
Je vais lancer une série d’articles sur le sujet de la consolidation. L’objectif ? Réaliser un « brain dump » des sujets qui reviennent régulièrement. Si vous êtes un lecteur régulier d’IT HEALTH, vous devez savoir que nous avons déjà abordé ces sujets auparavant. En revanche, jamais de façon assez structuré.
La consolidation des données est un domaine crucial et ce n’est pas prêt de s’arrêter. Ce tutoriel pourra encore servir à celles et ceux qui travaillent dans les domaines suivants :
- BI – la réalisation d’entrepôts de données avancés ;
- Data Science – le croisement de données hétérogènes en l’absence d’une seule source de vérité ;
- MDM style Consolidation – l’obtention (ou bien la création) d’une seule version de la vérité (aka golden record) ;
- et bien d’autres.
Définition
Le but de la consolidation est d’obtenir une seule structure de données qui permet de travailler avec l’information comme si elle arrivait depuis une seule source autoritaire.
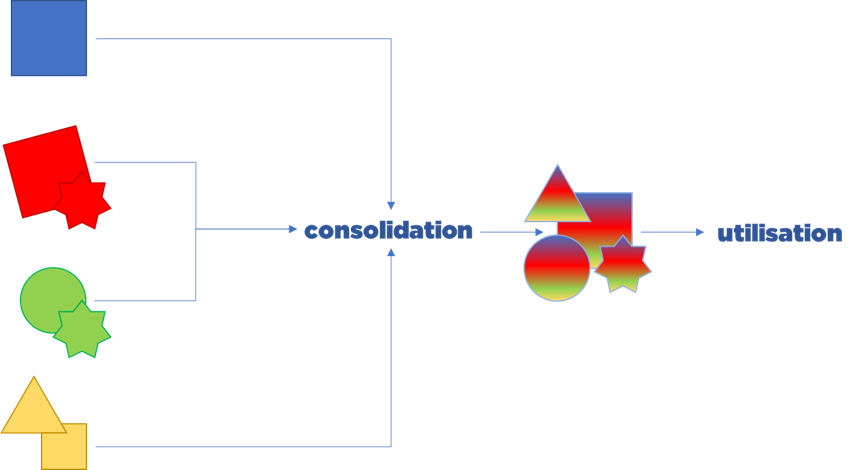
Pour obtenir cette information (qui résulte de la consolidation de plusieurs données hétérogènes), il va falloir résoudre plusieurs problèmes :
- l’accès aux données hétérogènes (N systèmes sources, dans M bases de données ou fichiers) ;
- l’existence de structures hétérogènes : même si nous avons un moyen pour lire l’ensemble de données, les modèles de données seront différents et cela complexifie tout traitement d’information ;
- la forme : si nous arrivons à identifier les points communs entre les modèles de données, la forme des données extraites peut ne pas correspondre à nos attentes ;
- les erreurs dans les données (oui oui ça arrive !) ;
- l’identification des données : si nous avons N systèmes, il y a une forte chance que les mêmes informations sont dupliquées entre les systèmes, dès lors, nous avons besoin d’identifier les répétitions ;
- une fois que les données dupliquées sont identifiées, nous devons présenter une seule version de l’information (dédoublonnée).
