
Aujourd’hui je voudrais revenir sur le sujet du governance catalog (catalogue des définitions métier). Nous l’avons déjà abordé précédemment du point de vue des difficultés de sa réalisation (https://ithealth.io/difficulte-de-definir-dictionnaire-data-governance-mythique/) et du modèle de données (https://ithealth.io/data-governance-dictionary-histoire-dune-definition/).
À ce titre, je voudrais vous proposer une autre approche qui vous permettra d’analyser l’utilité et la pertinence de cet effort (réaliser le catalogue) et surtout de la manière pour s’y prendre…
Pour commencer, regardons le processus qui est souvent utilisé pour la construction d’un governance catalog :
- récupérer l’information détaillée expliquant les processus fonctionnels,
- identifier les objets (sujets) importants et les liens fonctionnels,
- identifier les objets (sujets) communs entre les processus (et ce, malgré les différences de langage),
- consolider, i.e. documenter les objets (et parfois les processus) de façon unique et transverse, parfois avec le mapping aux objets techniques (dictionnaire technique de données).
Schématiquement :
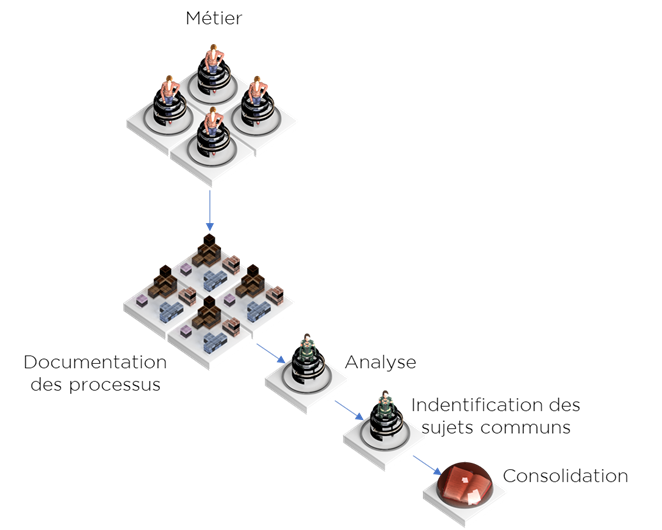
Est-ce une vision de l’esprit ou bien ce schéma ressemble en tout point au processus de consolidation de données (aka MDM de Consolidation) ? Mettons les deux côté à côté pour s’en rendre compte :
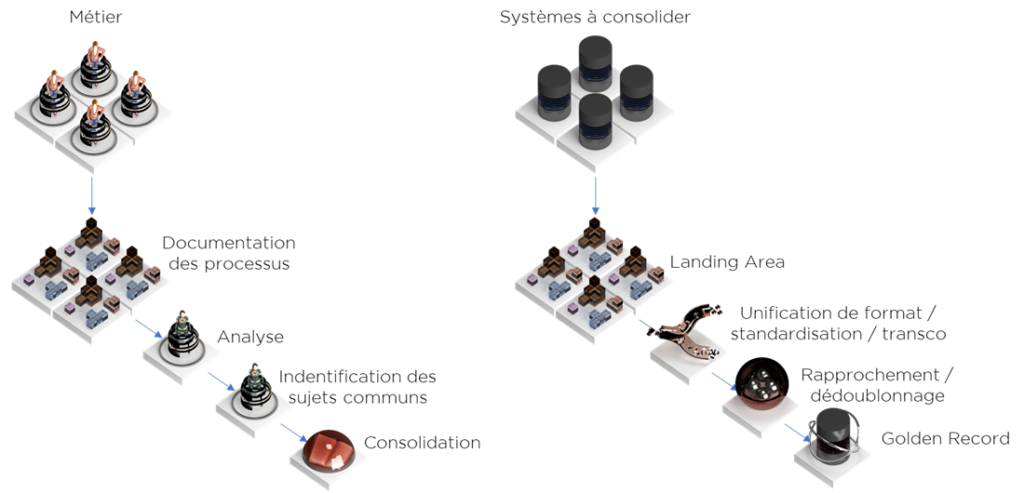
Il est fort probable, une fois vous voyez les deux schémas à côté, que vous vous dites : c’est évident. Néanmoins, je vais aller encore plus loin, ce n’est pas une simple analogie – c’est exactement la même chose. La différence est que dans un cas nous consolidons les descriptions des termes métier et dans un autre – les données d’objets.
Si vous êtes toujours avec moi, nous pouvons tirer des conclusions de cette « découverte » :
- les catalogues des définitions métier / des processus sont des meta-master-data,
- vous ne pouvez pas juste « verser » les définitions dans votre dictionnaire – ça sera équivalent de verser la Landing Area dans les Golden Records (quelle est donc la valeur ajoutée ?), ce que beaucoup de sociétés font par erreur c’est encore un « meta-data-lake », i.e. la liste des définitions qui n’est ni analysé ni rapproché ni consolidé,
- la construction de ces catalogues est a minima aussi complexe que la construction d’un MDM de Consolidation (en réalité, c’est encore plus complexe car les étapes d’analyse et d’identification-consolidation ne sont pas automatisables à notre niveau technologique),
- vous n’êtes pas probablement obligés de décrire l’ensemble des processus car…
- l’utilité via une analyse du ROI doit s’appliquer.
Ce que est étonnant pour moi c’est le fait que la grande majorité des outils de type « data governance catalog » ne sont pas du tout conçus pour aider à exécuter le processus de « consolidation » que nous avons vu sur le schéma ci-dessus. Ces outils sont juste des « réceptacles » des résultats (comme une base de données pour les golden records).
Encore pire c’est que certaines équipes utilisent des KPIs basés sur le volume de définitions… mais en fait c’est le contraire de ce que nous voulons ! En identifiant toute intersection des processus fonctionnels qui nomment le même objet différemment (« tiers », « adhérents », « clients », « customers », etc) nous allons réduire le volume de notre dictionnaire. N’est-ce pas ce que nous cherchons à accomplir ?
Bonne santé à vous et à votre data governance !