
When falsehood can look so like the truth, who can assure themselves of certain happiness?
Mary Shelley, Frankenstein
Cet article est la suite de notre série sur la consolidation de données. Aujourd’hui, nous aborderons la détermination de la « golden record » (seule version de la vérité), et les étapes pour y parvenir :
- transcodification des clés étrangères
- dédoublonnage
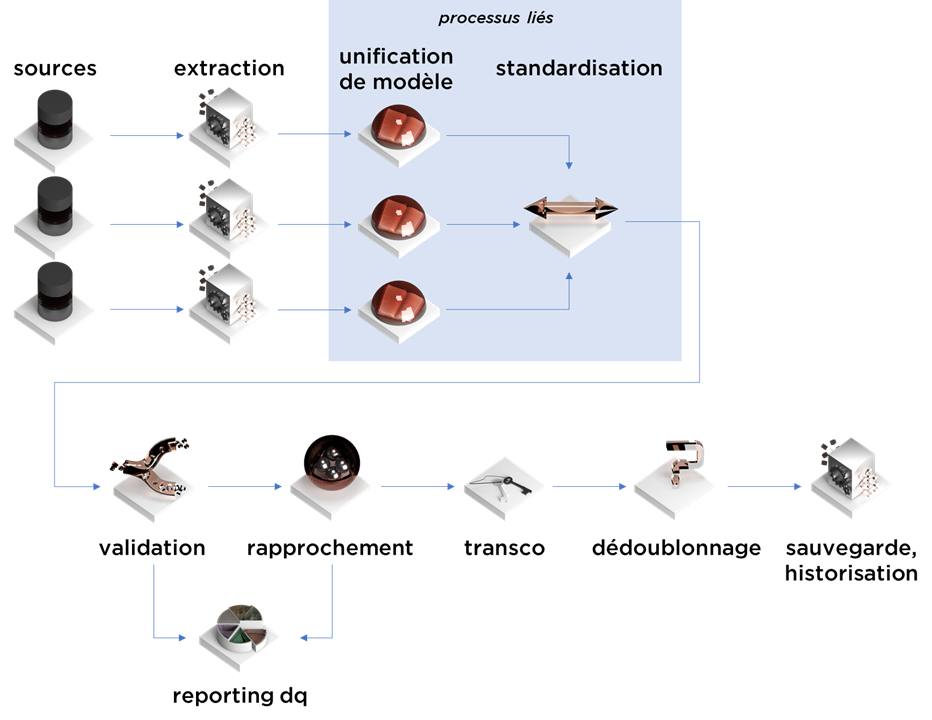
Transcodification (remplacement) des clés étrangères
Le remplacement des clés étrangères est une procédure qui peut être exécutée à tout moment (même avant la standardisation, ne vous attardez pas trop sur le schéma). En revanche, c’est une opération très technique et purement mécanique, ainsi, je ne souhaitais pas en parler trop rapidement.
Si vous consolidez les données depuis plusieurs sources, avant le remplacement des clés étrangères vous avez une structure avec une table contenant les IDs de différents systèmes sources (par construction). Si vous souhaitez un modèle de données homogène, vous devez les unifier et remplacer par une seule version d’ID (que vous avez déjà calculé).
