
Cet article est le deuxième épisode d’une série démarrée la semaine dernière sur la consolidation de données. Après l’introduction, voici l’extraction.
Pour rappel, voici les étapes du processus de consolidation :
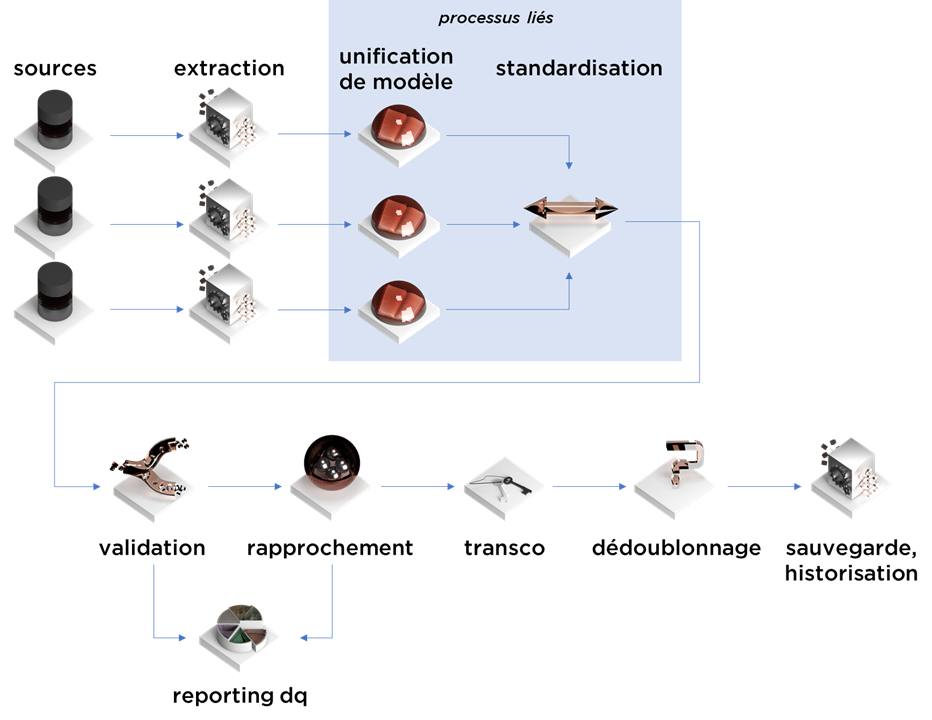
Il faut avoir à l’esprit qu’assez souvent l’extraction est considérée comme une technicité non-relevante et n’est pas prise en compte durant la spécification du futur processus. Comme souvent, la réalité est bien plus complexe.
Sujet 1 : les métadonnées
Supposons que dans votre écosystème, il y a N systèmes informatiques qui contiennent l’information dont vous avez besoin. Partons du postulat que vous avez même l’accès aux IHMs d’applications et aux bases de données.
Dit ainsi, il reste juste à comprendre le modèle de données et hop – nous pouvons déjà spécifier l’extraction !
Dans ma carrière, je n’ai jamais eu de problèmes avec les modèles de données (même assez tordus) jusqu’à un projet qui m’a donné du fil à retordre et qui a nécessité de longues heures de reverse-engineering. Imaginez un système où la différence entre un contrat et un client est un simple flag, i.e. les clients, contrats, détails de contrats sont stockés dans une seule table. Ainsi, c’est à vous (seul) de déduire comment ces éléments sont liés ensemble. Inversement, les détails transactionnels sont stockés dans les varchars en forme de XMLs et JSONs. De plus, si vous n’avez (presque) aucune documentation et (presque) aucun moyen pour avoir des détails supplémentaires (soit les sachants ne sont pas disponibles, soit ils répondent une fois par mois), vous aurez beau maîtriser le sujet sur le bout de doigts, prévoyez des mois de reverse-engineering du modèle de données (multipliez par trois si le système est encore en cours de développement par une société tierce).
