
Nous commençons notre article du jour par des faits qui, au premier abord, ne semblent pas être liés :
- Ralph Kimball disait que la staging area ne doit pas, en général, être stockée dans une base de donnée : c’est raisonnable, mais il se trompe lorsqu’on parle de données volumineuses.
- Pour améliorer la performance des flux, nous avons l’habitude de créer des flux « incrémentaux ». La majorité des consultants pense que c’est au chef de projet de spécifier ces flux – ils se trompent.
- James Dixon (à l’origine de la notion de Data Lake) disait que cette architecture permet d’alimenter les systèmes décisionnels – il se trompe.
À nous ? Quand on annonce que les flux de DWH sont prêts, mais que la nouvelle « brique » du projet prendra 2-3 heures minimum pour tourner chaque nuit, en général la question (raisonnable) du métier est « même si il y a du volume, la modification journalière de données est négligeable, pourquoi donc cela prend autant de temps ? » Le chef de projet (assez souvent) devient tout rouge et les développeurs répondent qu’ils traitent l’ensemble du volume. Pourquoi ?
Pour comprendre les raisons de cette approche et surtout pour trouver les solutions il faut comprendre ce que nous faisons avec les données quand on les charge dans le DWH. La liste de différentes opérations est vaste, mais les opérations les plus courantes sont les suivantes :
- accès aux données : lecture des bases de données, des fichiers, etc;
- filtrage de données (par condition);
- calcul des nouveaux champs (ligne par ligne, indépendamment l’une de l’autre);
- jointure de données (combinaison de plusieurs tables, transcodification, dénormalisation, etc);
- agrégation de données (pour diminuer le volume, pour avoir les chiffres de référence – comme par exemple dans la gestion de stock).
Avec ces 5 opérations, nous pouvons accomplir la majeure partie des chargements de données transactionnelles (pour le référentiel, il y en aura d’autres en plus).
Essayons d’estimer le temps nécessaire pour exécuter chaque opération (nous ne pourrons pas vous donner des valeurs – cela dépendra de votre environnement – mais on pourra donner une estimation d’ordre de complexité) :
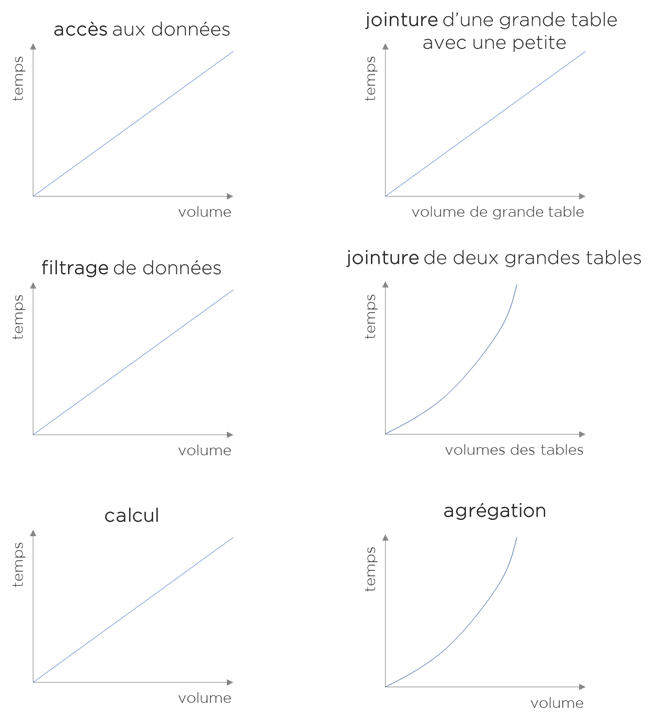
Nous pouvons voir que :
- L’accès aux données, le filtrage, le calcul et l’un des types de jointure montrent une corrélation entre volumétrie et le temps. Plus de données = plus du temps (linéairement plus du temps). Ainsi il est logique de traiter que les données modifiées.
- La jointure de deux grandes tables ou bien l’agrégation, c’est une autre histoire – en effet, si on augmente le volume – le facteur temps « s’explose ». Pourquoi? Avant la jointure/agrégation, il faut trier les données. Or plus nous trions de données, plus cela sera lent même si nous prenons le ratio à la ligne.
Pouvons-nous, en utilisant ces conclusions, remédier aux problèmes de performance ? C’est ce que nous allons faire.
Au début, il faut capturer les changements. Il existe (au moins) 3 types d’approche :
- Si dans le système source, nous avons un champ qui horodate les changements (et il est idéalement indexé), nous pouvons l’utiliser pour extraire les modifications (sauf pour les suppressions que nous ne verrons plus).
