
All the other kids with the pumped up kicks
Foster The People
You better run, better run faster than my bullet
Aujourd’hui, je voudrais évoquer une méthode pour le moins intéressante pour modéliser un entrepôt de données : l’approche Data Vault. Attention – je n’ai pas dis que c’était une bonne technique, voyons cela de plus près.
Tout d’abord, pourquoi un article sur le sujet ? Je dois avouer avoir été motivé aussi bien par les experts qui m’entourent que par la fréquence des publications sur cette approche.
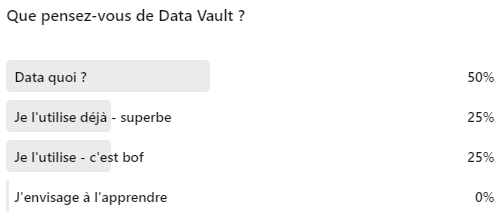
Avant de commencer, j’ai posé une question aux experts sur LinkedIn et même si 4 réponses ne permettent pas de tirer des conclusions, voici les résultats :
Introduction
Data Vault est une technique de modélisation de données développée durant les années 1990 par Dan Linstedt puis publiée en 2000 et enfin réajustée en 2013 (DV 2.0).

Cette nouvelle version de l’approche Data Vault est décrite dans le livre de Dan : « Building a Scalable Data Warehouse with Data Vault 2.0 ».
Il faut savoir que la méthodologie est pourtant longtemps restée au stade de simple « curiosité ». Aujourd’hui, sa popularité grimpe encore, il devient crucial de comprendre ses avantages et ses limites.
L’approche DV s’oppose aux méthodes classiques, basées sur la « single version of truth » (seule version de la vérité, à ne pas confondre avec la « single source of truth », seule source de vérité) :
- au lieu de garder seulement une version, nous pouvons garder toutes les versions existantes en compilant l’historique, ainsi, nous obtenons automatiquement la « traçabilité » ;
- contrairement à la modélisation dite dimensionnelle, DV est beaucoup plus normalisée ;
- contrairement à la modélisation d’ODS/CIF intégrée, cette structure est historisée (vérifiez si vous comprenez la définition de même manière que Kimball et Inmon : https://www.kimballgroup.com/2004/03/differences-of-opinion/) ;
- contrairement à la modélisation de « Data Lake » (https://ithealth.io/data-lake-retour-vers-la-definition/), elle s’appuie fortement sur la sémantique de données et sur 3NF.
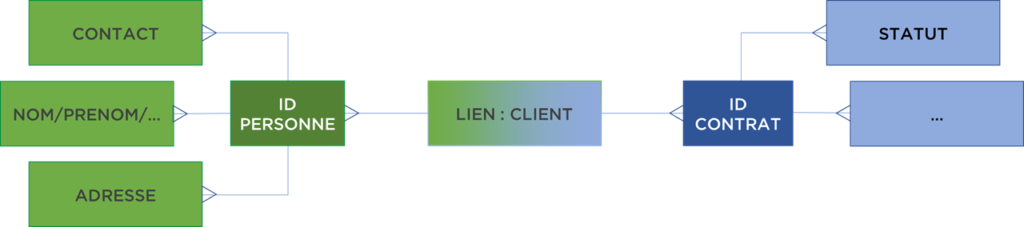
Magique, n’est ce pas ? Je vous propose de comprendre l’approche DV avec un exemple. Supposons que nous avons un modèle de données PERSONNE-CONTRAT (une personne peut avoir plusieurs contrats) :

Première chose que nous pouvons faire c’est d’éliminer la granularité du lien. Le lien entre les tables deviendra une table d’association. Qu’est-ce que cela nous donne ? Du point de vue du modèle : plus de flexibilité. Désormais, le contrat peut être relié à plusieurs personnes (si demain on imagine une telle possibilité, nous n’avons rien à modifier dans le modèle). De plus, ce lien peut techniquement contenir l’historique des liens (i.e. le contrat peut passer d’un client à l’autre).