Par exemple, dans le cas des données pays, suite au rapprochement, vous avez obtenu une table de transcodification des IDs des pays vers les IDs uniques (internes à votre solution). Dans ce cas, si vous traitez les données d’adresses, vous devez remplacer les clés étrangères qui pointent vers les pays :
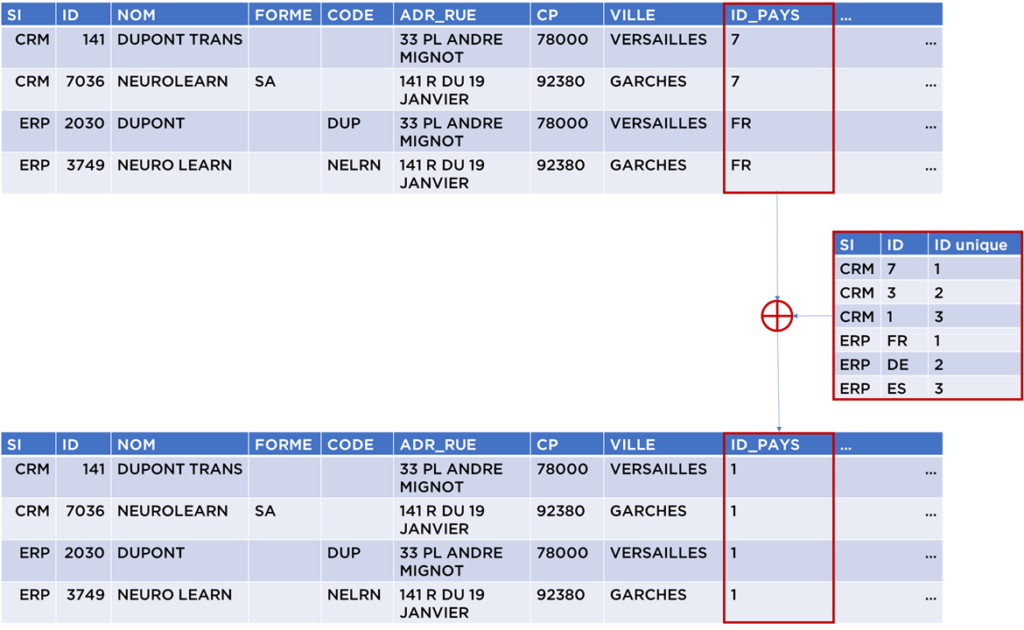
Dans le domaine de la BI, nous avons pour habitude de remplacer les clés étrangères en faisant la jointure avec la dimension par une clé fonctionnelle. Mais, dans ce cas, la clé fonctionnelle est présente :
- dans le traitement du chargement de la table en question ;
- dans tous les traitements qui utilisent la table en question.
C’est une violation du principe dit SoC (Separation of Concerns) – ainsi, vous allez payer très cher si la clé fonctionnelle était amené à changer…
Il est important à noter que, dans certaines situations, nous pouvons faire face à des clés que nous n’avons pas encore vu lors du rapprochement. À titre d’exemple, la clé « XX » ne pourra pas être remplacée étant donné qu’elle n’est pas présente dans la transcodification des pays. Il faut les traiter comme des clés inconnues (ex. remplacer à null) puis avertir les Data Stewards / utilisateurs qu’il existe des données potentiellement erronées.
Dédoublonnage
C’est le processus de calcul d’une seule version de données qui représente tous les doublons identifiés à l’étape de rapprochement.
« Seule version de la vérité » (golden record) n’est pas toujours « la vérité » car il s’avère que nos algorithmes n’ont pas toujours la possibilité d’identifier les contextes de modification.
Supposons que vous consolidez les données personnelles et vous tombez sur les doublons potentiels d’une seule et même personne. L’algorithme de rapprochement les ayant identifié comme tels. Dans l’un des deux cas, le nom est « Maria Dupont », alors que dans le deuxième cas c’est « Maria Martin ». Quel nom doit être utilisé pour établir la « golden record » ?
Il est clair qu’ici nous avons un cas de changement de nom de famille, mais quel est le nom « actuel » ? Quel est le nom de naissance ? Nous pouvons ne pas avoir cette information. Il peut se passer que les SI source ne tracent pas la data de modification (en tout cas, pas champ-par-champ), nous retrouvant ainsi sans la possibilité de connaître l’ordre de saisie des données.