- Si le système n’a pas de ce genre de champ ou bien nous devons absolument capturer les suppressions – il y a des outils de « Change Data Capture » (CDC) qui savent se connecter à la base de données et en lisant les logs binaires (undo/redo logs), trouvent directement les lignes qui ont été modifiées, même en temps réel si nécessaire.
- Si vous ne pouvez pas utiliser un système CDC, vous pouvez créer votre propre « capteur des modifications », mais il va quand même relire l’ensemble de la table source, comparer les données à la version extraite précédemment et trouver/sauvegarder les différences – c’est lent (deux extractions + une jointure + calcul/comparaison + sauvegarde), mais cela offre un gain de temps sur les autres flux de DWH.
Si nous avons capturé les changements, il faut les sauvegarder, surtout si vous les capturez vous-mêmes. Notre Landing Area commence avoir du sens. Par contre, toute table dans LA qui est utilisée pour les flux incrémentaux doit avoir les champs : clé unique (primaire), la date de la dernière modification (indexée pour extraire rapidement les dernières modifications) et le statut de la ligne (active/supprimée). LA des flux incrémentaux n’est plus un stockage temporaire – nous allons la préserver et y garder toutes données sources.
Remarque technique : il y a des méthodes qui permettent d’éviter le stockage de toutes données, mais elles ont des limites. Par exemple, vous pouvez stocker uniquement les modifications de données depuis X temps, mais dans ce cas vous devez garantir une certaine performance de votre système source en lecture par clé, ce que n’est pas toujours possible.
Maintenant, si nous avons eu un flux basique suivant :
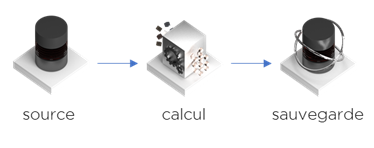
Nous pouvons le facilement convertir en flux incrémental :
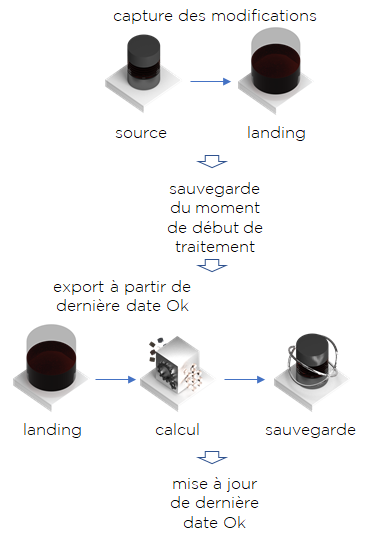
- Nous captons les modifications dans LA (3 façons de le faire, vous vous rappelez ?)
- Avant de lancer le traitement, on se rappelle quand on l’avait lancé.
- On exécute le même traitement qu’avant, mais nous ne prenons que celles qui ont été modifiées depuis le dernier traitement sans erreur.
- Si à la fin, le traitement est OK, nous mettons à jour la date de la dernière exécution correcte à celle que nous avons calculé avant de lancer le traitement.
Note importante : pour les lignes qui ont le statut « supprimée », nous ne ferons aucun calcul – on les supprimera à la fin de traitement – pour cela et pour pouvoir mettre à jour les données, il faut garder la notion de la clé unique (primaire). I.e. vous pouvez dire que le traitement a une forme suivante en SQL :
select clé, <votre calcul>, statut from landing.A where date_modif>%date_ok% and statut=’Active’ — pour update-insert
union all
select clé, null, …, statut from landing.A where date_modif>%date_ok% and statut=’Inactive’ — pour delete
Une autre remarque importante : ici la transformation de notre flux est purement « technique » – le métier n’a pas besoin d’organiser des réunions pour décider comment faire.
Pour le filtrage – c’est facile – le filtre à « false » doit convertir le statut en ‘Inactive’, donc essayer de supprimer la ligne :
select clé, …, case when filtre then statut else ‘Inactive’ end as statut from landing.A where date_modif>%date_ok%
Mais c’est trop facile ! Où sont mes jointures ?
