
…for every complex human problem, there is a solution that is neat, simple and wrong.
H. L. Mencken
– Notre entrepôt de données est lent… pourtant, il est sur Hadoop !
– Que voulez-vous, il est sur Hadoop.
Nous avons du mal à imaginer des applications complexes qui n’utilisent pas de base de données.
Par exemple, un outil pour écrire des notes sur mon téléphone utilise également une base de données embarquée. L’arrivée du théorème de CAP ainsi que le mouvement NoSQL/NewSQL ont ouvert l’esprit de beaucoup d’informaticiens. Cependant, si vous souhaitez quelque chose de standard, vous allez utiliser une base avec support du SQL.
Si nous nous intéressons aux bases qui supportent le SQL, nous pouvons constater que le marché est dominé par quelques marques : Oracle, Microsoft SQL, MySQL, PostgreSQL, IBM DB2, Sybase IQ, SAP HANA, Hive, SQLite, les autres sont secondaires (voici un classement : https://db-engines.com/en/ranking).
Question pertinente : quelle base choisir pour notre entrepôt de données ? Il existe au moins deux solutions :
- prendre celle déjà utilisée dans votre société (pour un ERP ou un site web)
- réaliser un benchmark des performances ou utiliser un benchmark existant, par exemple TPC-H.
OK pour le benchmark, mais finalement, pourrait-on utiliser le même type de base de données que pour l’ERP puisque nous avons potentiellement déjà un DBA spécialisé ? Pouvons-nous mettre l’entrepôt dans Hadoop ?
Premièrement, nous pouvons considérer le type de la charge de la base de données. Par exemple, l’ERP fait approximativement autant de « selects » que de « updates » de données. Inversement, le DWH durant son usage exécute quasiment que des « selects » (les « updates » passent pendant le chargement et nous pouvons tolérer un certain « trade-off »). Ajoutons dans notre comparaison une charge pour les « données froides » que nous appellerons « Archive » (pour les Data Lakes, archives, Landing Areas), bien plus tolérante à la question de la performance que l’ERP et le DWH.
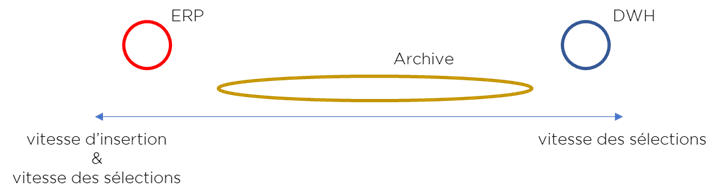
On peut noter qu’il existe un point important sur la complexité des requêtes. Si vous analysez les requêtes de l’ERP, elles passent toujours par les indexes (j’espère !). Elles ne sont pas aussi complexes que les dizaines (ou centaines) de lignes de SQL générées pour le DWH par les outils BI. De plus, les requêtes du DWH concernent souvent une partie importante de la base de données. Les requêtes exécutées par l’Archive peuvent avoir différents niveaux de complexité mais elles vont souvent chercher « tout et partout ».

La volumétrie de données ? Vos systèmes transactionnels (surtout si vous en avez plusieurs) peuvent maintenir une volumétrie raisonnable grâce aux différents mécanismes : purge, clôture d’année fiscale, etc. Ce n’est pas le cas (par définition) pour l’Archive. Pour le DWH, la situation est plus complexe – tout dépend de votre architecture et de vos besoins. Si vous êtes un Kimballien-puriste, la volumétrie sera plus importante. Si vous êtes plutôt Inmonien – vous pouvez faire de l’agrégation de données. On notera que si la technologie vous le permet – vous pouvez déplacer les données moins utilisées dans un stockage « froid » et ainsi maintenir une volumétrie de données raisonnable (mais certainement plus importante que celle de l’ERP).
Note. La gestion (minimisation) de la volumétrie via l’archivage (stockage froid) est initialement l’une des méthodes fondamentale de l’approche Big Data. C’est juste le contraire de la notion « garder tout dans un seul endroit », autrement dit : le Data Lake.
