
Aujourd’hui je voudrais analyser avec vous un sujet très spécifique – l’historisation des données.
Pour commencer, à quelle moment parlons-nous d’historisation ? Lorsque un système donné (ERP, CRM ou entrepôt de données) préserve l’historique du changement de données, dit autrement, le système ne garde pas seulement la version actuelle de l’information, mais également les versions plus anciennes. En quelque sorte, cela vous permet de « remonter dans le temps » afin d’accéder aux données telles qu’elles étaient il y a un jour, il y a un mois, il y a un an.
Pas si simple en réalité…
L’historisation est une approche des plus classiques qu’on apprend dès les premiers jours en BI. Cette notion figure même dans la définition d’un entrepôt de données, donc nous pouvons supposer que ce sujet est important et correctement étudié…
Voici comment le sujet est présenté par l’équipe ERP :
- Il faut créer une table supplémentaire à l’image de la table que nous voulons historiser et ajouter un champ pour garder la date de la modification.
- Créer un trigger (morceau de code) qui, au moment de la modification de la table historisée, va copier les données dans la table « Historique ».
- C’est tout !
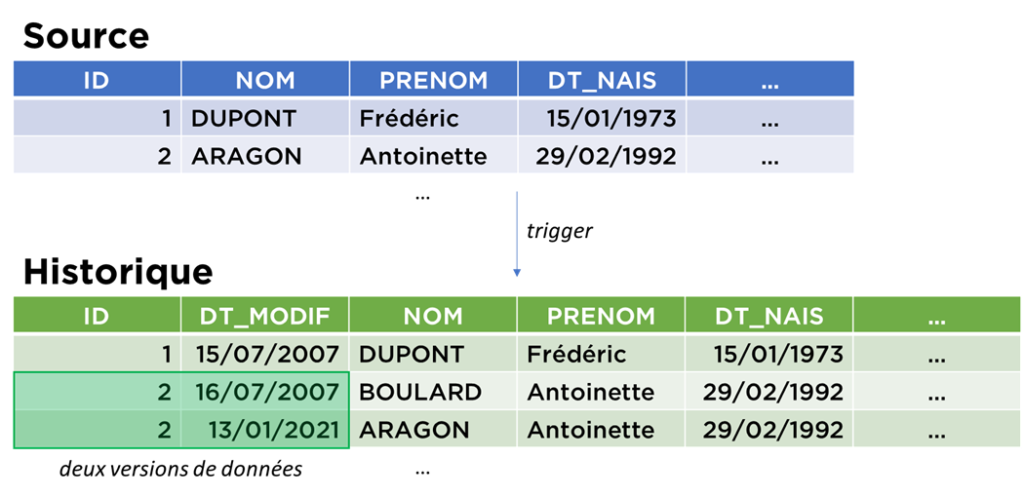

Côté équipe DWH , l’approche n’est pas très différente, sauf que le trigger est remplacé par un flux (souvent ETL, parfois Change Data Capture).
Le guru de BI, Ralph Kimball, disait même que l’historisation est un processus quasi-obligatoire pour les dimensions (toutes tables descriptives) d’un entrepôt de données.

Enfin, l’approche Data Lake, l’historisation se trouve aussi dans la définition, mais en plus – à cause de contraintes technologiques liées à Hadoop – il est beaucoup plus facile d’ajouter des données que de les mettre à jour…
Pour aller plus loin Spécifiquement pour les personnes expérimentées : il existe plusieurs façons de préserver l’historique mais en réalité, le principe utilisé est plus ou moins le même. Dans la plupart des cas, l’unique changement concerne les champs techniques – en plus de l’habituelle date de modification, il est possible d’ajouter la date de fin de validité, un flag d’actualité, la référence à la version actuelle, un numéro de version, la version précédente des données, type de modification (I/U/D), etc.
Identification des premiers symptômes
Signe 1. La vitesse de changement des données est très différente. Dans notre exemple précédent, nous avons vu que :
- la personne peut changer le nom de famille et c’est assez probable (mariage / divorce),
- le changement de prénom est peu probable (pourtant possible),
- le changement de la date de naissance n’est pas vraiment un changement – ça sera un ajustement de données incorrectes.
