
Aujourd’hui, je voudrais parler d’exemples d’utilisation d’outils MDM dans le secteur de la finance. Si vous voulez, vous pouvez consulter notre article pour plus de détails concernant chaque style de Master Data Management (gestion de référentiel) : https://ithealth.io/mdm-ce-que-ibm-semarchy-informatica-et-ebx-vous-cachent/.
Avant de parler de l’utilité d’un MDM, je vous propose un schéma ultra-simplifié des éléments importants pour l’analyse financière. Cela nous permettra d’organiser cet analyse :
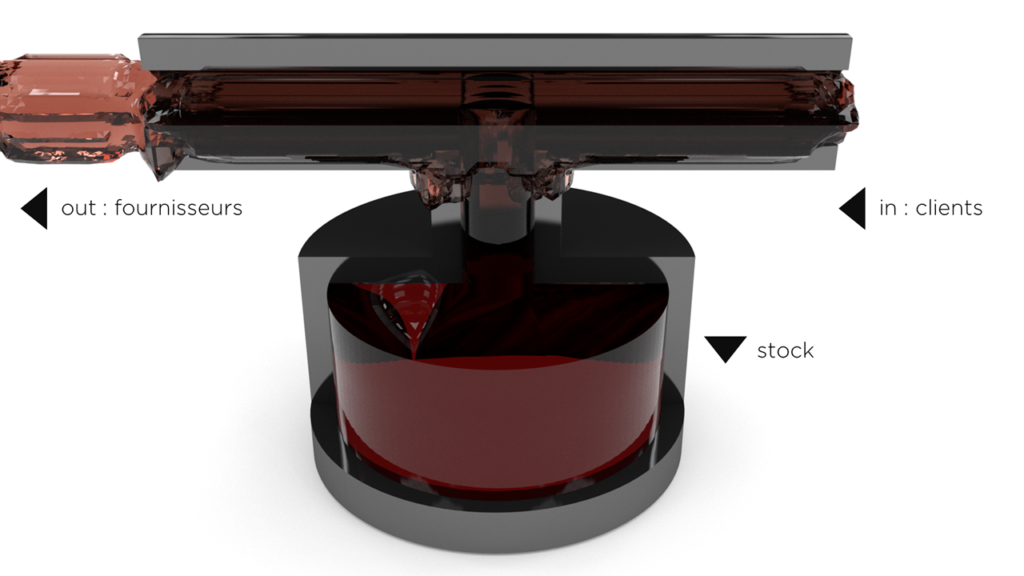
Nous pouvons imaginer n’importe quelle société sous la forme d’une machine, de la manière suivante :
- la source d’énergie est le flux « cash in » des clients qui nous payent pour nos produits ou services;
- …dont une partie « se dissimule » dans le fonctionnement de notre société (et cela n’est plus autant dans le secteur de la finance, mais dans la gestion et l’optimisation);
- …une partie tombe dans le réservoir dit du « stock » qui est le mal nécessaire pour notre société (et cela nous concerne);
- …et une partie est payée aux fournisseurs, « cash out ».
Nous pouvons jouer sur les configurations de la « machine » et nous allons obtenir des sociétés plus ou moins performantes :
- si nos clients nous paient immédiatement et nous avons un crédit vis-à-vis de nos fournisseurs, nous allons avoir de l’argent supplémentaire que nous pouvons investir où bon nous semble;
- si nous donnons des crédits à nos clients, mais nous devons payer en avance à nos fournisseurs, nous avons besoin de « cash » en plus;
- si notre stock est imposant, cela bloque une somme non négligeable d’argent qu’on aurait pu investir ailleurs;
- si nous réduisons le stock (d’où l’idéologie JIT, « just in time » de livraison), nous avons la possibilité de « libérer » de l’argent qui avait été auparavant gelé;
- s’il existe un risque de non-paiement de la part de client, nous perdons l’énergie de flux « cash in » et nous devrons la compenser.
Remarque : comme pour tout modèle basique, il y a un nombre d’exceptions, par exemple, le stock de cave à vin « produit de la valeur » lui-même car avec le temps le vin devient plus en plus chère, mais ce n’est pas un cas suffisamment général.
Cash In
Nous avons vu que du point de vue financier, les clients à qui nous devons faire attention ce sont ceux qui reçoivent le crédit et ici il y a deux dimensions :
- Gestion de risque lié au non-paiement du client qui est souvent accompli via un seuil de « credit limit », i.e. besoin de maîtriser le volume de crédit. Si dans les systèmes financiers, les clients existent en double/triple, la gestion du « crédit limit » devient rapidement ingérable et ouvre la porte aux risques imprévus (dépassement de limit).
