
Aujourd’hui je voudrais parler avec vous concernant un sujet aussi banal que le choix d’un ETL et les questions impératives à vous poser.
Pourquoi je pense que c’est toujours d’actualité ?
Le boom des nouveaux outils produit une « hype ». De ce fait, beaucoup de sociétés voir des consultants se comparent et finissent par penser qu’ils sont « en retard ». D’où cette question, lancinante, quel outil est le meilleur pour l’intégration de données ?
Petite précision : je vais utiliser le mot ETL dans un sens large : en effet, le besoin métier c’est d’avoir un outil d’intégration qui fonctionne et pas forcément un outil qui respecte à la lettre la définition du concept ETL. Par conséquent, les outils ELT, Spark, Hadoop et tous les autres seront considérés comme de potentiels candidats.
Aujourd’hui, quelles sont les fonctionnalités proposées par les outils d’intégration ?
ETL ou ELT
Pour rappel, l’ETL est un class d’outils d’intégration de données « en batch » qui dispose de son propre moteur embarqué, alors que l’ELT utilise les capacités de la base de données pour réaliser la transformation (code ELT « se compile » en SQL).
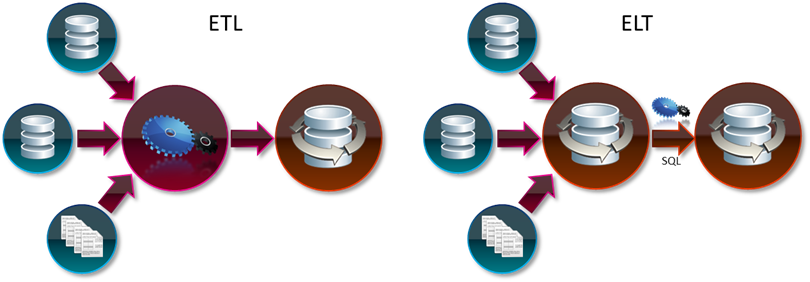
Deux choses qui peuvent être non-évidentes :
- L’outil ETL garantit la performance, il est prédictible – si vous exécutez un traitement et qu’entre aujourd’hui et demain, vos données vont connaître une augmentation de la volumétrie de l’ordre de 10%, vous pouvez prédire que le temps de traitement augmentera presque proportionnellement (pas de question d’indexe oublié ou statistique pas à jour). L’ELT est moins prédictible – c’est la nature des bases de données qu’il utilise pour son moteur, en revanche, il a une puissance incroyable – il peut utiliser les statistiques que la base de données génère, il peut limiter la quantité de données extraites, etc – situation idéale pour les flux incrémentaux (https://ithealth.io/boostez-la-performance-de-vos-flux-10x/);
- L’outil ETL est un free-ride de fonctionnalités : de transformations basiques, puis algorithmes intelligents de data quality jusqu’à vos propres étapes de traitement, l’ELT est limité par les capacités de votre base de données et par les capacités de votre outil.
Interface graphique
Beaucoup d’équipes qui mettent en place l’ETL (même en 2020) ont leurs propres habitudes :
- soit ce sont des développeurs ETL : que la bataille pour la meilleure interface commence,
- soit ce sont des développeurs Java/Python/SAS/Scala/etc et ils ne comprennent pas pourquoi maintenant ils n’écrivent plus aucun code,
- soit ce sont des analystes/DBA et ils ont toujours fait des extractions avec des requêtes SQL de plusieurs dizaines de lignes …
Voici les raisons pour lesquels vous devez prendre un outil avec un interface graphique :
- les flux ont une tendance de devenir complexes – dans les outils graphiques il est plus simple à comprendre et donc à maintenir le processus,
- si vous êtes tellement avancés que vos utilisateurs d’ETL ne sont pas spécialistes en ETL (self service/data prep/etc), il est important d’aplatir la courbe d’apprentissage…
…et les « contres » :
- si vos développeurs viennent du monde SQL, ils vont continuer à écrire le gros SQL et le copier-coller dans l’outil graphique (si-si, croyez-moi),
- si vos traitements sont ultra-spécifiques, aucun outil graphique ne pourra couvrir vos besoins (je ne parle pas de DWH ou d’II),
- la gestion des versions dans CVS/SVN/Git a peu de sens pour les outils graphiques – c’est difficile à comprendre, parfois.
Attention : les outils le plus simples à prendre en main peuvent manquer d’autres fonctionnalités. Pondérez votre choix !
L’intégration avec de nombreuses sources de données
Si vos flux n’utilisent que des bases de données de type Oracle, DB2, MS SQL et des fichiers plats, vous pouvez sauter cette partie.