Nous pouvons continuer encore longtemps. Pour des informations liées à l’état civil, c’est déjà susceptible de bouger alors imaginons un instant la vitesse du changement d’un numéro de téléphone, d’un e-mail, d’une adresse, ou encore de sexe (SI dans le domaine de la santé) !
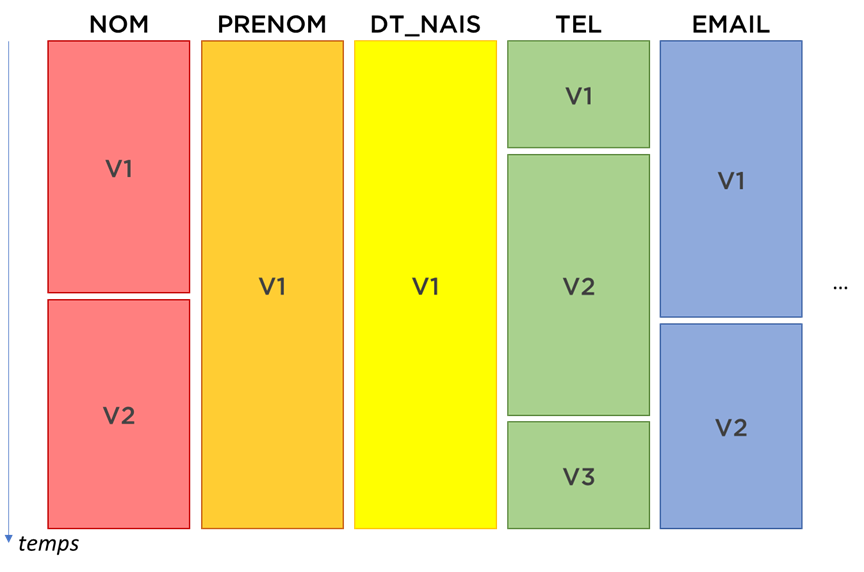
Plusieurs solutions ont été proposées, mais retenons les « mini-dimensions » de Kimball – diviser la table en plusieurs parties, chacune avec sa propre vitesse de changement…
Signe 2. Et les liens entre les versions ?
Tant qu’on considère qu’une seule table sans clé étrangère, il peut sembler que notre approche ne présente pas de défauts importants. Voyons ce qui se passe si Antoinette BOULARD ép ARAGON de notre exemple précèdent dispose d’un contrat (que nous voulons également historiser) :

Le problème est que nous ne pouvons pas vraiment faire des jointures entre ces deux tables, i.e. les données sont présentes, l’historique est préservée, mais cela reste difficile à exploiter. Pourquoi ? Car si nous faisons une jointure « simple » par ID=CUST_ID, nous allons obtenir un produit cartésien.
