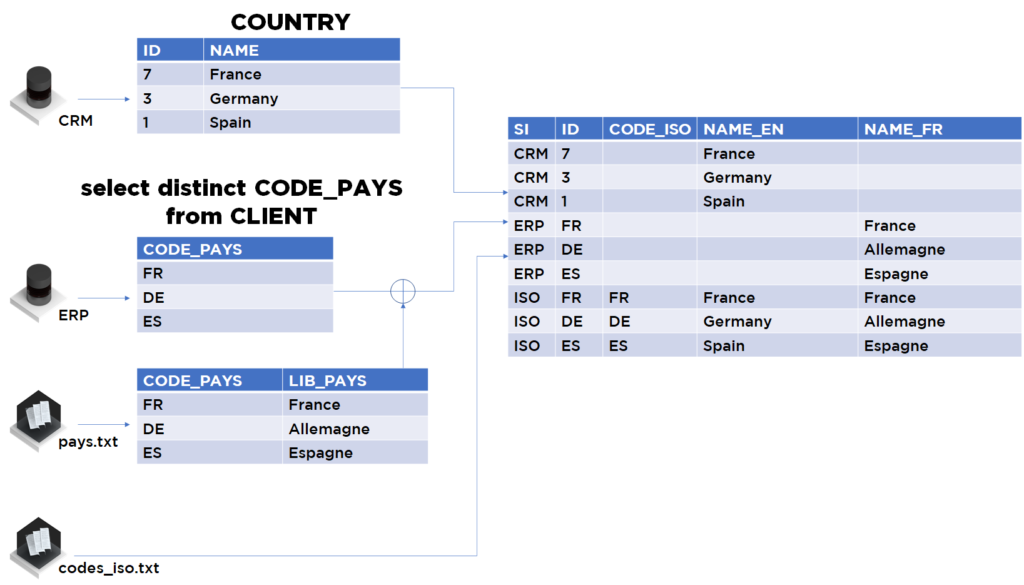
Dans notre cas, avec les données supplémentaires, nous pouvons être serein sur la faculté qu’auront nos algorithmes de rapprochement pour identifier les doublons (sinon, il faudra prévoir un travail manuel de DataStewards pour les aider).
Les notes
- Dans les projets réels, il est fort probable que les nomenclatures qui décrivent les objets semblables possèdent des natures un peu différentes. Par exemple, dans un système, vous pouvez avoir les pays suivants : « Angleterre », « Ecosse », « Pays de Galle », « Irlande du nord », et dans l’autre – une seule référence « Grande Bretagne ». Dans cette situation, soit vous trouvez un raccourci pour regrouper ces données sous une seule nomenclature « Grande Bretagne » (au moment du rapprochement et pas du mapping) sinon, vous allez devoir modéliser votre nomenclature sous la forme d’un arbre (donc dès le modèle universel)
- Internationalisation (i18n) – c’est un mot qui peut aussi multiplier le nombre de tables par deux. Dans notre cas nous avons traité les pays traduits en deux langues, mais suivant notre règle « 0, 1 et infini », nous devons nous tenir prêt si on nous demande d’ajouter l’allemand, puis l’italien, etc. Si à chaque modification de ce style, vous repassez sur vos tables de nomenclature pour ajouter des champs en plus et sur vos flux – pour ajuster le traitement – ça sera très laborieux. La solution c’est d’avoir une table de traduction à côté des tables de nomenclature.
- Il est fort probable que vous allez devoir faire des itérations sur votre modèle juste après les premiers tests de consolidation. Les champs avec les valeurs identiques dans différents processus non-alignés peuvent avoir un sens différent. Par exemple, la société avec un statut « fermé » côté service gestion peut être « en cours de cession » côté service juridique. Les petits nuances de ce genre peuvent complexifier votre modèle (ou ajouter une nouvelle nomenclature).
- Il ne faut pas hésiter à « sortir » certains objets en forme de tables. Le modèle universel n’est pas obligé d’être une copie du modèles de l’un de systèmes existants. Vous avez le droit de généraliser et de corriger les erreurs de modélisation des SI sources.
- Plus votre modèle est normalisé, plus vous allez pouvoir apprendre concernant vos données. Le modèle « plus normalisé » vous montrera automatiquement les incohérences de saisie, valeurs manquantes, etc (au moment de l’analyse du résultats de mapping ou au moment du rapprochement/dédoublonnage).
- En général, vous n’avez aucune obligation à stocker les données mappées dans une base de données (sauf si vous avez choisi de combiner l’extraction avec le mapping). Par contre, si vous avez cette possibilité (le temps + les outils adaptés), vous pouvez gagner en traçabilité de vos flux et en temps de debug par la suite.
Note. Pour se rappeler facilement la définition de la troisième forme normale (3NF), il suffit de répéter « les champs de la table dépendent de la clé, ensemble de la clé et rien d’autre, sauf la clé ».
Conclusion
L’étape du mapping est fortement lié à la modélisation des données, donc même si cela peut être techniquement très simple, c’est tout sauf mécanique.
Par contre, il y a des règles « mécaniques » qu’il faut absolument respecter pour éviter « les cas spéciaux » ou les « exceptions » dans vos algorithmes, notamment : la normalisation de modèle, l’extraction de la nomenclature, la gestion de clés des SI sources, etc.
J’espère que cet article vous sera utile pour vos projets.
Bonne santé à vous et à vos systèmes.