- Gestion des cas de refus de paiement (recouvrement, « cash collection »), où les équipes des « collecteurs » négocient le paiement avec les clients qui n’arrivent pas à rembourser le prêt dans le délai prévu initialement. Dans ce processus, la performance des équipes peut être fortement dégradée dans le cas d’existence de doublons car le même client sera potentiellement contacté plusieurs fois par différents membres d’équipe.
Nous pouvons voir que pour les deux exemples, le paramètre le plus important c’est l’unicité d’objet « client » (tiers, personne) dans le référentiel.
Afin d’arriver à identifier uniquement les « clients » (sociétés ou personnes physiques) dans nos SI, il faut appliquer l’une des stratégies :
- avoir un seul SI FI ou un seul système de saisie des clients qui, au moment de la saisie, vérifiera l’unicité du client (exemple de la solution : rendre code TVA obligatoire, vérifiable et unique comme dans la solutions SAP);
- saisir les données dans plusieurs SI et en futur identifier et ré-consolider les « doublons ».
Même la première stratégie peut être difficile à mettre en place, surtout si nous parlons bien de personnes physiques. En effet, il n’existe aucun identifiant unique que l’humain ne peut pas changer. Dans cette situation, nous avons besoin d’un moteur de recherche des doublons, même si nous allons l’utiliser de manière préventive, afin justement d’empêcher la création du doublon, i.e. en mode « proactif ». Ce moteur s’appelle MDM Registre :
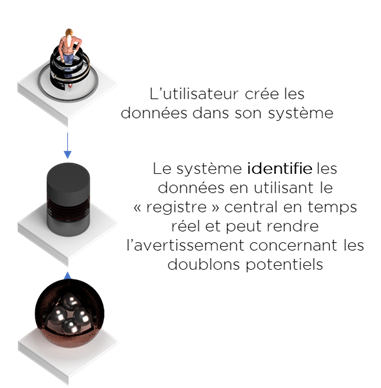
Soit dans le cas de plusieurs systèmes :
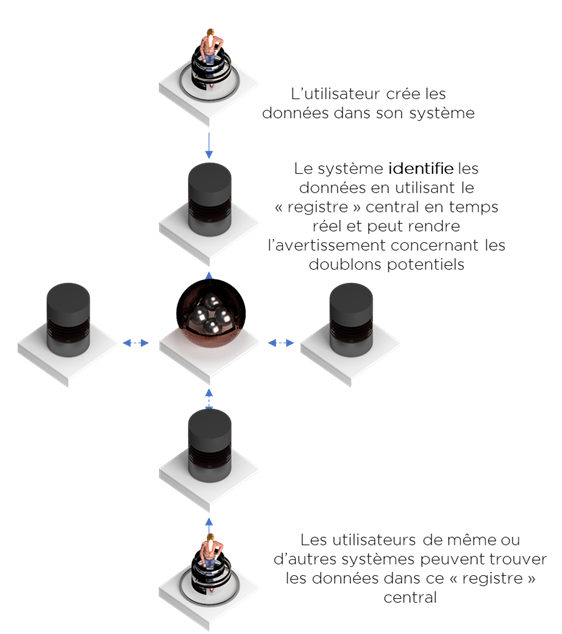
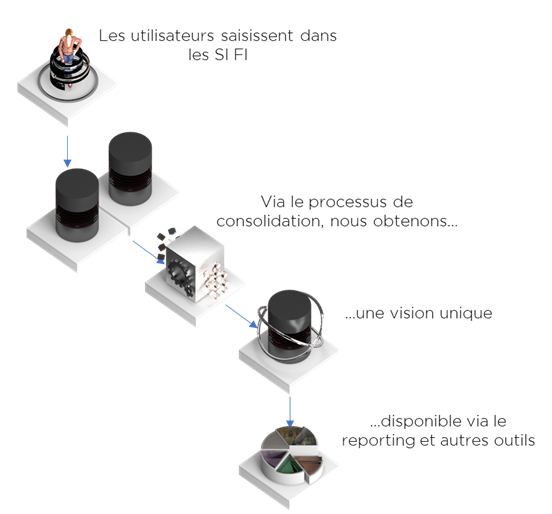
La stratégie de ré-consolidation peut également utiliser le même moteur d’identification et de rapprochement de données afin de trouver les doublons, mais il y aura des étapes techniques supplémentaires afin de constituer un seul, le « meilleur », représentant parmi les doublons (« golden record » ou « version unique de la vérité »). Les outils qui accomplissent à la fois le rapprochement et la définition du choix retenu s’appellent MDM de Consolidation.
Attention : les outils de MDM de Consolidation sont souvent incapables à proposer la fonctionnalité « proactive » du MDM Registre !
Stock
Le quantité minimale d’un produit donné dans le stock dépend fortement du type de business et de la qualité d’organisation des processus. Par contre, il existe une risque supplémentaire de gestion non-optimale du stock : ce sont les doublons dans le système de suivi.