Prenons un exemple le plus récurrent : jointure par une clé unique (ex. par une clé étrangère avec une table de nomenclature ou avec la table de la transcodification) :
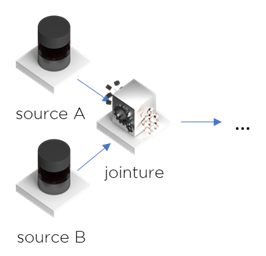
Le processus de jointure incrémentale nécessite 2 choses :
- Les données modifiées (depuis le dernier chargement « OK »)
- L’ensemble de toutes données (version actuelle)
Dans ce cas, la jointure incrémentale est :
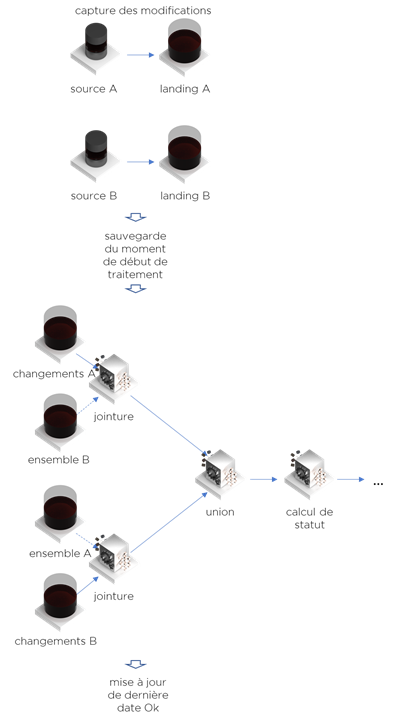
- Capture comme dans notre exemple précédent
- Sauvegarde de la date de début de flux
- Jointure … elle est décomposée en deux. Ces deux jointures n’exportent que les données modifiées puis, pour chaque ligne modifiée, vont chercher les données d’autres tables (lookup). À aucun moment, on va exporter l’ensemble de données. Il faut savoir que le lookup prendra beaucoup du temps en ratio par ligne traitée. En revanche, si le nombre de modifications est raisonnable, cela sera quand même plus rapide qu’extraire la totalité de données.
À la fin, nous avons une « union » de deux jeux de données et la suite du traitement … - Enfin, on sauvegarde la date si le traitement est OK.
Même calcul en SQL (ex. A left outer join B) :
select A.clé, autres champs A,
case when B.statut=’Active’ then champs de B else null end,
A.statut
from landing.A left outer join landing.B on A.refB=B.clé
where A.date_modif>%date_ok%
union
select A.clé, autres champs A,
case when B.statut=’Active’ then champs de B else null end,
A.statut
from landing.A left outer join landing.B on A.refB=B.clé
where A.statut=’Active’ and B.date_modif>%date_ok%
Note importante : Ici, il est vraiment logique d’utiliser le SQL car c’est le moment où l’ELT peut battre l’ETL.
J’espère que vous avez compris le principe de fonctionnement. Est-ce que vous allez pouvoir trouver l’algorithme pour l’agrégation ? Il peut y avoir des variations plus ou moins optimales et cela surtout dépend de la possibilité du changement des clés d’agrégation (à certain niveau vous allez avoir besoin d’historiser vos données).
Ce qui est intéressant est que visiblement il n’est pas possible de faire l’agrégation avec jointure sans sauvegarder les résultats intermédiaires. Dit autrement, vous allez devoir utiliser la Staging Area (en plus à Landing).
Heureusement pour nous, il n’est pas nécessaire de reprendre tous les flux de cette manière car la majorité des données se situe dans une minorité de tables.
Jusqu’à présent, nous avons essayé de prouver que :
- Il est possible de convertir les flux en incrémentaux.
- Vous obtenez une augmentation de la performance (assez certainement – voir les liens dessous – Behrend & Jörg obtiennent parfois un boost de 10x performance).
- Idéalement, il vous faut une Landing Area / une Staging Area bien indexées par les clés et par les dates de changement.
- Le processus de conversion en forme incrémentale est presque mécanique, pas besoin de métier ni de chef de projet.
- Nous n’avons pas besoin d’historiser la Landing /Staging (sauf pour les cas complexes d’agrégation).
Pour les tenants du data lake sous Hadoop, dites-nous comment vous indexez les données et comment vous ajustez les algos pour ne prendre que la dernière version de données ? Utilisez-vous les algorithmes incrémentaux ?
Bonne santé à vous et à vos systèmes.
Un peu de lecture :
- Andreas Behrend, Thomas Jörg,
Optimized Incremental ETL Jobs for Maintaining Data Warehouses
https://www.researchgate.net/publication/221524369_Optimized_Incremental_ETL_Jobs_for_Maintaining_Data_Warehouses - Igor Mekterović, Ljiljana Brkić,
Delta View Generation for Incremental Loading of Large Dimensions in a Data Warehouse https://bib.irb.hr/datoteka/765003.miproBIS_04_3490.pdf
Pingback: Outil ETL : comment faire son choix – Ordre d'informaticiens
Pingback: La consolidation de données : extraction – Ordre d'informaticiens