Pour traiter chaque problème un par un, nous vous proposons d’utiliser les processus suivants :
| Problème | Exemple | Nom de processus |
| Accès | Des données de grande volumétrie ou bien sous un format complexe | Extraction |
| Structure | Afin d’unifier les données de gestion, dans votre ERP et/ou CRM, il vous faut correctement identifier les types d’information : société, adresse (établissement), contact (personne physique), contrat, commande, alors que dans les systèmes elles peuvent être toutes présentes sous le simple nom de « client ». | Unification de modèle / mapping |
| Forme | Les noms de sociétés, les adresses, la nomenclature peuvent être présentes sous différents formats qui peuvent ne pas correspondre aux besoins d’exploitation de cette information. | Standardisation |
| Erreurs | Les noms de contrats qui ne respectent pas le format prédéfini, les codes TVA invalides, les valeurs « inconnues » ou « N/D » dans les champs, etc. | Validation |
| Identification | Le client existant sous différents identifiants dans plusieurs systèmes (ou dans le même en forme de doublon). | Rapprochement |
| Duplication | Le même contact réel identifié comme existant en double a deux noms de famille différents. | Dédoublonnage |
Processus
Nous pouvons maintenant décrire ce processus tout en ajoutant les étapes techniques :
- transcodification (gestion des clés après la consolidation) ;
- reporting des erreurs / doublons / etc;
- sauvegarde des résultats ;
- historisation des résultats ;
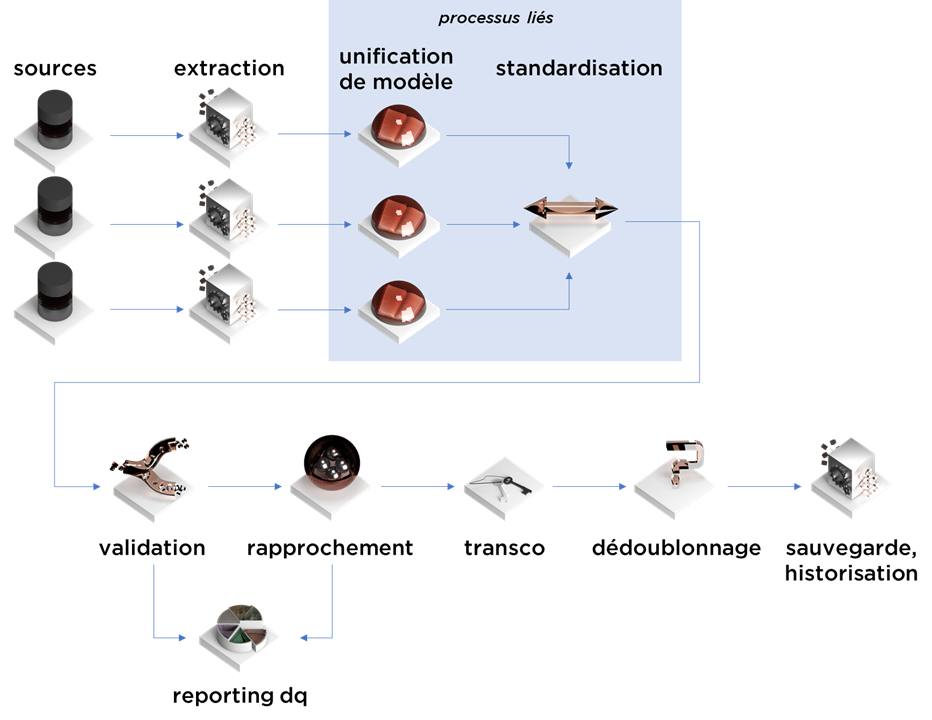
Le processus de consolidation :
- …se commence par l’extraction de données :
- outils : ETL/ELT/Change Data Capture/… (ou la réception de données via le « push » de service web si la consolidation s’exécute en temps réel) ;
- ce processus peut aussi exécuter des vérifications de format technique, d’encodage, des clés, etc, surtout si les sources de données sont non-relationnelles ;
- les données brutes passent par l’étape d’unification de modèle :
- se base sur les dictionnaires métier afin d’identifier les objets et les attributs qui ont le même sens fonctionnel ;
- les données en modèle unifié, mais avec le contenu formaté différemment passe à l’étape de la standardisation :
- outils : parsing avec regexps, dictionnaires, modèles RNN, etc ;
- ce processus peut être mélangé avec l’unification du format car certaines RG de standardisation s’appliqueront qu’à certaines sources de données ;
- les données standardisées passent par une validation fonctionnelle :
- vérification des règles de gestion afin d’identifier les données erronées, telles que : codes incorrectes, montants impossibles, etc ;
- les données validées passent par le processus de rapprochement, i.e. identification de doublons :
- outils : clés fonctionnelles pour les « transactions », méthodes statistiques/ML pour le référentiel ;
- sorties :
- table avec les identifiants uniques par « objet métier », i.e. tous les doublons obtiennent le même identifiant ;
- table avec les cas incertains ;
- les résultats peuvent être transcodifiées en cas de présence de clés étrangères (la transcodification peut se passer à tout moment, même avant la standardisation) ;
- …et enfin dédoublonnées, i.e. pour chaque identifiant généré durant le rapprochement nous choisissons une seule version de vérité (golden record).
