
Même si on vous a mangé, vous avez au moins deux chemins pour s’en sortir
La vaste majorité des outils de transformation de données propose deux types d’exécutables :
- les « flux » de données qui décrivent la transformation per se, présentés :
- en forme graphique (ETL classique) ;
- en forme d’opérateurs (Spark) ;
- en forme de mappings (certains ELTs) ;
- en forme d’options de la séquence de consolidation ;
- etc…
- les « séquenceurs » qui décrivent l’ordre (chaîne) et les conditions d’exécution des flux.
Nous avons beaucoup parlé de flux ce dernier temps. Je pense que nous devons consacrer quelques minutes au séquencement.
Séquenceur impératif
À quoi ressemble un séquenceur classique ? Voici les exemples d’IBM DataStage, Informatica PowerCenter et BMC Control-M :
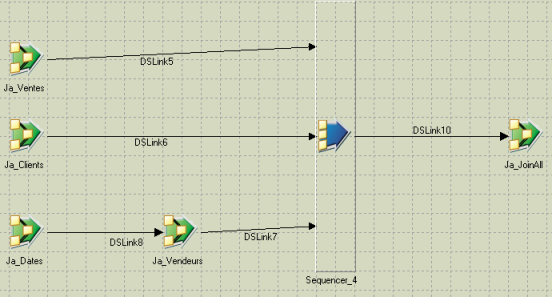
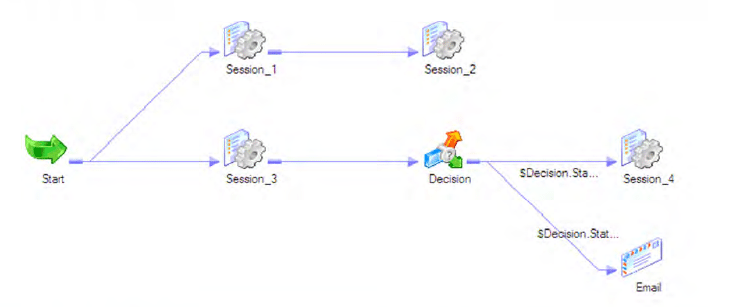
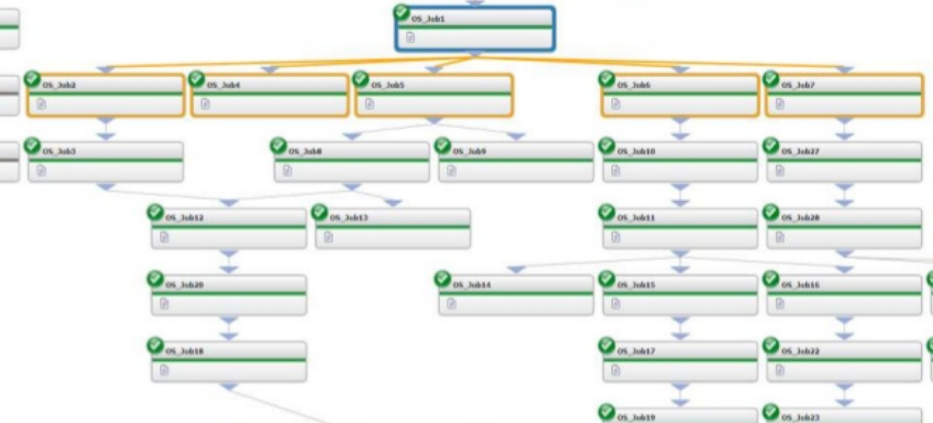
En général, le séquenceur est un programme qui exécute les flux suivant un ordre prédéfini (parfois parallèle). Certains séquenceurs peuvent organiser des boucles de différents types (for, for each, while), conditions, relancer des tâches, envoyer des mails… pour autant, même les meilleurs séquenceurs sont « impératifs ».
Que veut-il bien dire ?
Avec le séquenceur impératif, nous décrivons l’ensemble de la chaîne d’exécution à la main, en mettant les étapes les unes après les autres suivant la charge maximale du serveur, les dépendances entre les données, etc. Le problème est que nous avons toute cette information dans la tête au moment de la mise en place de la chaîne, mais elle ne se conserve pas dans notre code.