Si vous devez proposer tous les connecteurs possibles et imaginables – il y a un risque que rien ne convienne sauf Java/Scala et JDBC.
Souvent, les vendeurs proposent des moyens d’extension des connecteurs standards (via ODBC ou via Java, C++ ou autres langages) et cela peut être une solution. Attention toutefois, les connecteurs sont parfois vendus un-par-un et votre facture peut vite devenir salée.
Conseil : anticipez la question en réalisant la liste des sources de données.
Exécution parallèle
Qu’est ce qui rend Hadoop si performant pour qu’eBay l’utilise en tant qu’outil ETL ? Et Spark, est-il encore meilleur pour que beaucoup de sociétés abandonnent « pure Hadoop » et réécrivent tous leurs flux en Spark ? Spoiler : le parallélisme de traitement.
En réalité, le parallélisme n’est pas arrivé avec Hadoop – dans les centres de recherche, les développeurs utilisent MPI (Message Passing Interface) pour paralléliser les traitements depuis des années 90.
Mais, dans le monde ETL, tout est encore plus simple car la majorité des traitements sont (presque) indépendants (chaque ligne peut être traitée indépendamment d’autres). Il est beaucoup plus facile d’implémenter le parallélisme (d’ailleurs, Map-Reduce n’a pas été inventé par Google et Hadoop & Spark sont loin d’être les seuls produits qui utilisent cette approche).
Si vous avez besoin de traiter des centaines de millions de lignes, vous avez 3 solutions :
- utiliser une base performante avec un ELT au dessus de cette base (c’est la base qui s’occupera du parallélisme),
- utiliser un ETL parallèle (et il ne sera pas gratuit!),
- utiliser les outils Spark/Hadoop/etc.
Point d’attention : il existe au moins deux types de parallélisme dans un(e) usine ETL :
- l’exécution de chaque étape en parallèle (i.e. chaque transformation ne se lance pas sur un seul thread, elle se lance en plusieurs threads ou même sur plusieurs serveurs et traite plusieurs records en même temps),
- l’exécution de plusieurs étapes en parallèle (i.e. une partie de données qui a été traitée par l’étape 1 passe à l’étape 2 sans attendre la fin de traitement de l’ensemble de données).

C’est la manque de possibilité d’exécuter le deuxième type de parallélisme (pipeline) qui a fait mal à Hadoop v1. Il n’était pas possible d’enchaîner plusieurs étapes sans sauvegarder les résultats intermédiaires sur HDD. Vous pensez que maintenant tout est OK ? Non, par exemple, Spark est OK sur les deux types de parallélisme jusqu’au moment du branchement de données – et soit vous allez exécuter la chaîne avec un branchement deux fois, soit vous devez sauvegarder les données sur HDD.
Note technique : un grand nombre de transformations a besoin de trier les données (certains types de jointure, d’agrégation, etc). Chaque trie « casse » le pipeline car il n’est pas possible de sortir la première ligne de résultats de trie avant de recevoir l’ensemble de données. C’est aussi valable pour ETL, ELT, Hadoop, Spark, etc. Par conséquent, la performance d’algorithme de trie peut fortement impacter le temps d’exécution de vos flux.
Conseil : faites vos PoCs sur les flux techniquement complexes.
Transformations complexes
Posez-vous la question si les sujets de rapprochement de données/dédoublonnage/standardisation sont dans le scope de vos projets d’intégration. Si vous répondez « oui », vous pouvez assez certainement écarter un nombre d’outils (tout ELT, certains outils vendus sous la sauce de « data quality »…).
Nous avons déjà vu ensemble (https://ithealth.io/rapprochement-de-donnees/) que l’identification de doublons est un sujet assez dense en termes de mathématique et il peut se passer que :
- soit vous devez prendre un outil « plus complexe », mais « plus avancé »,
- soit décider que c’est un sujet per se et vous ne voulez pas le mélanger avec ETL (donc, vous allez choisir deux outils : ETL et un outil de rapprochement de données spécialisé).
Une autre transformation complexe récurrente c’est le parsing/composition des formats hiérarchiques XML/JSON qui peuvent venir depuis les fichiers, bases de données ou appels aux services web. Faites attention à la complétude et à la complexité de ses processus. Certains outils « plus complexes » supportent l’ensemble de sources, alors que les autres ont réussi à simplifier l’interface grâce à la réduction de la fonctionnalité.