Exemple
Afin de mieux comprendre le processus, le plus simple étant de partir depuis un exemple concret :
Supposons que nous avons deux systèmes : un CRM et un ERP. Pour ces deux systèmes, nous consolidons les données. Supposons que les informations de RDM (nomenclature) sont déjà consolidées et que nous possédons les tables de transcodification :

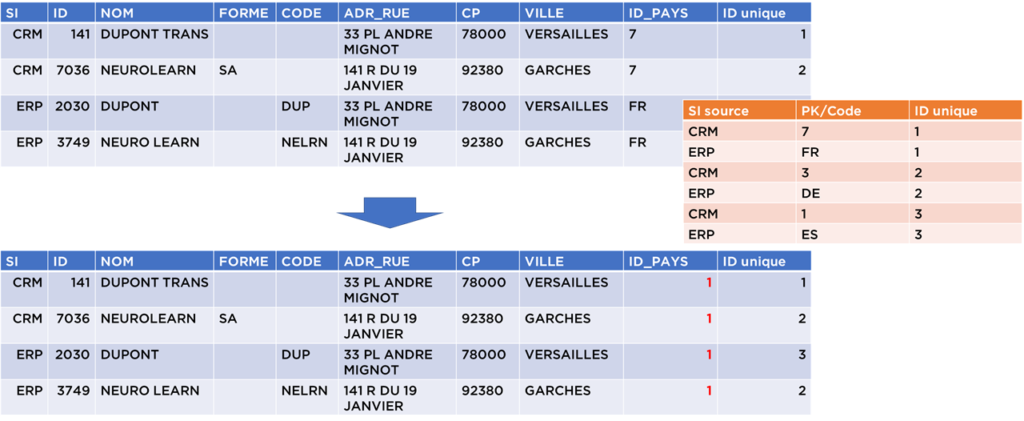
Comme vous pouvez le constater, la table de transcodification permet de faciliter la lecture. Par exemple, la France est identifiée via un ID correspondant à 7 dans le CRM mais par FR dans l’ERP. Grâce à la table de transcodification, nous pouvons créer un ID unique (1) pour ce pays qui va ensuite nous servir pour la suite.
Dans ce cas, nous pouvons procéder à la consolidation des établissements des clients :
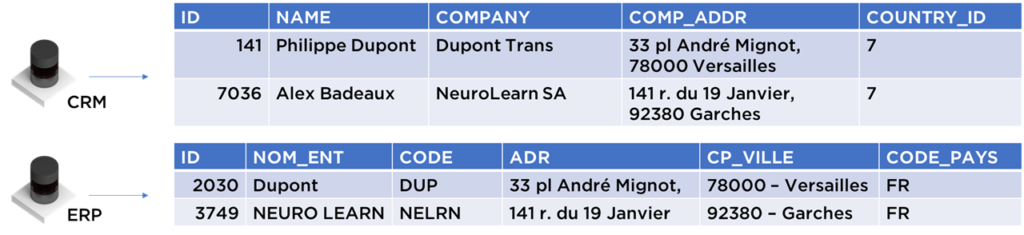
- Nous allons extraire les informations « brutes ». Nous y trouverons que pour le SI ERP, il n’y a pas d’objet distinct pour les « établissements » car cette information est mélangée avec les informations personnelles :
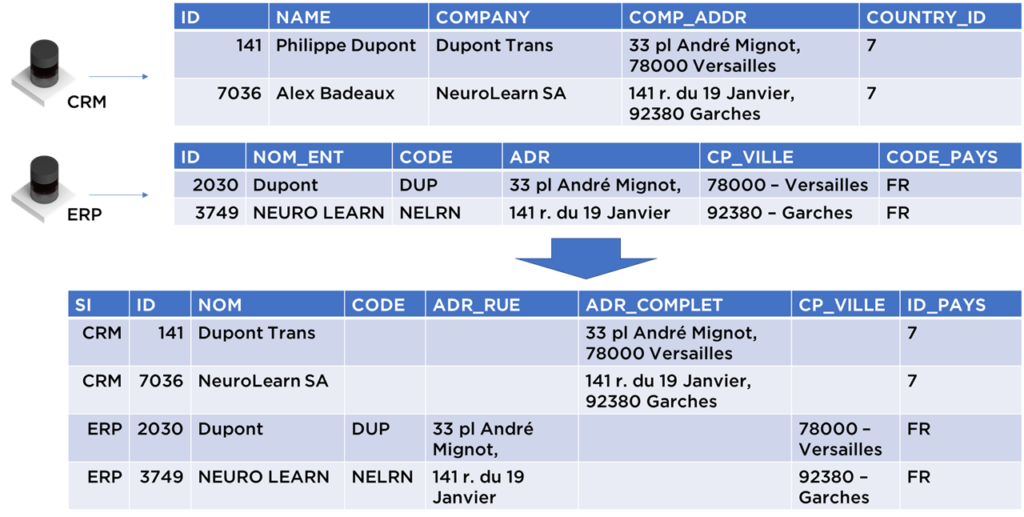
