
…which leads to people trying to execute techniques without appreciating the reason for them… Which is bad and evil and Just Not Done…
Elizer Yudkowsky,
Rationality: from AI to zombies
Bonjour mes amis,
Après un petit break, on continue avec les articles autour d’IT… Aujourd’hui on va disséquer une notion que beaucoup d’informaticiens ignorent. Et pa-pa-pam…. on va parler de granularité. Attendez ne fermez pas l’onglet ! Donnez-moi 5 min et je vous montre à quel point ce sujet est passionnant.
Granularité (« grain » en anglais) est le niveau unitaire dans une table de la base de données (i.e. ce que représente une ligne dans une table). Fastoche ! Tout le monde connait la definition. Par contre, si vous tentez vraiment demander quelle est la granularité de telle ou telle table, vous serez souvent surpris.

#1
Commençons par un exemple basique : « une mutuelle envoie des factures… »
… le SI de compta a une table intitulée « facture ». Tentez de les poser la question sur la granularité de cette table – les comptables vont vous regarder comme si vous êtes tombé du ciel. Tout le monde sait ce qui est une facture. Donc, la granularité pour eux est une facture!
Par contre, dans chaque facture il y a deux granularités – l’entête (une par document, en bleu dans l’exemple ci-dessous) et les détails (lignes de facture en rouge dans notre exemple; on peut en avoir plusieurs lignes de détail par facture) :

Alors, laquelle des deux sera l’objet dans notre table? Après des allers-retours on découvre que la granularité de cette table correspond à… (vous avez deviné ?)… aucune de ces deux granularités, mais à « une version de l’entête de facture produite ».
Si la granularité correspondait aux détails de factures, on aurait du avoir 10’000 lignes dans notre table. Si la granularité correspondait aux en-têtes de chaque facture, on aurait du avoir 2’000 lignes. Enfin, la table que nous avons analysé avec compta a eu 8’000 lignes (4 versions en moyenne par facture). Autrement dit, il fallait filtrer cette table afin d’enlever les versions inutiles de chaque facture et puis chercher les détails ailleurs.
#2
Un exemple plus complexe.

Un autre client possède le système de gestion de coûts DSI. Dans ce système les consultants saisissent leur emploie du temps. Grand classique : chaque jour chaque consultant – interne ou externe – doit saisir le nombre d’heures travaillées sur un tel ou tel projet. Dans le référentiel des consultants on attend que la granularité corresponde a une personne physique.
Jusqu’à là tout est évident… tant que vous ne regardez pas les données – les consultants existent en double/triple/quadruple. Pourquoi ? Parce que la vraie granularité nécessaire pour faire fonctionner les processus n’a rien à voir avec chacun des consultants. La seule raison, pourquoi il y a le nom de consultant – nécessité de générer les CRAs (Compte Rendus d’Activité) pour des externes. Sinon, a la fin de mois tous les consultants sont « additionnés » pour avoir UNE ligne par service ou par prestataire. La vraie granularité est un service.
Après cet analyse on doit abandonner l’idée de gestion de doublons dans la liste de personnes (et tout ce qui est lié à RGPD, etc) – on doit se concentrer sur la gestion de qualité dans la liste de départements et des prestataires. Pas mal comme conclusion ?
#3
Un autre exemple (encore plus complexe), cette fois concernant une société logistique qui a décidé un jour de mettre en place un ERP central…