Développement rapide et réuse
Un grand nombre d’outils ETL permet le réuse des flux ou des transformations spécifiques. Dans ce cas, il y a plusieurs sujets importants :
- la granularité de réuse (i.e. la taille des morceaux de flux que vous pouvez réutiliser et modifier de façon centralisé),
- la capacité à imbriquer un élément dans un autre (certains systèmes parmi les meilleurs dans les analyses de Gartner ont une limitation de réuse d’un seul niveau – et cela peut poser des problèmes),
- la capacité à utiliser les mêmes transformations sur les différentes structures de données – c’est une fonctionnalité rare car en général dans les ETLs graphiques nous avons l’obligation de préciser le format de données traitées (noms et types des champs), alors que certains outils (j’en connais 2) donnent cette flexibilité extrême pour adapter le même flux aux différents formats.
Conseil : parlez avec un expert ETL.
Lineage et intégration avec les outils de Data Governance
Vos besoins au niveau du data lineage peuvent être plus ou moins couverts par les différents outils. Il faut prendre en compte qu’en général plus l’outil ETL est flexible et permissif, moins il est capable de garantir le lineage (i.e. traçabilité des flux). La raison est que nous ne savons pas encore tracer les transformations quelconques de données .
Certains outils permettent d’intégrer les dictionnaires de données (governance catalogs) avec les métadonnées utilisées dans les flux. C’est souvent une fonctionnalité supplémentaire. Posez-vous la question si vous en avez besoin – probablement vous serez forcés d’acheter une suite d’outils chez le même vendeur.
Conseil : si vous avez besoin de la traçabilité, demandez au commercial, dans quelle situation elle n’est plus garantie. Comparez ses réponses avec vos besoins. S’il dit qu’elle est toujours garantie – il est en train de vous mentir, soit son outil manque de fonctionnalités.
Intégration avec Hadoop, Spark ou d’autres technologies
Si vous êtes parmi ceux et celles qui utilisent une infrastructure de type Hadoop/Spark, il peut être intéressent de se poser la question si vous pouvez traiter les données sans les faire sortir du cluster.
Il existe donc deux possibilités :
- soit votre outil ETL s’installe sur les mêmes machines qu’Hadoop et coexiste sur la même infrastructure,
- soit votre outil ETL (je dirais ELT dans ce cas) exploite Hadoop/Spark pour exécuter ses flux.
Ne soyez pas pressé pour tirer des conclusions concernant la vitesse de l’une ou de l’autre approche – nous avons fait des tests et parfois un outil ETL co-existant sur Hadoop sans intégration complète a été beaucoup plus rapide que Hadoop ou même Spark (dans nos tests, jusqu’à 2x).
Conseil : si vous avez 150 To dans votre Hadoop, il est étrange que le traitement des données est fait en mono-tread sur un petit serveur… (oui, j’ai des exemples !) sachez qu’il existe toujours une solution graphique qui peut accomplir le traitement sur Hadoop sans que vous codez Map-Reduce/DAG en Java, Scala ou Python.
Autres sujets importants
À mon avis, il est important de ne pas oublier d’autres sujets :
- stabilité de l’outil (oui, tout outil ETL a des bugs, mais vous ne saurez pas si vous pouvez tolérer ces bugs avant que vous essayez de l’utiliser – prenez le temps de jouer avec les outils lors des PoCs),
- facilité de mise en production de projets (il y a des outils qui ne permettent pas la mise en production d’un ensemble de projet),
- facilité de debug des flux,
- capacité à stoker les données intermédiaires hors de la base de données (c’est important pour un ETL car tout I/O avec une base de données est plus chère qu’un dump de données dans un fichier temporaire binaire, mais certains ETLs manquent toujours de cette fonctionnalité),
- gestion de métadonnées (plus ou moins avancée, puis obligatoire/non-obligatoire).
Comme vous pouvez le voir, le sujet de « cloud » n’est pas dans cette liste et pour cela il y a des raisons. Concrètement, tout ETL peut être déployé en mode IaaS, sinon d’un point de vu du prix les offres pure-cloud ETL sont difficiles à argumenter actuellement (corrigez-moi si je me trompe).
Récapitulatif
Si vous choisissez un ETL/ELT, les questions qu’il faut se poser :
- volumétrie de données et donc la capacité de l’outil au parallélisme,
- nombre de cibles de données (pour ELT),
- complexité des traitements et les besoins de vos projets (traitements complexes, Data Quality),
- environnement technique (systèmes sources/cibles/Hadoop/Spark/etc),
- comment garantir que votre équipe accepte l’outil et l’utilise correctement,
- votre maturité en termes d’industrialisation des flux,
- vos besoins en termes de lineage/intégration avec governance catalog,
- maturité technologique de l’outil de votre choix (attention : ni la notoriété de l’éditeur ni le rapport de Gartner ne vous aideront, les deux sont simplement des indicateurs de l’avis de la majorité).
Bonne santé à vous et à votre ETL.