Conclusion de cette histoire :
- dès le début apprenez à connaître les objets fonctionnels majeurs et leurs définitions ;
- si devant vous il y a un système, n’hésitez pas à demander un modèle technique afin de faire un premier mapping conceptuel de ce modèle avec les objets fonctionnels majeurs ;
- systématisez vos découvertes, conditions et règles de gestion ;
- commencez le draft d’extraction de données le plus vite possible pour vérifier que le modèle ressemble à ce que vous attendez ;
- mettez en place les processus qui vérifient que les hypothèses majeures sont toujours correctes (modèle ne se change pas, pas de clés cassées, les clés qui doivent être uniques sont toujours uniques, il n’y a toujours pas de nulls dans les champs qui « ne doivent jamais être vides, promis », que la volumétrie de données ne se change pas dramatiquement d’un livraison à l’autre, etc).
Bref, spécifiez tout ce que vous découvrez, même les encodages des fichiers que vous allez recevoir si l’intégration passe par des fichiers.
En partie, votre travail peut être simplifié par des outils de type « governance catalog » (catalogues des définitions métiers, des règles de gestion/DQ, des métadonnées techniques et des liens entre ces domaines), mais pour le moment je n’ai pas rencontré d’outil qui couvre l’ensemble des besoins de gestion de métadonnées et qui vous permettrait de ne plus utiliser de fichiers Excel pour la documentation…
Sujet 2 : les outils
Actuellement, la grande majorité des processus de consolidation fonctionne en mode « batch » (pas en temps réel donc), c’est à dire : à une heure précise, il y a un processus qui se lance et commence à envoyer de l’information.
Pourquoi c’est le cas ?
- Il y a une vraie différence entre le traitement des « évènements » en temps réel (qui a un nombre de règles appliquées assez limité) et la consolidation de données, où pour une structure de trentaine de tables, vous aurez plusieurs centaines de règles de gestion, qui seront obligatoirement changées durant le projet, avec un certain besoin de « reprise d’ensemble de données juste une dernière fois ».
- Une autre raison est que durant la consolidation on touche souvent les modèles de données qu’on ne contrôle pas, alors il est fort probable qu’un jour nos flux ne fonctionneront plus comme prévu, donc il faut être prêt d’apporter une correction à tout moment et… « faire encore une reprise complète ».
Cela veut dire que les flux seront certainement réalisés en se basant sur un modèle « ETL » soit avec les outils ETL/ELT (DataStage, IDQ, PowerCenter, ODI/Stambia, etc), soit en forme de code (Spark, SQL, etc) qui fonctionnera de-facto en mode « batch ».
Par contre, il existe quand même certaines situations, par exemple une volumétrie très importante, où la volumétrie des données fait que nous devons traiter uniquement les deltas journaliers. Dans ce cas, il faut se tourner vers les outils de type CDC (Change Data Capture) :
- Change Data Capture classique – un outil qui peut, en lisant le log des transactions de la base de données, détecter les transactions qui viennent de se commiter et envoyer ces données instantanément à l’outil qui est prêt à les traiter (ou les sauvegarder dans une base horodatée) ;
- Change Data Capture basique – l’approche où sur chaque table volumineuse nous ajoutons un trigger qui sauvegarde les IDs et les timestamps des lignes modifiées dans un fichier ou dans une autre table (votre DBA peut être contre cette idée) ;
- Capture d’insertions pour Oracle et Informix – ces deux bases de données permettent l’utilisation des champs techniques (ORA_ROWSCN, CDRTIME) qui permettent d’identifier les dernières lignes ajoutées (modifiées).
Une solution intermédiaire entre « utiliser CDC » et « traiter tout » est bien connue – nous pouvons calculer les deltas nous-mêmes à la condition que nous avons la possibilité d’extraire la totalité de la table et préserver sa copie de la veille :
- Extraire le contenu de la table ;
- Exécuter un « full outer join » entre cette table et sa copie d’exécution précédente par une clé unique (primaire ou fonctionnelle) ;
- Pour chaque ligne de résultat de join il existe 4 possibilités :
- les données existent dans l’ancienne table, mais pas dans la nouvelle – ce sont les « suppressions » de la journée ;
- à l’inverse les données existent dans la nouvelle table mais pas dans l’ancienne – ce sont les « insertions » de la journée ;
- les clés existent de deux côtés, mais dans les valeurs il y a une différence sur au moins un champ (hors la clé) – ce sont les mises à jour (rare pour des tables vraiment volumineuses) ;
- les clés existent de deux côtés et il n’y a aucune différence au niveau de valeurs – c’est la majorité de données – ce sont les données non-modifiées.
