
The success of a production depends on the attention paid to detail.
David O. Selznick
Il était une fois, une grande organisation très connue en France qui a souhaité réaliser un audit de sa plateforme ETL.
Il y avait une liste importante de sujets, principalement techniques et plutôt pointus, mais il me semblait que quelqu’un a tenté de faire un « root cause analysis » sans grand succès. Heureusement pour nous, l’objet de l’intervention était clair et répondait à une question simple : « Est-ce que l’ETL existant correspond à nos besoins (et nous ne savons pas l’exploiter) ou doit-il être changé ? ».
Parmi les griefs listés, on trouvait : instabilité de la plateforme, difficultés d’exploitation, complexité de développement, etc. Le hic, c’est que des milliers de sociétés exploitent également cette plateforme sans rencontrer autant de soucis …
En échangeant avec le métier qui a la charge financière de la plateforme et du développement de nouveaux flux, il a été relevé que la plateforme dans son ensemble est grosso modo « inexploitable » car la mise à jour des flux prend entre 6 mois et 1 an. Dès lors, on comprend mieux ici la question centrale de cet audit, « encryptée » en quelque sorte au travers d’une formulation.

Auparavant, j’ai exploité une méthode simple pour accomplir jusqu’à 2 mises en production par semaine pour des projets DWH / MDM : (1) le chef de projet prend toute la responsabilité, (2) nous séparons les modifications irréversibles dans plusieurs versions (3) nous scriptons l’ensemble de mise en production et le roll-back (au cas où). Pour l’équipe de production (ou exploitation ou encore équipe de MeP) il ne reste que copier les ZIPs et les scripts et les exécuter : une fois en PreProd et une fois en Prod – parfois dans la même journée.
Renseigné auprès du métier, je rencontre les chefs de projets qui répondent que la raison pour laquelle un cycle de production dure 6 mois résulte du nombre très important de changements « packagés » par le métier dans une version. Visiblement, les chefs de projets n’arrivaient pas à diminuer la charge. Ce à quoi, le métier répondra qu’il doit mettre un maximum dans une version pour ne pas attendre encore 1 an avant la version suivante. Cercle vicieux.
Pour des raisons similaires, nous avons constaté que, en l’absence d’une seule équipe solide de développeurs, plusieurs équipes « co-existaient » ! En effet, chaque responsable métier voulait avoir son propre développeur afin de garder un certain contrôle.
Impossible de continuer, nous vérifions les charges (en 6 mois un expert peut produire massivement, en général un flux simple prend 0,5 à 2 jours de dev, un flux complexe – autour de 5 jours). Nous découvrons que sur les charges de projet, pour chaque version, il y avait 2 mois de mise en production. Bingo !

Un coût constant de 2 mois de test et de mise en production explique :
- délai total et les grosses versions,
- donc difficultés de développement et de test,
- donc insatisfaction des clients,
- donc accusations envers l’IT,
- donc la recherche des problèmes « techniques » pour expliquer pourquoi ils sont incapables de proposer le meilleur service (si quelqu’un doit être responsable, autant que ce soit le soft).
Je parle avec la Production et la Pré-production, puis avec les développeurs et je trouve que :
- Il existe une équipe de « DevOps » qui a réalisé des PoCs de CI (Continuous Delivery), mais ils n’ont pris que les attributs de la méthode agile sans en comprendre le sens, donc ils n’ont produit aucun résultat.
- Le timing réel de MeP ne doit pas dépasser 2 à 3 heures maximum (contre 2 mois consommés), le reste est attribué aux charges « supplémentaires » imposés par la production (sic!),
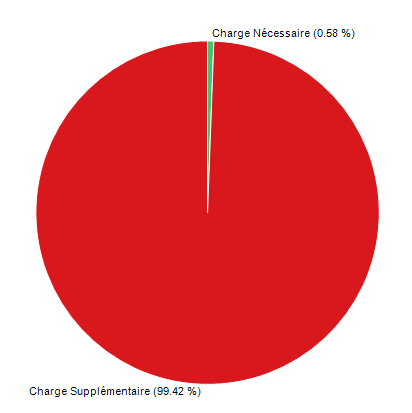
- la production a accumulé au fil du temps l’ensemble des droits sur la gestion et l’organisation des projets (sans aucune raison particulière ce sont les patricii de l’organisation),
- ils ont réussi à imposer ce fonctionnement aux chefs de projets (qui ne sont plus chefs, donc),
- en même temps, la production ne développe aucune compétence technique supplémentaire (pas de motivation particulière),
- …et empêche d’organiser le service de suivi au niveau des équipes de développement (même pas un classique « developer on duty » qui permet aux devs de suivre l’état de production et analyser les problèmes sans avoir besoin de repasser par la production),
- …pourtant « developer on duty » pouvait simplifier certaines procédures. Si développeur s’occupe de son produit, c’est à lui d’être responsable de la qualité, et surtout, il doit commencer à penser à la stabilité de son produit.
Malheureusement pour cette organisation, elle s’est tellement détériorée qu’il n’est plus possible pour les managers d’accepter les erreurs, encore moins commencer à appliquer les corrections. Même si nous n’avons pas trouvé de problèmes techniques majeurs avec la solution, il est bien évidemment plus simple de « tout recommencer » avec une méthode et organisation sur la nouvelle technologie.
Morale #1. L’agrégation du pouvoir entre les mains de personnes qui ne sont pas directement motivés par le résultat vous emmène droit dans le mur. La Production n’est presque jamais motivée.
Morale #2. Si la production ou un autre processus qui n’est pas lié au développement veut imposer les tests, ces tests doivent être automatisés pour ne pas prendre plus d’une journée (je parle du DWH et des tests techniques – les tests fonctionnels doivent prendre autant de temps que nécessaire, même s’ils peuvent aussi être scriptés).
Morale #3. La protection de la Production contre les développeurs n’aide pas.
Une solution est toujours possible. Si le DSI n’est pas « au courant » de la situation, il peut accomplir une réorganisation en mettant en place des responsabilités claires. Par contre, c’est un sujet « politique » donc très sensible. Attention au retour de flammes !
Un autre chemin. Cette situation me rappelle le concept de programmation « SoC » (Separation of Concerns) – ici deux sujets se mélangent – infrastructure et gestion des développements. Si la production accepte de proposer un service sur la plateforme (comme dans IaaS ou PaaS) tout en laissant le contrôle des applications aux équipes orientées « produit », cela peut fonctionner. J’ai des nombreux exemples en tête !
Morale #4. En plus à « The Phoenix Project », il existe « The Unicorn Project ».
En espérant que ce n’est pas votre cas, je souhaite une bonne santé à vous et à vos systèmes.