Pour aller plus loin Il est évident que nous pouvons faire cette jointure avec du SQL (surtout si nous ajoutons la date de fin de validité). En revanche, la requête sera bien trop complexe et la performance ne sera pas au top car techniquement le produit cartésien aura lieu dans le plan d’exécution de la requête :select ... from cli_hist, contr_hist
where cli_hist.ID=contr_hist.CUST_ID and cli_hist.DT_MODIF<contr_hist.DT_FIN_VAL and cli_hist.DT_FIN_VAL>contr_hist.DT_MODIF
En même temps, il n’y a pas de moyen évident pour relier ces deux tables car les modifications ne se font pas au même rythme :
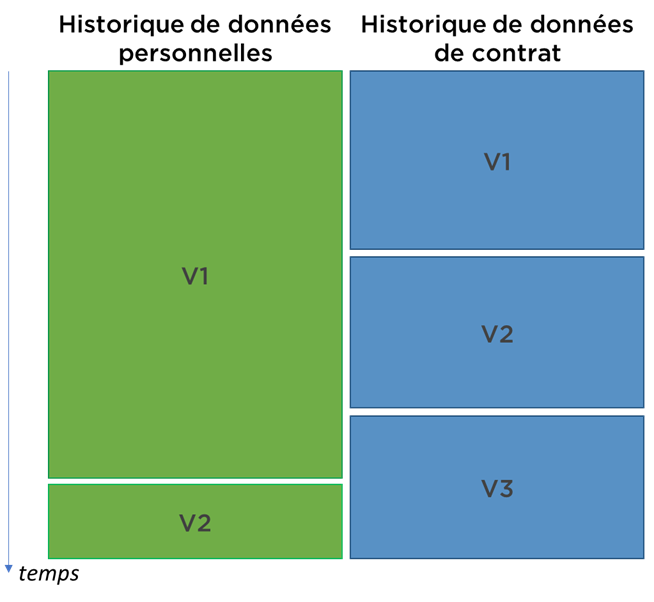
Ce que nous pouvons faire c’est d’attribuer un ID à chaque version de données personnelles et faire référence à ces données :
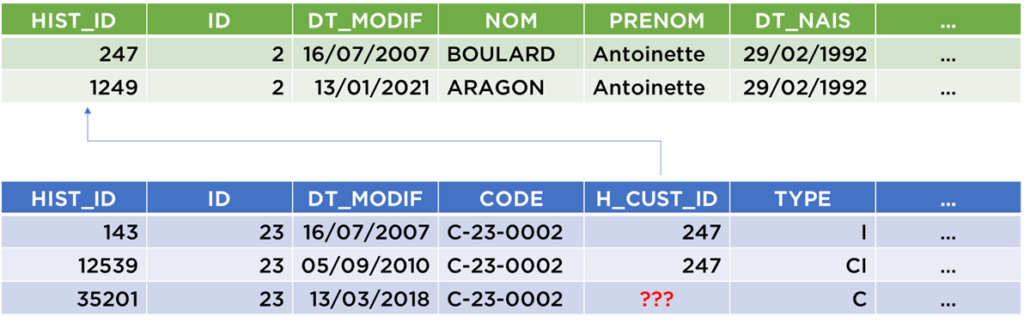
Par exemple, nous avons un problème avec l’ID sur la dernière version du contrat. Dilemne, devons-nous garder l’ID 247 car en mars 2018, Madame BOULARD était encore Madame BOULARD ou devons-nous mettre l’ID 1249 car c’est la version la plus récente de données et donc c’est le nom Madame ARAGON qu’il faut utiliser désormais ? Probablement, il aurait fallu créer une nouvelle version du contrat lorsque Mme BOULARD a communiqué l’information qu’elle s’appelait désormais Mme ARAGON ?
Voici les trois possibilités pour cette dernière partie d’historique :
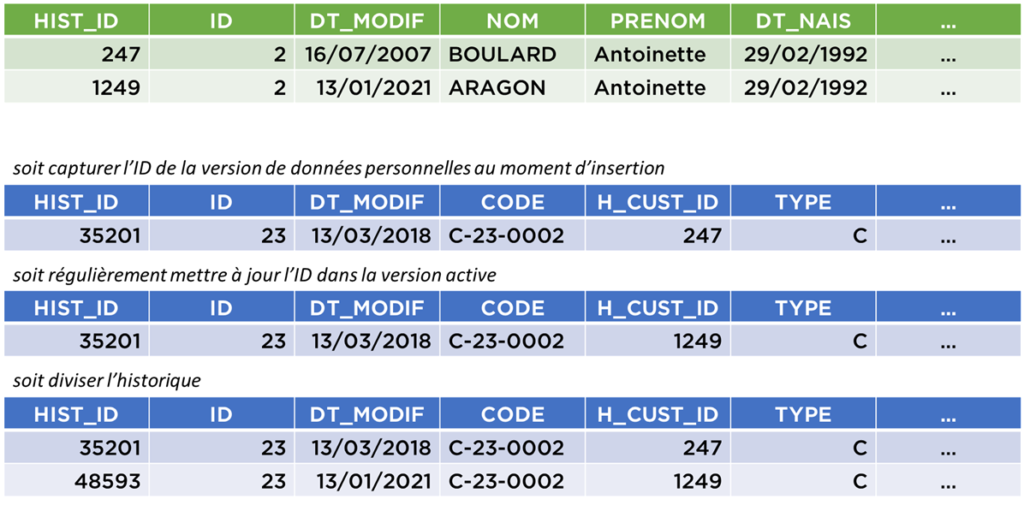
Les deux premières décisions sont pour le moins étranges et semblent ne suivre aucune logique précise (pourtant c’est la première solution qui a déjà été conseillée par certains experts). Il nous donc reste la troisième solution, mais avec cette solution, nous allons vite arriver à l’explosion par augmentation incontrôlée de nombre de versions générées…
Prenons un exemple avec une société de crédit-bail (financement) :
- Vous avez besoin de gérer :
- vos clients,
- vos contrats,
- par contrat – plusieurs simulations / versions,
- pour chaque simulation ou version – les mensualités (en moyenne 48).