Maintenant, nous pouvons nous occuper de nos objets « métier » : PERSONNE et CONTRAT. Chaque personne peut changer un certain nombre d’attributs (nom, téléphone, etc), mais elle reste toujours la même « personne ». Idem avec un contrat, il peut aussi être ajusté, changer de statut, mais dans un sens, reste le « même contrat ». Cette « mêmetude » ou « identité » doit être définie, mais si nous le faisons, nous pouvons ensuite diviser notre modèle avec pour chaque objet une structure « constante » et une structure « volatile » :
Il nous reste encore une étape supplémentaire – nous pouvons normaliser le modèle pour faire apparaître les tables de nomenclature :
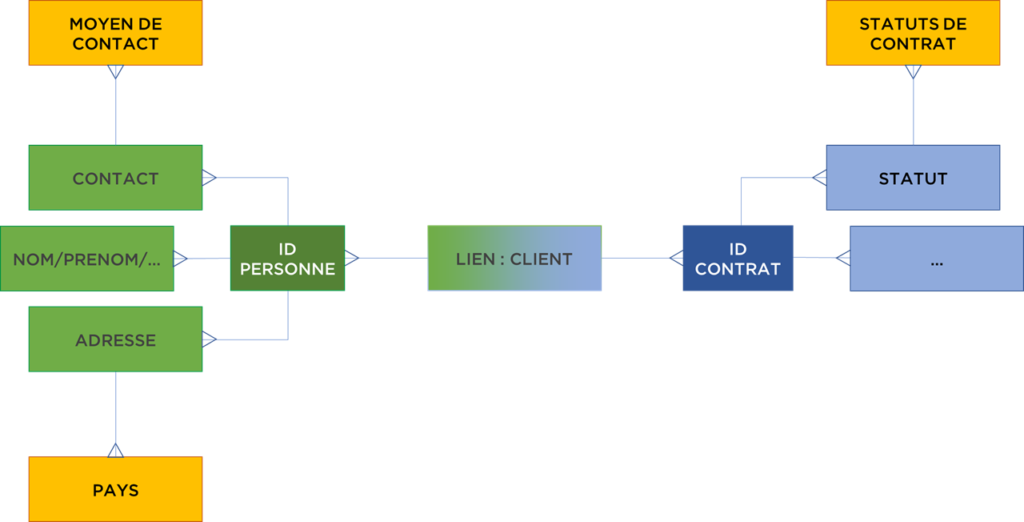
Vous remarquerez sur notre schéma, les tables « volatiles » appelées en DV satellites (CONTACT, NOM/PRENOM, etc) sont en N-à-1 avec les tables « constantes » appelées en DV hubs (ID PERSONNE, ID CONTRAT), elles peuvent être historisées et même peuvent contenir plusieurs versions de données (si les données sont stockées dans plusieurs systèmes), le lien – link peut aussi être historisé. La nomenclature appelée reference tables (tables de référence), en revanche, ne doit pas être historisée.
Techniquement, nous n’avons pas fait grande chose. Une simple découpe du modèle. Maintenant, néanmoins, nous évitons un nombre important de problèmes : pas besoin de choisir la golden record car nous pouvons garder l’ensemble des versions de données, nous disposons de l’historisation sans IDs historiques car cela peut devenir un cauchemar (voir l’article concernant l’historisation : https://ithealth.io/historiser-ses-donnees-vraiment-si-simple/), etc. C’est magique, n’est-ce pas ?
Pour conclure, voici le rôle de chaque table :
- hubs – contiennent l’identité de l’objet métier (via une clé fonctionnelle), i.e. une ligne correspondant à un objet métier ;
- satellites – contiennent l’historique des changements d’attributs des objets métier ;
- links – contiennent les liens entre les objets (toujours N-à-N) ;
- reference tables – le même rôle que hub, mais pour la nomenclature (en anglais – Reference Data, ne pas confondre avec Master Data).
Analyse
Première chose que nous devons remarquer – la technicité – le nombre d’objets est bien plus important que dans notre modèle initial. C’est le prix à payer pour tout modèle normalisé. À noter que les modèles analytiques essaient souvent de diminuer le nombre de jointures pour obtenir de meilleurs résultats de calcul (nous avons vu l’illustration de ce principe durant nos tests de Clickhouse : https://ithealth.io/homebrew-une-base-analytique-pour-tous/).
Deuxième problème – utilisation de la version récente de données est un paterne récurrent (https://ithealth.io/historiser-ses-donnees-vraiment-si-simple/), alors il faut imaginer que la plupart des analyses ne vont extraire que la version la plus récente depuis les satellites, alors que nous avons tout fait pour garder l’ensemble de l’historique.
Troisième problème – absence de golden record. À proprement dit, nous avons tout pour le calculer au moment souhaité, mais dans notre modèle nous devrons le faire car nous ne l’avons pas stocké (même si nous pouvons imaginer des solutions à ce problème).
Quatrième problème – utilisation d’une clé fonctionnelle dans le hubs pour rapprocher les données. Cela peut sembler pertinent, même si elle a beaucoup de points négatifs que vous devez prendre en compte (https://ithealth.io/dont-do-it-la-cle-fonctionnelle-business-key/)… Nous avons précisé que la clé fonctionnelle ne fonctionne pas toujours pour certains objets métier, c’est vrai, il n’est pas toujours possible d’identifier les objets (rapprocher les doublons) avec certitude. Nous devons permettre une modification manuelle des rapprochements (par un Data Steward), i.e. nous avons besoin d’un modèle encore plus flexible afin de ne pas se perdre dans les satellites (nous avons donné un exemple pour un modèle dénormalisé ici : https://ithealth.io/dimensions-master-data-problemes-et-solutions/).