Modes
Souvent, le dédoublonnage s’exécute automatiquement en batch de consolidation. Si c’est le cas dans votre SI, vous devez avoir à l’esprit qu’il ne faut surtout pas redescendre cette version consolidée dans le même SI d’où viennent les données (règle « aval n’est pas amont ») car :
- le batch est asynchrone, donc durant le calcul vous avez seulement un « snapshot » de données à un moment T, alors si entre la consolidation précédente et ce moment T, il y a eu plusieurs modifications de données, il peut être compliqué à rétablir l’ordre et le contexte de chaque modification ;
- si vous utilisez certains algorithmes de dédoublonnage (par exemple – prendre le nom le plus fréquent), dans le cas de triplons, à chaque consolidation, le SI qui a fait des modifications de données va les perdre car la majorité va « voter » contre cette nouvelle version.
Pour conclure là dessus, pour pouvoir descendre les données consolidées vers les mêmes SI (donc mettre à jour les sources), vous devez faire un système bien plus complexe, « transactionnel » (en temps réel ou presque – via micro-batches), pour tracer chaque transaction.
Si c’est votre cas, ayez en tête que votre dédoublonnage se passera très probablement en mode « manuel », i.e. au moment d’identification d’un doublon, nous allons choisir les données « correctes » et on va supprimer / désactiver les doublons. Si cela se passe automatiquement, vous allez perdre les données sources – et en plus, sans contrôler lesquelles. Un vrai chemin de croix cette aventure..
Pour les autres projets, on propose une liste de règles de dédoublonnage applicables « en batch ».
Règles de dédoublonnage automatique
Quand nous devons choisir une seule version de données pour les doublons identifiés, nous « créons » une nouvelle version – version Frankenstein.

Voici les tactiques qui sont souvent utilisées durant le choix des valeurs pour la version finale :
- Première valeur non-nulle.
La solution la plus basique, mais elle peut fonctionner dans les situations quand il y a peu de doublons et il y a peu de différences entre les systèmes. - Valeur la plus longue/plus courte.
Technique utile pour approximer le choix de données les plus complètes. Le risque c’est de prendre les données les plus bruitées. - Valeur la plus fréquente.
A noter que cela fonctionne que si le nombre de doublons est suffisamment important (i.e. 3 doublons et plus). - Valeur plus récente.
Si vous avez des données horodatées, vous pouvez toujours utiliser les données les plus récentes. Vérifiez juste que durant la modification, les utilisateurs contrôlent correctement les données (et ce n’est pas le changement de statut qui déclenche la mise à jour). - Première valeur correcte.
Cette approche peut fonctionner si vous avez un moyen pour valider les données (ex. code SIREN/SIRET/TVA/numéro de téléphone/numéro de passeport, sécurité sociale, autres documents/etc). - Priorité par système source (propriétaire de données) :
- …soit le système est la première source de données, donc il y a une raison de croire que c’est là que se trouvent les données les plus correctes,
- …soit les utilisateurs du système ont la priorité par rapport aux autres pour l’objet en question (ex. système financier pour un client qui a des contrats encours).
- Recomposition.
Techniquement, vous pouvez recomposer le texte court / les libellés / les noms de sociétés à partir de plusieurs lignes de caractères, i.e. diviser chaque version en tokens (mots), choisir certains tokens et recomposer la nouvelle ligne à partir de tokens obtenus. Le seul risque de cette opération c’est que l’ordre final de tokens peut être difficile à établir (surtout si il y a des mots manquants).
Exemple : « Bolloré Transp et Logistique » + « Bolloré Transport & Log » = Bolloré + (Transp ou Transport) + (et ou &) + (Logistique ou Log) = « Bolloré Transport et Logistique ». La version finale ne correspond à aucune valeur d’entrée. - Valeur la plus probable.
C’est une version avancée du dédoublonnage. Vous allez avoir besoin d’un « modèle d’erreurs » pour choisir, parmi les valeurs potentielles, la valeur la plus probable.
Exemple : Nous rencontrons un doublon « Mari » vs « Maria ». Supposons que la probabilité de faute de frappe est 0,02, les fréquences des mots sont fréq(Mari) = 0,0001 et fréq(Maria)=0,01.