- Comment se passe l’historisation :
- un client change de téléphone, un attribut civil ou un statut,
- cela génère une version historisée du contrat,
- cela génère 1 ou 2 versions de versions du même contrat,
- cela génère 48 nouvelles versions de mensualités.
- Nous avons « amplifié » le changement d’attribut jusqu’à la sauvegarde de 48 lignes (qui n’ont pas été modifiées, en fait).
Un autre exemple. Supposons que vous travaillez pour une société internationale et historisez tout, même la nomenclature, donc voici ce que se passe : en 2019, tout client présent en Macédoine a été « versionné » car le pays a changé le nom (Macédoine du Nord), même chose pour la Birmanie (Myanmar); en 2018, vous avez fait la même chose avec Swaziland (Eswatini); en 2017 – avec la Lybie, etc.
Mais est-ce si important que ça ?
Après ce cauchemar de modélisation, on se pose la question si c’est vraiment important d’historiser toutes données. C’est la question que j’ai posé à la communauté LinkedIn :

Probablement la réponse est « non », avons nous besoin d’historiser tout si nous allons toujours, ou du moins très souvent, n’utiliser que la dernière version ?
Si nous avons un besoin particulier de voir les versions précédentes (pour des raisons autres que analytiques), nous pouvons probablement disposer pour ce cas précis, d’un schéma basique séparé tel que vu au début de l’article ?
Granularité et les axes de temps
Il existe encore quelques problèmes avec l’historisation (aussi fréquemment ignorés), notamment avec le temps d’historisation, car il en existe plusieurs axes :
- l’axe temps de SI transactionnel (vous ne le voyez pas si le SI ne fait pas d’historisation ou si vous n’utilisez pas d’outils de Change Data Capture pour recevoir les transactions au moment des modifications de données) ;
- l’axe temps de Staging Area / Landing Area (ou Data Lake) – le moment de la lecture de données depuis un SI source – vous pouvez être en retard de plusieurs heures sur celui-ci ;
- l’axe temps d’ODS (si vous l’utilisez) – le moment de la consolidation des données (proche à l’axe temps de la Staging Area, sauf si il y avait des flux bloqués à cause d’erreurs techniques et dans ce cas le délai peut être de plusieurs jours),
- l’axe temps de DWH – proche à l’axes SA ou ODS, sauf pour les cas d’erreurs de chargement.
En réalité, la plupart du remps, ce n’est pas très important d’être très précis avec l’historisation. Nous pouvons ignorer que le temps de transaction est différent de moment d’historisation, mais parfois ça change tout – surtout si vous suivez les processus relativement rapides en utilisant ces techniques.
Exemple. L’usine YW doit produire la voiture X avant la date Y. Nous capturons les statuts de l’état de la production afin de comprendre, quand la voiture a été produite. Le planning est serré, la voiture X est produite le jour Y même, mais notre flux se lance à 23h00 et charge péniblement la table de suivi jusqu’à 00h30 du jour Y+1. Nous historisons le changement de statut le jour Y+1, il existe donc un décalage entre la planification et la production au niveau de reporting.