Imaginons un exemple : pour la réparation des trains, nous devons gérer un référentiel d’un million de pièces détachées. Pour chaque pièce détachée, notre stock automatisé peut suivre la quantité restante, estimer la vitesse de consommation, anticiper la date de la commande suivante… En revanche, si certains produits sont en double cela peut poser des problèmes :
- Les données en double peuvent créer une situation où les produits restent indéfiniment sur les étagères.
- Si le système de commandes « consolide » les occurrences des produits, il peut arriver que la commande ne passe pas à l’heure (car le produit est vraiment toujours sur les étagères, mais sous un autre code), mais les ouvriers n’arrivent pas à trouver le produit sur le stock car le système de stock dit « hors stock » pour le code qu’ils connaissent.
Tout cela peut vous paraître peu probable, mais avec 1 million de produits et, en moyenne, 20% de doublons, cela va se passer quotidiennement. Le coût d’une commande urgente afin de ne pas bloquer les lignes de réparation (entre une centaine et des milliers d’euros) et le transport en urgence peuvent vite dégrader la rentabilité d’une société de réparation.
Pour une meilleure gestion de stock, nous devons garantir que les données concernant nous produits sont « en bonne forme ». Malheureusement pour nous, actuellement il n’y a pas de moyen sûr pour identifier les doublons parmi les données type « produit » avec une certitude quelconque si nous n’avons pas de « codes » des produits tels que EAN/UPC et c’est rarement le cas. De plus, notre définition de produit peut ne pas correspondre à celle de code EAN (ex. plusieurs produits remplaçants de plusieurs fournisseurs).
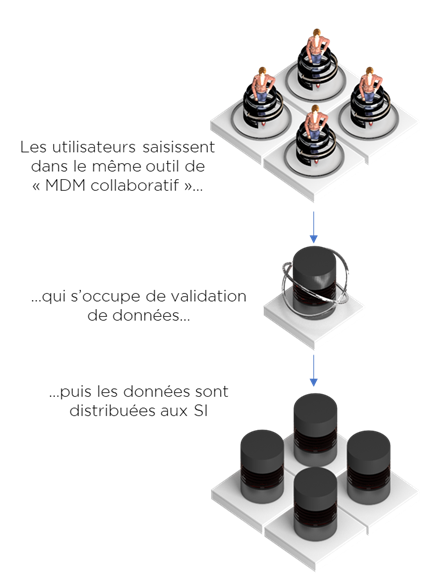
Dans cette situation, le seul choix c’est de constituer le référentiel propre dès le début (MDM Collaboratif, MDM PIM) : demander la saisie des descriptions complétées des produits, des spécifications techniques, utiliser la recherche proactive de doublons (i.e. contrairement à la consolidation « réactive » qui cherche les doublons déjà existants, la gestion « proactive » veut dire que nous essayons de diminuer la possibilité d’introduire les doublons), utiliser le même référentiel dans l’ensemble des processus fonctionnels.
Cash Out
La gestion du référentiel des fournisseurs c’est plutôt le domaine des achats (négociation de prix, gestion des propositions des concurrents) : une fois le période de paiement est négocié, la finance ne semble pas s’intéresser autant dans la question de la qualité de données dans la liste des fournisseurs… Ou si ?
Il existe encore au moins un sujet important pour notre flux – la gestion de doublons de factures des fournisseurs (accounts payables) car le même fournisseur peut, par erreur, envoyer la même facture sous un autre numéro et c’est à nous d’identifier ce cas (ou accepter de payer le même produit deux fois…).
Stop ! Les factures ne font pas partie de Master Data, n’est-ce-pas ?
En effet, les factures sur l’échelle transactions-référentiel-nomenclature sont plutôt proches de transactions, mais il n’existe pas de limite évidente entre les deux. De plus, nous pouvons appliquer les méthodes de rapprochement de données à certaines données « transactionnelles ».

Un autre point : si nous pouvons, avec une certitude élevée, identifier la source de la facture, le reste peut être plus facile car nous serons en mesure de comparer que les factures du même fournisseur entre elles.
Sinon, la gestion du référentiel des fournisseurs n’est pas très différente en termes d’approche que la gestion des clients et nous avons toujours les même choix :
- maintenir une seule source propre de données;
- … ou consolider les données en utilisant les approches MDM Registre ou MDM de Consolidation.
Conclusions
- « Unicité » de données (absence de doublons) est souvent le sujet important pour la gestion des risques.
- Les données propres permettent vraiment de réduire les risques et les dépenses.
- Chaque référentiel de votre société peut être géré différemment suivant la nature de données et les conditions finanço-technico-economico-politiques.
- Si vous avez un seul système de saisie qui propose des règles de validation avancées, vous n’avez pas besoin de MDM, très probablement.
Bonne santé à vous et à vos finances !