- Nous pouvons quand même unifier ce modèle et obtenir une structure intermédiaire pour les établissements pour pouvoir accueillir l’ensemble de données (malgré le fait que certains champs resteront vides) :
- C’est le moment pour standardiser les données, i.e. présenter les données sous forme qui permet au maximum ignorer le « façon » ou la « manière » de présentation d’information :
- Extraire les formes juridiques (ex. SA) depuis les noms de sociétés
- Extraire les villes/CP à partir d’adresses complètes
- Séparer CP/Ville depuis le champ concaténé
- Afin de simplifier le rapprochement de données, nous pouvons aussi tout mettre en majuscule et supprimer la ponctuation et les accents
- Techniquement, nous pouvons même diviser l’adresse en numéro – type rue – nom rue – bâtiment – etc, remplacer les abréviations, mais pour le moment nous allons laisser les données telles quelles
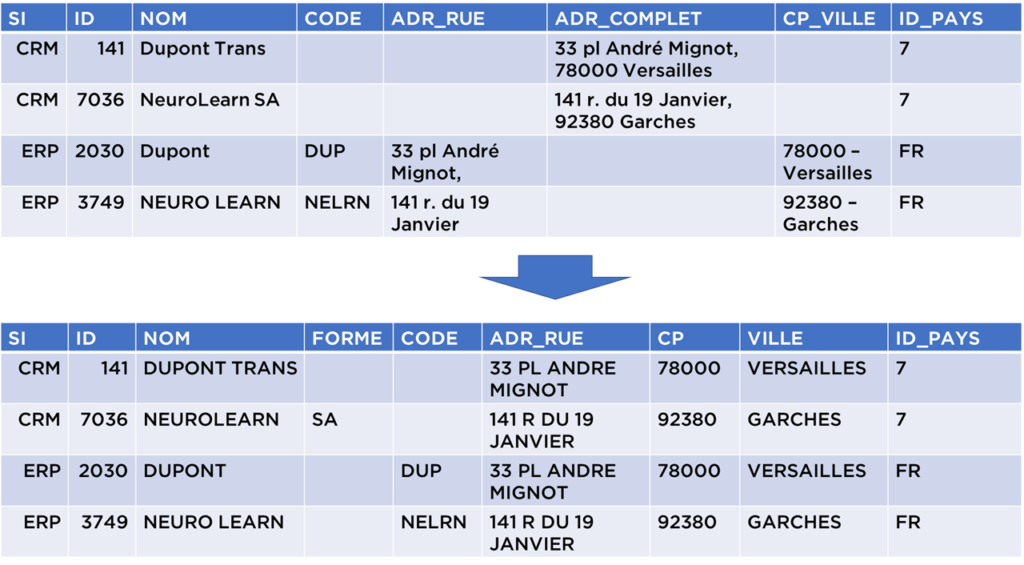
- Nous pouvons valider les données, par exemple, vérifier que les codes postaux existent réellement, mais cet étape ne produira pas d’erreurs pour notre jeu de données.
- Après la validation, nous devons comparer les données et calculer la similitude et suivant cette similitude prendre la décision concernant les doublons.