Prenons un exemple. Supposons que nous avons besoin d’importer un fichier XML complexe contenant des données des transactions, donc nous allons avoir besoin d’exécuter plusieurs tâches dans l’ordre :
- Vérifier que le fichier a été reçu :
- « non » : envoyer un message à l’exploitation ;
- « oui » : exécuter la chaîne :
- lire et parser le contenu en plusieurs objets temporaires (Landing Area) pour les différents niveaux du fichier ;
- exécuter l’import du niveau « client » dans la base de données ;
- exécuter l’import du niveau « produits » ;
- exécuter l’import du niveau « transactions ».
- en cas d’erreurs – envoyer un message ;
- à la fin – nettoyer les fichiers / tables temporaires.
Si nous avons besoin d’importer plusieurs fichiers, dans le cas le plus simple, nous allons organiser une boucle :
- Lire la liste des fichiers reçus.
- …si la liste est vide, envoyer un message,
- …sinon pour chaque fichier exécuter l’algorithme précédent, i.e. :
- lire et parser le contenu…
- exécuter l’import…
- etc.
Cette technique (la description de l’ordre d’exécution manuellement) fonctionne parfaitement bien pour la plupart des projets, mais a tout de même ses limites.
Séquenceur déclaratif
Supposons maintenant que vous arrivez sur un projet majeur de consolidation (DWH, Data Hub) avec un historique.

Quelque part, il existe une séquence de tous les flux du projet (ou plutôt une séquence de séquences). Il est peu probable qu’au niveau de cette séquence il y aura des boucles – elle sera assez linéaire, mais très complexe.
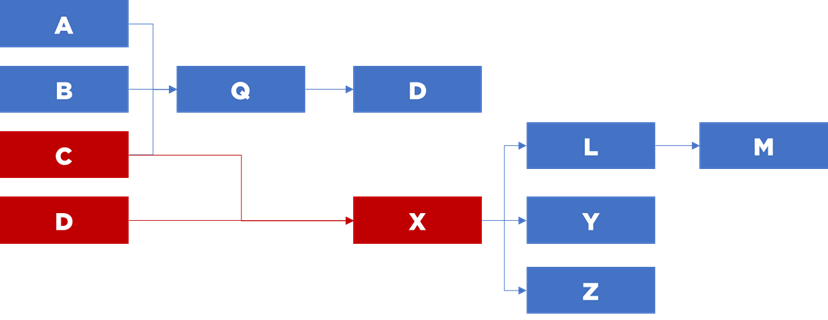
Imaginons que votre tâche c’est d’ajouter une nouvelle table qui dépend de tables A, B et C et qui sera référencée par une table D (déjà existante). Première chose à faire c’est de comprendre à quel moment vous allez exécuter vos flux. Dit plus simplement, est ce que vous pouvez vraiment les mettre entre les tables A, B, C et D ou vous devez imaginer une autre solution ?
Vous analysez les dépendances entre les flux… et voici le graph devant vous :
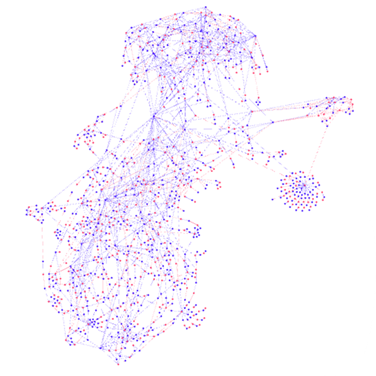
Ah le fameux effet spaghetti…

Attention : vous ne devez surtout pas vous tromper, sinon cela peut casser l’ensemble de la chaîne. Votre sentiment ? D’ailleurs, pouvez-vous prouver que vous avez mis votre flux dans un bon endroit ? Comment ?

Il existe un autre chemin – l’utilisation d’un séquenceur déclaratif.
Autrement dit, nous souhaitons pouvoir décrire le résultat avec toutes les conditions d’exécution – et obtenir automagiquement une séquence qui fonctionne.
À quoi ressemble un séquenceur déclaratif ?
Vous pouvez diviser votre projet d’intégration en modules et pour chaque module utiliser le séquenceur classique (impératif) si vous voulez, mais entre les modules, il suffit de décrire les dépendances, par exemple :
- module : A - module : B - module : C - module : Q depends-on-data : [A,B,C] - module : D depends-on-data : [Q] etc...