Si la vraie donnée est « Mari », nous observons un cas rare (probabilité 0,0001) et une faute de saisie dans la version « Maria » (probabilité 0,02). Donc, les chances que la vraie donnée soit « Mari » est ~0,000002 (*).
Pour « Maria », de la même manière, nous pouvons obtenir la probabilité ~0,0002 (*).
Pour ce modèle et ce cas la version « Maria » gagne.
Par contre, si nous observons un triplon avec deux fois « Mari » et une fois « Maria », c’est « Mari » qui va gagner (0,0001 x 0,02 = 0,00002 vs 0,01 x 0,02 x 0,02 = 0,000004).
(*) « probabilité proportionnelle à », car ici pour faire correctement, il faut normaliser le résultat, sans que cela change grand chose. De même, il faut multiplier par 0.98 x nombre-champs-sans-erreur, mais ça ne changera pas le résultat non plus.
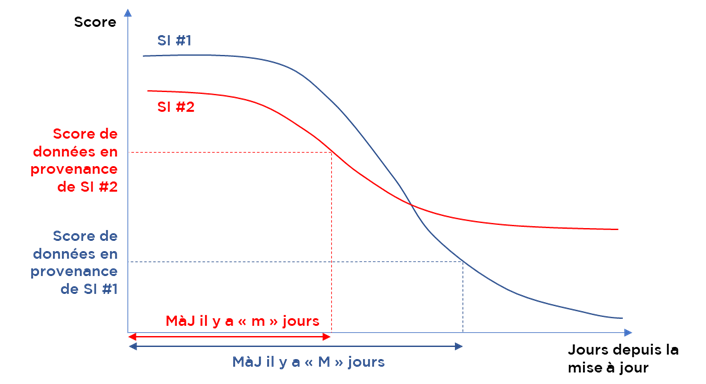
- Priorité pondérée par système et date de mise à jour.
Certains outils utilisent les courbes de dégradation d’importance après la date de modification. I.e. à chaque valeur nous pouvons assigner un score de certitude que les données sont « encore bonnes dans le SI donné » (chaque SI peut avoir sa propre courbe) et dans le temps nous allons réévaluer ces scores, puis choisir les valeurs avec les scores élevés.
Le seul problème avec cette approche, c’est que c’est pas très clair, car comment établir ces courbes sans utiliser des nombreux exemples et du ML.
Note : vous pouvez évidemment combiner les approches et utiliser différentes techniques pour différents champs.
Note : certains valeurs représentées par plusieurs champs peuvent être « indivisibles ». Par exemple, il ne faut pas que, durant le dédoublonnage, vous preniez la ville d’une adresse donnée afin de la combiner avec le code postal d’une autre.
Note importante. Si vous n’avez pas bien normalisé la structure de données, vous pouvez avoir des problèmes. Par exemple, dans les données des sociétés (clients/fournisseurs) vous avez deux champs PHONE1 et PHONE2. Si vous constatez un doublon, vous allez vous retrouver (potentiellement) avec quatre téléphones (une société peut en avoir plusieurs). La question qui va rapidement se poser « quel téléphone garder » est incorrecte – il faut conserver les quatre (ou autant qu’il y a) en faisant « sortir » les téléphones / mails / faxes / etc pour les regrouper dans un objet « moyens de contact ».
Exemple de la règle « 0, 1 ou infini » en action !
Surchargement
Avec ce mode, vous obtenez un résultat « presque bon », mais il reste un nombre de cas « à corriger ». C’est généralement à ce moment que le chef de projet propose une idée de « surchargement ».
Voici l’idée :
- il est possible de consolider les « golden records en automatique » ;
- il faut créer une interface (UI graphique / fichiers / etc) qui permet aux utilisateurs de corriger les cas restants.

Voici le premier sentiment que j’ai :

Pourquoi il faut réfléchir encore une fois ?