En utilisant une visualisation, nous allons mieux distinguer les différences :
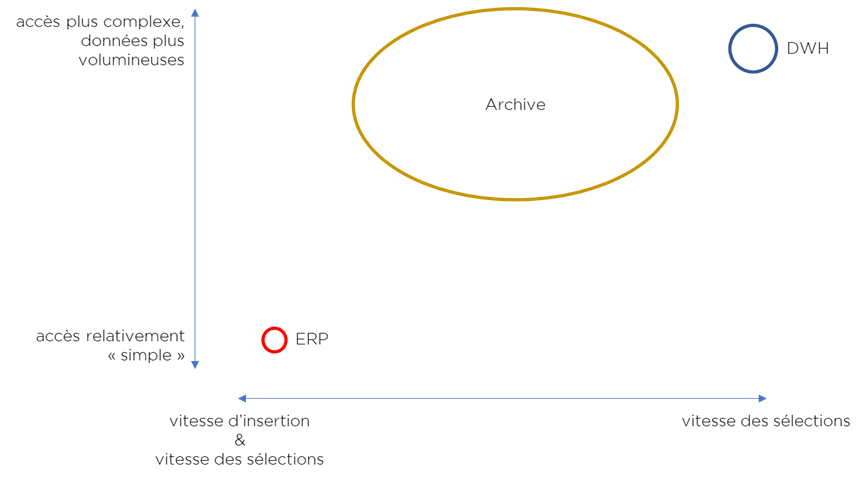
Nous pouvons clairement constater deux spécialisations opposées : transactionnelle (ERP) et analytique (DWH). De plus on a un « problème » (pour l’archive) : comment stocker et traiter une grande volumétrie de données pour qu’elle ne soit pas trop chère ? Finalement, on risque d’avoir besoin de 3 solutions différentes … Il peut se passer qu’une base de données qui accomplit parfaitement l’une des tâches sera insuffisante pour une autre.
Est-il possible d’expliquer ce comportement techniquement sans « philosophie » ? Oui.
- La partie la plus lente d’ordinateur se trouve être le disque dur (ou autre stockage permanent : SSD, etc). Elle est 6 à 100 000 fois plus lente que la RAM.
- Un système optimisé pour la lecture peut stocker des données en format compressé optimisé pour diminuer l’IO avec le stockage lent (exemple : le stockage orienté colonne permet de mieux compresser les données au prix d’une régression de la performance de la mise à jour, alors que les bases transactionnelles utilisent une compression « plus soft » qui ne nécessite pas d’opérations lourdes en cas de mise à jour des données).
- Contrairement à la charge transactionnelle, la charge analytique utilise peu de champs de chaque table, il est donc important de pouvoir filtrer les données au moment de la lecture (possible avec le stockage orienté colonne).
- Une base de données où chaque requête utilise la majorité des lignes de données peut ne pas utiliser les indexes et s’en sortir avec le data skipping. Inimaginable dans le monde transactionnel.
- Pour un système spécialisé sur la lecture, il est logique de diminuer le nombre de requêtes exécutées en parallèle (se concentrer sur moins de requêtes) tout en les traitant plus rapidement. Alors que pour une charge transactionnelle, il faut un haut degré de parallélisme. En même temps, l’archive peut fonctionner de manière flexible car il ne requit pas de performance importante ni de nombre élevé d’utilisateurs. Donc, l’archive peut utiliser un stockage moins optimisé.
- Les bases de données analytiques qui exécutent le même code des millions de fois profiteront de la vectorisation d’opérations (SIMD).
Est-ce que il existe des bases de données qui peuvent supporter différentes types de charges simultanément ?
Oui, de part mon expérience, DB2 BLU s’en sort pas trop mal (à la condition que vous gérez correctement le type de stockage de chaque table), MS SQL EE n’est pas mauvais (si vous utilisez beaucoup de RAM et Columnstore indexes). Oracle – probablement pas tout de suite…
Par contre, les bases de données spécialisées pulvérisent les records de performance, par exemple Sybase IQ (mes collègues ajoutent Vertica, Exasol et VectorWise) sur une « petite machine » peut fonctionner bien plus vite pour une charge analytique qu’un « petit cluster transactionnel d’O….. » et « écraser » le Hive.
En même temps, vous n’allez pas stocker plusieurs centaines de To de logs ou d’historique dans une Sybase IQ. Logiquement, il faudrait les placer sur Hadoop et les lire via Spark, Hive ou encore BigSQL.
Conclusions :
- Les bases de données sont nées différentes et c’est une bonne chose !
- Elles ont aussi une spécialisation – et c’est très bien ainsi.
- Le tuning perpétuel de la base de données par les DBA et l’insatisfaction de vos utilisateurs peuvent vous coûter plus cher qu’une licence d’une base spécialisée accompagnée par des spécialistes.
Bonne santé à vous et à vos systèmes.
Pingback: Use cases : Data Virtualization – Ordre d'informaticiens