Dans ce cas, j’utilise YAML car les experts semblent être d’accord que c’est le format le plus adapté pour les configs, mais vous pouvez utiliser INI/XML/JSON/CSV/etc :
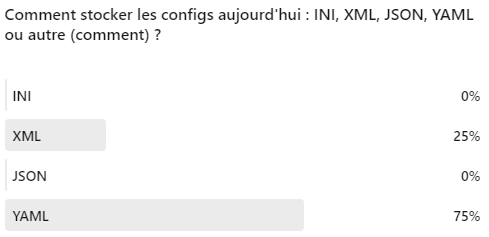
Vous pouvez voir que maintenant nous pouvons reconstituer la séquence d’exécution de toute la chaîne à partir de cette description :
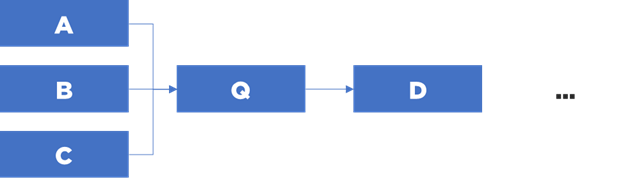
Nous n’avons pas besoin de nous poser la question concernant le moment d’exécution de chaque module – les modules seront exécutés au bon moment (si nous n’avons pas oublié une partie des dépendances).
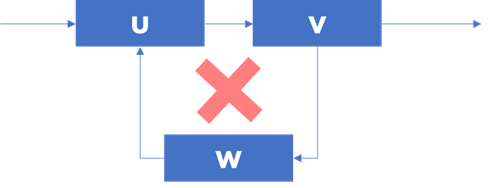
Nous pouvons faire une validation de la séquence – ce n’est qu’une vérification que notre graph n’a pas de boucles de dépendances :
Nous pouvons également constituer les séquences partielles pour une relance (ex. correction d’un bug), par exemple « relancer le flux X et tous les flux qui dépendent sur ce flux, donc en aval » :
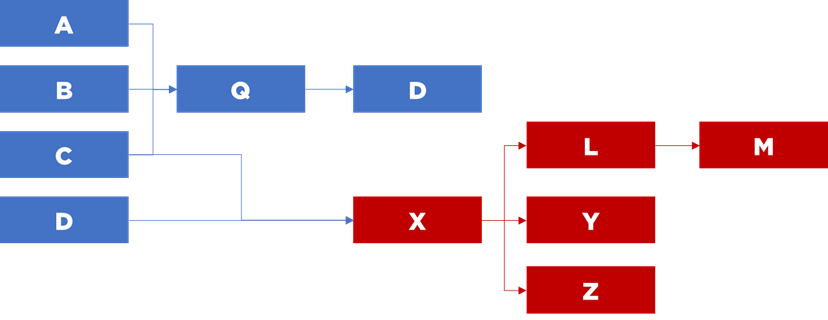
Nous pouvons faire les tests unitaires sans exécuter l’ensemble de la chaîne – « lancer le flux X et préparer les données dont il a besoin – i.e. lancer tous les flux dont il dépend (C et D), donc en amont » :
Naviguer dans un graph se scripte facilement en Java / Python / SQL récursif et donne une liberté que vous n’aurez jamais avec un séquenceur impératif.
Clairement, les modules doivent aussi respecter certaines normes :
- être suffisamment cloisonnés et assez indépendants (idéalement ils ne doivent pas dépendre des structures temporaires produites par les autres modules, mais c’est un point discutable) ;
- être relancables/idempotents (i.e. si nécessaire, on doit pouvoir réexécuter le même flux et obtenir le même résultat) ;
- remonter les erreurs de façon unifié ;
- etc.
Comment faire ?
La tâche peut vous paraître complexe, mais en réalité la seule chose dont vous avez vraiment besoin c’est de pouvoir lancer vos « modules » (flux, séquences élémentaires) par le nom, i.e. avoir une fonction run(name) :
- La majorité d’ETLs vous permet d’exécuter les flux via la ligne de commande (
dsjobpour DataStage,pmcmdpour Informatica, etc). - Si votre outil est assez avancé, vous pouvez créer un séquenceur déclaratif avec les moyens de bord (ex. DataStage Basic pour DataStage, Jython / JavaScript pour Stambia, etc) ou avec un script externe (ex. Java, Python, etc).