Si nous voulons garder le modèle historisé, normalisé et permettre tout ajustement du rapprochement relativement facilement, il faut modifier l’approche Data Vault et y inclure les tables de rapprochement entre les objets de SI sources et les hubs, par exemple :
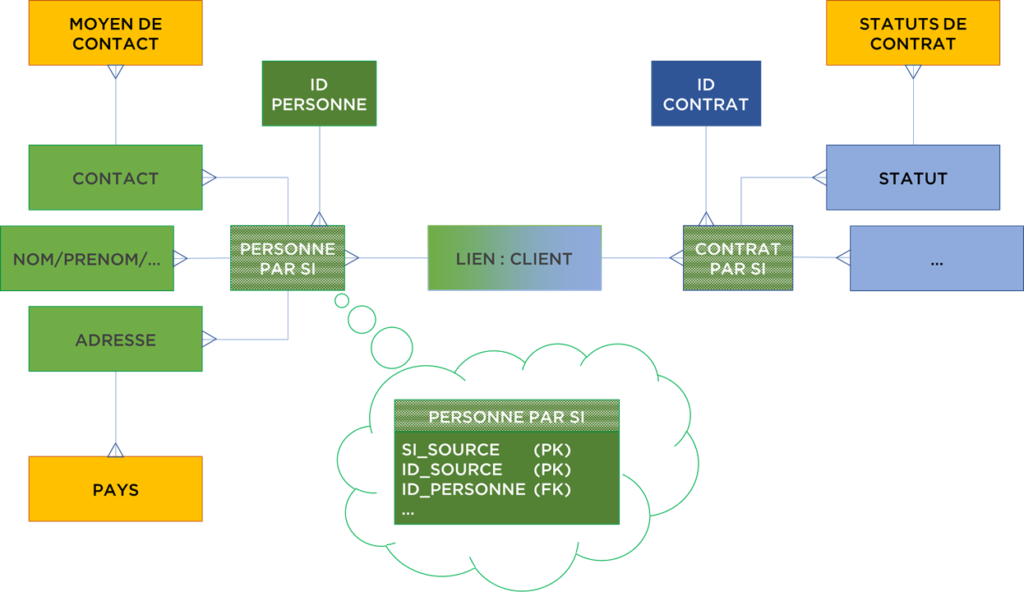
Par contre, c’est un modèle très flexible, mais ô combien complexe. De plus, nous sommes en réalité revenus au modèle normalisé de la Landing Area (aka Pivot) + tables de transcodification car la majorité du modèle va contenir les données quasiment « AsIs », mais historisées et les tables PERSONNE PAR SI et CONTRAT PAR SI sont des tables de rapprochement (transcodification) :
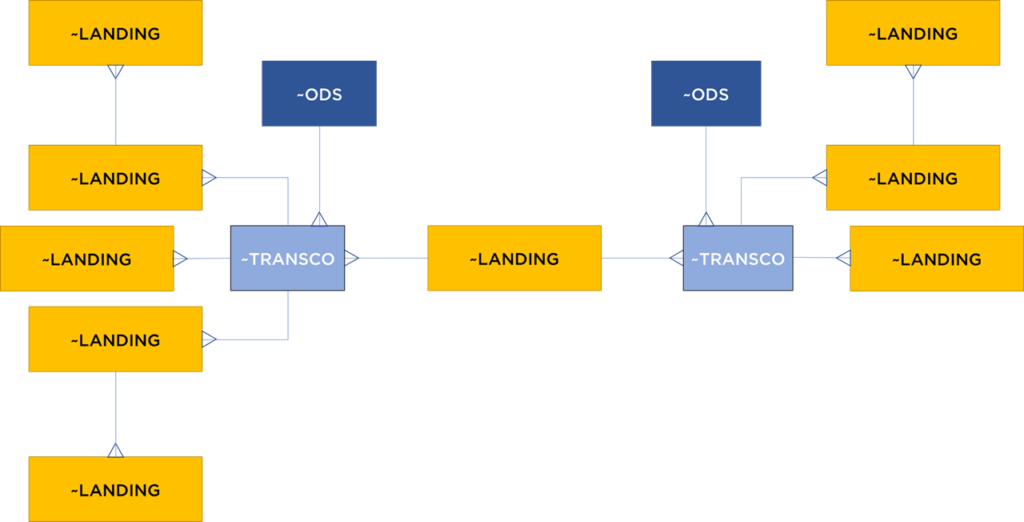
Si vous êtes encore en train de lire cet analyse, vous devez conclure avec nous que Data Vault est juste une combinaison complexe de la normalisation, de l’historisation et de mauvaises techniques de rapprochement de données. Toute tentative d’amélioration de l’approche complexifie le modèle encore plus, mais le résultat commence à ressembler de plus en plus une architecture classique…
Il est assez clair que l’utilisation de ce modèle demande une gestion des requêtes très complexes. Je ne vais pas détailler ce sujet, mais vous imaginez que Data Vault n’est pas supporté par les outils de reporting / data viz du marché.
L’ensemble de ces constats nous rappelle que l’approche Data Vault n’est généralement pas applicable aux entrepôts de données…
Conclusion
Faire bien en faisant moins c’est très rare. En général tout système bien conçu nécessite l’effort commun et continu de nombreux ingénieurs. Malheureusement, cet adage s’applique également à l’approche Data Vault. Cette tentative pour rendre le modèle plus flexible a juste déplacé les problèmes des flux au niveau de reporting…
Qu’en pensez-vous ?
Bonne santé à vous et à vos systèmes !