Pas d’économies sur l’extraction, mais prévoyez d’économiser le temps sur la suite du traitement (https://ithealth.io/boostez-la-performance-de-vos-flux-10x/).
Le seul problème de cette méthode est qu’elle est assez coûteuse en termes de temps de calcul car nous faisons au moins une extraction complète (temps O(n)), tri de données pour le « full outer join » (temps O(n*log(n) – et ça utilisera le disque), jointure et filtre (temps O(n)). Si vos données sont assez volumineuses, la tri de données sera la partie la plus lente (pour plus d’info, googlez « external sorting »).
Sujet 3 : la Landing Area
D’autres questions à propos de l’extraction concernent le résultat de cette opération (Landing Area), il est vrai que nous avons le choix :
- matérialiser les résultats d’extraction en forme de tables dans une base de données (seul choix si vous utilisez ELT, CDC ou processus incrémentaux) ;
- matérialiser les résultats en forme de fichiers temporaires internes à votre processus (DataSets de DataStage, Parquet, Avro, ORC, etc).
La création d’une Landing Area dans une base de données est une charge supplémentaire qui implique des livraisons plus complexes, mais les Landing Areas matérialisées dans une base de données (ou dans Hadoop, dans ce cas on parle de Data Lake) peuvent vous aider à mettre en place une solution plus robuste.
Le choix dépend de la complexité de votre projet, de la volumétrie, de la disponibilité de systèmes, des besoins de traçabilité et de débogage, etc.
En général, si vous avez besoin d’outils de débogage avancés ou si vos SI sources ne sont pas toujours disponibles (ou envoient parfois des fichiers incorrects) ou vous voulez mettre en place des flux incrémentaux – créez le modèle de votre Landing Area dans une base de données.
Si nous avons décidé de matérialiser le modèle de Landing Area, il faut aussi décider, comment nous allons la modéliser :
- nous pouvons reprendre le modèle source et y ajouter l’horodatage ou (optionnellement) l’historisation (oui, ça existe – Landing Area historisée), mais le problème est que avec N SI sources différents nous pouvons avoir besoin de N modèles de Landing Areas ;
- sinon, nous pouvons combiner l’étape d’extraction et de mapping de données vers un modèle universel et stocker les données dans un seul landing area.
Le choix dépend de votre capacité de modélisation, de la différence entre les modèles (et donc complexité de mapping), etc. Avec un Landing Area universel vous gagnez en productivité, mais vous perdez potentiellement en capacité de reprise de données. Le risque d’erreurs de modélisation au niveau de ce modèle est assez important.
Sujet 4. Real time vs micro-batches
Il existe une tendance vers la consolidation rapide (pour les besoins des Data Hubs intégrés, par exemple).
Si c’est votre cas, le batch de nuit ne sera pas probablement suffisant. En même temps, nous avons vu ensemble que la consolidation en temps réel peut être assez complexe : dès l’étape d’extraction si vous n’êtes pas équipés avec de bons outils de Change Data Capture et/ou bien à cause de besoins de reprise de données.
L’alternative sera de se préparer dès le début à la consolidation en micro-batches, i.e. faire en sort que les données critiques peuvent se mettre à jour rapidement (- de 30 minutes). Si c’est le cas, vous pouvez faire tourner la partie de vos flux dans la journée toutes les 20 min par exemple et les compléter avec les données « moins urgentes » durant la nuit.
Cette approche fonctionne et vous évitez l’utilisation d’approches plus complexes qui peuvent nécessiter les fils de messages (RabbitMQ, Kafka, MQ series, etc) et tous les problèmes liés à l’exécution asynchrone.
Pour conclure…
Les sujets d’extraction de données peuvent impacter l’architecture de votre solution de consolidation. Soyez prudents.
Bonne santé à vous et à vos systèmes.