- Si vous utilisez Spark, vous êtes déjà dans un environnement de Scala / Python / Java, donc l’ajout de séquenceur ne doit pas poser de problèmes.
Voici à quoi peut ressembler la structure de votre séquenceur en Python (ici j’utilise deux structures – dependOnModules et dependentModules qui décrivent notre graph de deux manières différentes (transposées) et un pool de modules à exécuter ; schedule.yaml correspond à notre exemple de fichier de config) :
import yaml
#Liste de modules aka pool d'exécution
modules = set()
#...et dépendances
dependOnModules = {}
#...et les dépendances que le module peut résoudre (dictionnaire précèdent transposé)
dependentModules = {}
#Fonction à exécuter
def run(m):
#votre shell ici
print("Exécution de "+m)
#Lecture de données pour les indexer
with open("schedule.yaml", 'r') as stream:
schedule = yaml.safe_load(stream)
for m in schedule:
moduleName = m['module']
modules.add(moduleName)
if 'depends-on-data' in m.keys():
dependOnModules[moduleName] = set(m['depends-on-data'])
for dep in m['depends-on-data']:
if not dep in dependentModules.keys():
dependentModules[dep] = set(moduleName)
else:
dependentModules[dep].add(moduleName)
#boucle d'exécution
while len(modules) > 0 :
#trouver l'un de modules qui n'a pas de dépendances sur aucun autre
currentModule = None
for m in modules:
if m in dependOnModules:
if len(dependOnModules[m]) == 0:
currentModule = m
break
else:
currentModule = m
break
if currentModule is None:
raise Exception("Boucle dans votre graph - impossible à exécuter")
#exécuter
run(currentModule)
#si Ok, enlever ce module de notre pool
modules.remove(currentModule)
#...et supprimer depuis les dépendances d'autres modules
if currentModule in dependentModules:
for m in dependentModules[currentModule]:
dependOnModules[m].remove(currentModule)
Oui, ma solution est juste un « draft » qui n’est ni complet (gestion d’erreurs, restart, etc) ni parallélisé ni optimisé. Mais elle montre, j’espère, qu’il n’est finalement pas très compliqué de créer un séquenceur déclaratif.
Pour aller plus loin..
Vous pouvez aussi pousser l’idée plus loin :
- le séquenceur peut avoir des tags pour pouvoir distinguer les flux de Staging Area, ODS / Data Hub, DWH, dimensions, faits, etc ;
- les dépendances peuvent avoir différents types :
- au niveau des données (plus stricte) ;
- au niveau des clés étrangères (plus flexible) ;
- vous pouvez distinguer les flux et les ressources qu’ils produisent (tables, fichiers) – dans ce cas, même si vous décidez de changer vos modules, vous n’aurez pas besoin de réécrire les dépendances (par exemple, vous pouvez mettre dans votre fichier de configuration au lieu de « module Q dépend de module C », une information plus précise : « module C produit la table dbo.C, module Q utilise la table dbo.C » ;
- module : A produces : [dbo.A] - module : B produces : [dbo.B, B.txt] - module : C produces : [dbo.C] - module : Q depends-on-data : [dbo.A,dbo.B,dbo.C] produces : [dbo.Q] - module : D depends-on-data : [dbo.Q] etc...
Ainsi, vous pouvez garder l’information concernant l’état de la chaîne pour organiser une relance partielle en cas d’erreur ou bien réaliser un suivi d’exécution supplémentaire. Egalement, certains modules (flux) peuvent être « génériques » si certaines de vos tâches sont répétitives. Enfin, vous pouvez diviser votre configuration en plusieurs parties (fichiers), etc.
Avec ces modifications, vous allez être en mesure de « relancer tous les flux qui se sont plantés cette nuit et qui dépendent de système ERP et exécuter tout jusqu’à alimentation des dimensions ».
Conclusion
Même si on aime les pâtes, le séquencement dans les grands projets n’est pas obligé de ressembler à un plat de spaghetti. La mise en place d’un séquenceur déclaratif peut vous permettre de gérer la complexité et d’obtenir plus de flexibilité (au prix d’une interface graphique).
Bonne santé à vous et à vos projets !