Un autre sujet c’est la granularité d’historisation. Si nous capturons les données 1 ou 2 fois par jour, il peut se passer que certains changements ne soient jamais capturés. Voici pourquoi :
Exemple. La ligne de production capture le statut de la voiture en utilisant une puce RFID. Les statuts doivent changer dans l’ordre 1->2->3->…->11. Le système préserve seulement le dernier statut. Vu que notre processus d’historisation se lance qu’une fois par jour, nous avons tracé les statuts 3, 7 et 11 seulement pour la voiture X. L’analyse qui suppose que dans la table il y aura tous les statuts peut être incorrect (ex. select DATE from SUIVI where STATUT=5 and VOITURE=X vous rendra une liste vide) !
Reconstituer l’historique
Je dirais que contrairement aux problèmes de modélisation, c’est un petit « bobo », mais il arrive que parfois il soit impossible d’historiser au niveau de DWH car vous avez une multitude de sources qui sont déjà historisées (bonjour à nos amis les RH). Pour résoudre cette situation, il faut accomplir une reconstitution de l’historique des changements de données. Méfiez-vous, c’est une procédure tout sauf évidente (ex. SI1 a capturé un changement 1 semaine avant l’autre)…
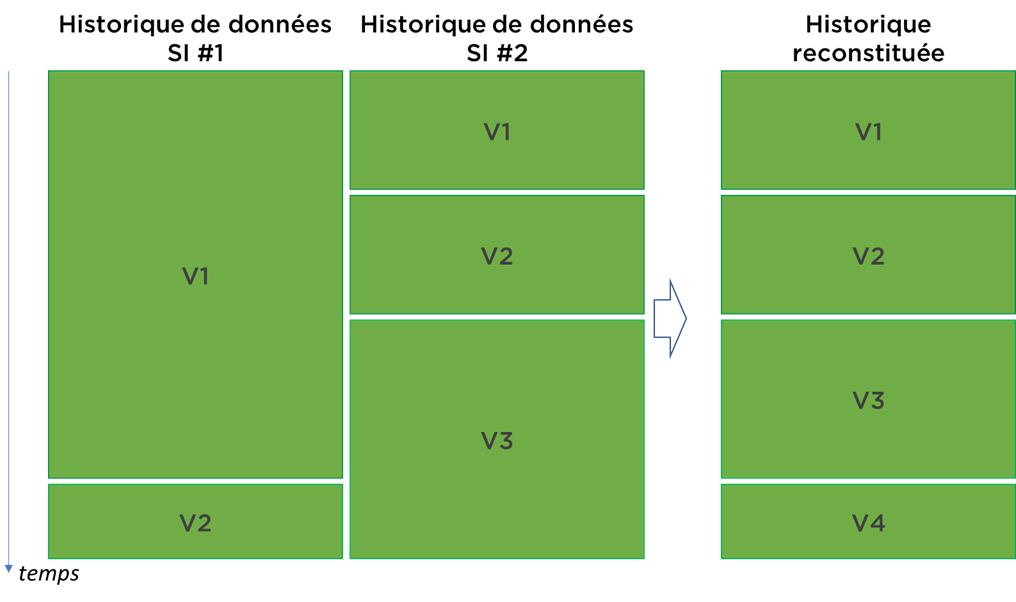
Des raisons d’être inquiet !
Si je montre cet article à n’importe quel professeur de BI, il me soulignera les faits suivants :
- il est improbable que je suis plus intelligent que M. Ralph Kimball ;
- un DWH, par définition, est historisé sinon ce n’est pas un DWH ;
- avoir plusieurs structures différentes dont une partie n’est pas en forme dimensionnelle veut dire que certains outils de reporting ne pourront pas les utiliser nativement ;
- il existe le Data Vault finalement (on en reparlera)…
En même temps, tous les problèmes listés m’inquiètent. Et vous, est-ce que vous avez des idées (sauf l’extension de standard SQL) pour gérer cette problématique ?
Commentez, likez, partagez.
Et, n’oubliez pas, bonne santé à vous et à vos systèmes.
Pingback: Data Vault – Ordre d'informaticiens