Dans notre exemple, suite à la comparaison des noms d’établissements et d’adresses, nous pouvons conclure qu’il existe 2 répétitions certaines (« NEURO LEARN ») et une – incertaine (« DUPONT » vs « DUPONT TRANS »), pour laquelle nous allons générer une trace qui doit être revue manuellement par les DataStewards. En attendant, nous supposons que les établissements « DUPONT » sont différents (car il est possible qu’il existe plusieurs établissements distincts – DUPONT comme société-mère et des société-filles ou filiales comme DUPONT TRANS, DUPONT ECO, DUPONT GAS, etc) :
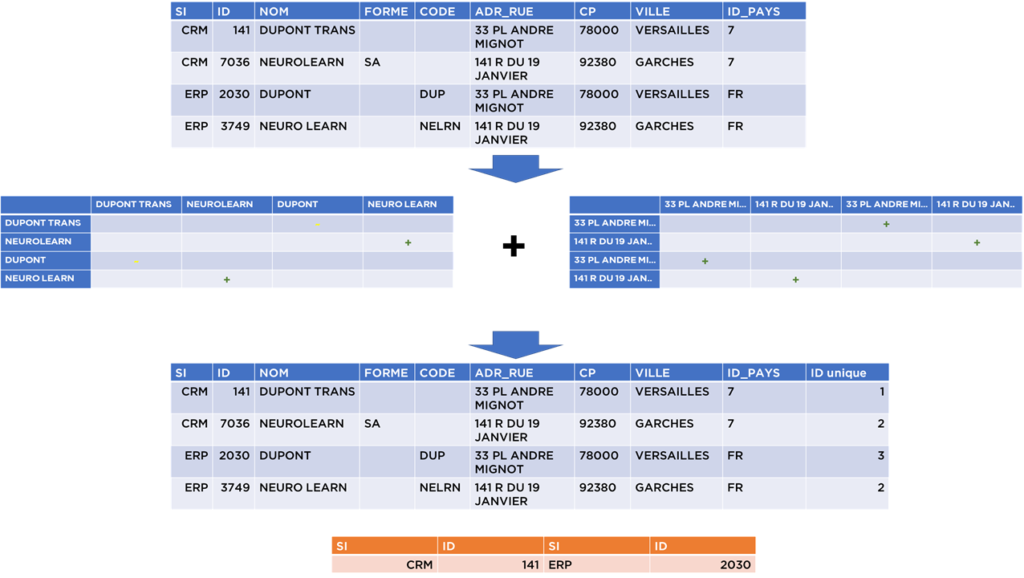
- Suite à nos traitements, nous pouvons maintenant remplacer les clés étrangères vers la table « pays » afin d’utiliser les identifiants internes à notre modèle (on aurait pu le faire avant, cela ne change pas la logique de notre traitement) :
- Maintenant nous pouvons constituer le golden record, i.e. dédoublonner (nous utilisons dans notre exemple les règles de gestion « prendre la valeur la plus longue ») :
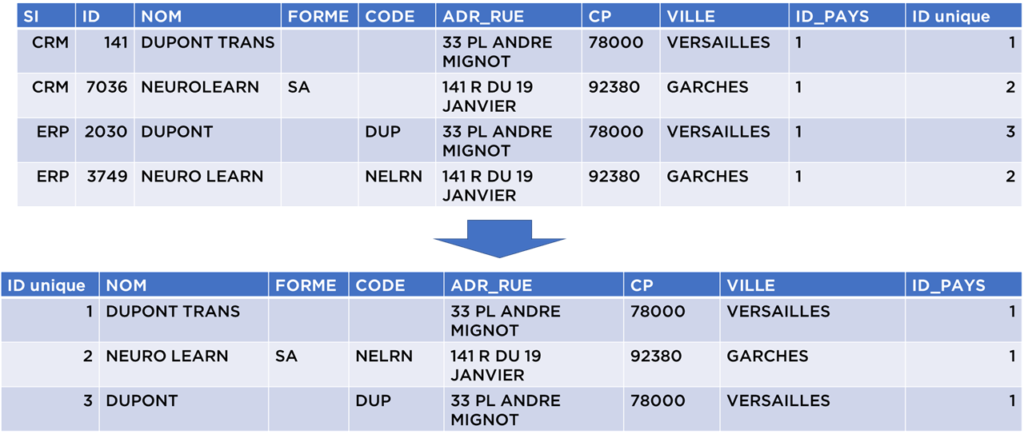
La table obtenue avec la table de transcodification peuvent être publiées pour être utilisé dans le reporting, l’analyse avancé, le ML, etc :

Le même processus peut être appliqué pour l’ensemble des modèles des votre société – en partant de la nomenclature (pays, devises, types de clients) jusqu’aux transactions (factures, paiements, appels, achats, etc).
A bientôt
Ce n’est que le première épisode, dans la suite de cette série, nous verrons ensemble chaque étape en détail. En espérant, évidemment, que cela soit utile pour vous et pour vos projets.
Bonne santé à vous et à vos systèmes.