- vous pouvez probablement modifier les données à la source – dans ce cas c’est la meilleure solution car vos SI vont profiter de votre effort d’analyse de données – et en prime, vous n’avez pas besoin de complexifier les traitements ;
- posez la problématique et vous allez vous rendre compte qu’il est probable que ce ne soit pas si gênant d’avoir quelques cas erronés, en comparaison avec l’effort de dev à fournir pour les régler ;
- même si vous décidez se lancer vers le surchargement, il faudra répondre à certaines questions :
- À quoi se colle exactement le surchargement quand les données continuent de vivre ?
- Est-ce que le surchargement est perpétuel, i.e. si en futur les données se changent dans SI source, faut-il le lever ? Si oui – comment vous allez identifier ce cas ?
- Si le « golden record » est issu du groupe qui contient des faux positifs, faut-il supprimer le surchargement durant le split ?
- Si on identifie encore un objet à mettre dans le groupe de doublons (faux négatif), faut-il lever le surchargement ?
Comment faire (assez) bien sans se casser la tête ?
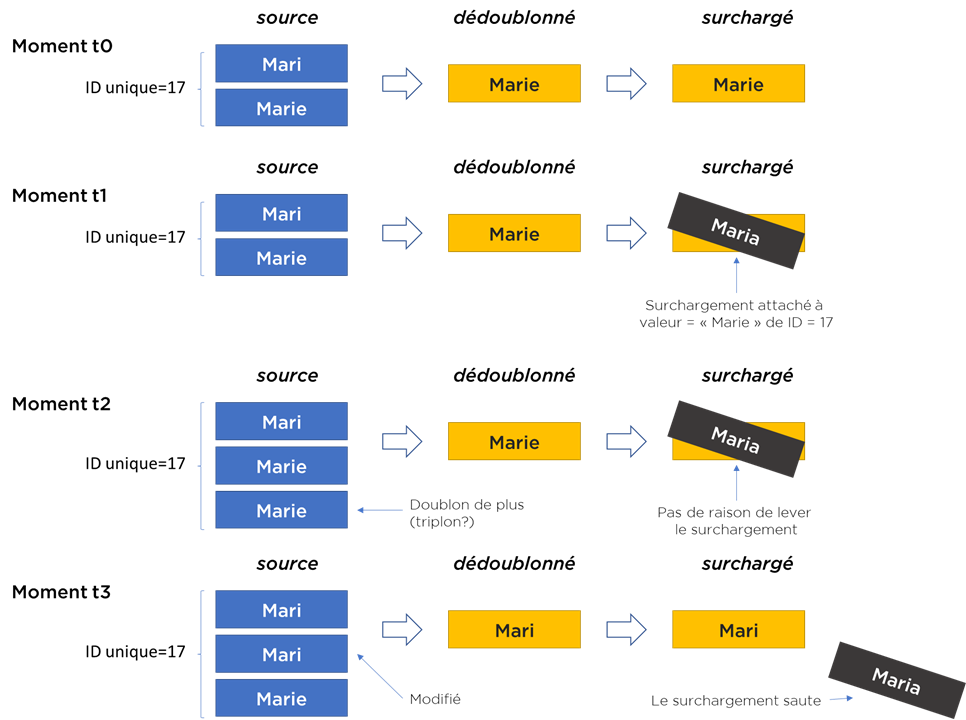
- Nous pouvons coller le surchargement à l’ID unique obtenu après le rapprochement (si vos IDs sont stables et ne se changent pas d’une exécution à l’autre) et sur la valeur surchargée.
- Nous allons continuer à surcharger tant que le résultat de dédoublonnage reste le même (malgré les changements potentiels dans le contenu de grappe de rapprochement).
Voici un exemple – le surchargement « saute » que si la valeur se modifie :
Conclusion
Une fois le rapprochement fini, le reste de traitement sera assez mécanique si vous suivez l’algorithme.
Une seule chose à se souvenir c’est que vos utilisateurs ne seront jamais satisfaits à 100% des résultats issus d’un dédoublonnage automatique – c’est à vous d’être patient et pédagogue.
Bonne santé à vous et à vos systèmes.