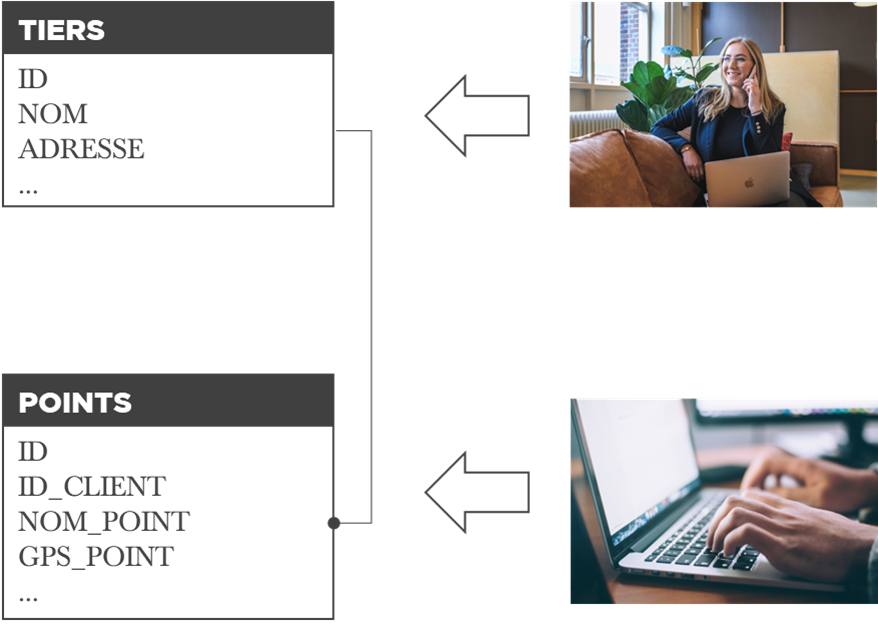
L’histoire se commence par des architectes de données (whatever it means). Tout le monde sait maintenant généraliser les modèles grâce à la notion de « TIERS ». Le résultat de cette généralisation est que tout et n’importe quoi se retrouve dans une table « TIERS ».
Maintenant si vous essayez donner la définition à ce que se retrouve dans la table « TIERS », vous êtes limités à la définition via énumération : on a ceci, on a cela, on a des clients, des points d’envoie, des points de réception, des ports, des noms des aéroports, etc.
Mais en réalité, quelle est l’information qu’on doit stocker dans notre ERP? Nous sommes d’accord que pour des lignes « client » nous devons avoir des informations suffisantes pour :
- lui envoyer une facture,
- l’identifier uniquement afin qu’il ne dépasse pas son limite de crédit.
Alors que pour des lignes « points d’envoie/réception » presque tout ce que nous voulons savoir ce sont les coordonnées GPS…
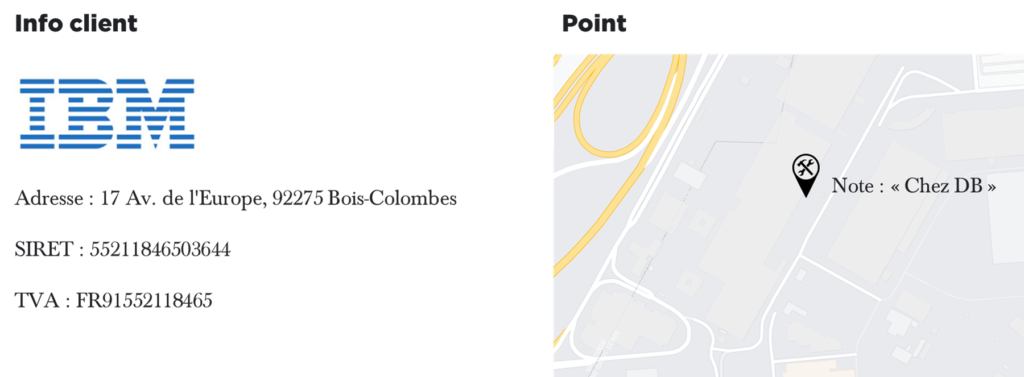
Fonctionnellement, il se trouve que dans les processus organisationnels à aucun moment ces tiers ne se mélangent, i.e. le point d’envoie/réception ne va jamais-jamais payer des factures. Et à l’inverse, le service de compta d’IBM ne sera jamais le point de livraison des conteneurs. Même si demain on doit livrer un conteneur sous les fenêtres du compta d’IBM, cette information aura peu d’utilité pour les processus d’envoie/réception.
Le vrai problème est donc, qu’il y a peu de tiers qui nécessitent une gestion profonde de qualité de données. Ce sont essentiellement des « service providers » (truckers, compagnies aériennes, etc), des centres de facturation des clients et des « hubs » importants de transport. Les 80-90% restants des « TIERS » sont juste des points géographiques avec une certaine description qui peuvent ou peuvent ne pas correspondre à une adresse d’une société (ex. un chantier au bout du monde).
C’était évident à seulement une personne de cette société logistique, mais cette personne est partie… le reste d’équipe galère toujours pour comprendre comment trouver des doublons parmi les plusieurs millions de « TIERS » (ce qui n’a pas de sens comme vous l’avez pu comprendre).
Dans un monde idéal où cette différence est claire aux architectes du ERP, la société aurait pu classifier les « tiers » en :
- référentiel central – géré en interne (back office),
- référentiel des points d’envoie/réception (par compte client) – géré librement par des responsables de logistique de chaque « client » via un outil de self-service (front office).
Dans ce monde parfait, des clients de cette société logistique pouvaient préparer/valider/suivre ses commandes eux-mêmes sans avoir besoin d’appeler quiconque et sans avoir besoin de transférer les détails de leurs commandes par e-mail.
Avec la gestion centralisée de tous les « tiers » (toutes granularités confondues), une société logistique ne peut que rêver d’un tel ERP :,(
On en reparlera un jour si le sujet vous intéresse.
Bonne santé à vous et à vos SI.
Why did the DBA go to work on a farm?
To learn more about grain management.
Pingback: Défi « Cendrillon » ou granularité facile – Tech Talks
Pingback: Data governance catalog – trinité de définitions : tables, attributs et associations – Ordre d'informaticiens