
♫ Au fond qu’est ce qu’on veut,
Philippe Katerine
Au fond qu’est ce qu’on cherche,
Quand on s’prend la tête,
Mais qu’est ce qu’on attend ♫
Dans ce premier article de notre nouvelle série « homebrew » (« fait maison »), nous allons tester une base analytique « pas comme les autres ». À noter qu’ici, vous n’allez pas trouver de tests précis ou une méthodologie développée, je laisse ce genre de choses à TPC (http://tpc.org/). Par contre, vous trouverez notre avis sur le sujet…
Pourquoi une base analytique ?
- le métier peut obtenir les résultats d’analyse de données rapidement,
- les data scientists qui ont déjà travaillé avec Spark confirmeront que c’est un outil génial, mais parfois il faut juste une base de données que nous pouvons requêter avec SQL, base plus réactive que Spark grâce aux indexes, statistiques, etc…
- les opérateurs peuvent croiser les indicateurs de performance des machines avec SQL,
- l’IT, au service du métier, peut se simplifier la vie : les requêtes fonctionnelles récurrentes ne nécessitant plus l’optimisation perpétuelle des paramètres de la base de données,
- les DevOps qui aiment quand tout est « cloudy » aimeraient parfois tester des idées folles sans avoir peur de recevoir des factures excessives…

Pour synthétiser, tout le monde a besoin de base analytique…
Bases anaytiques
Pour rappel, les bases analytiques (pour DWH / DataMarts / analyse de time series) exploitent l’asymétrie de la charge – elles sont taillées pour réaliser des « selects » plus rapidement possible en contrepartie du temps d’insertion unitaire (les « loads » sont toujours performants) :

Comment ça marche ?
Les bases analytiques utilisent un certain nombre de techniques pour gagner en performance sur les requêtes complexes :
- diminution d’accès disque : compression de données sur le disque, stockage de données « en colonne », où chaque segment de données stock seulement les données de même champ / même type de données (localité de données),
- utilisation d’instructions SIMD de CPU (en plus au parallèlisation entre cores),
- diminution de « cash misses » de CPU,
- optimisation plus avancée de requêtes SQL,
- compression de données en mémoire vive,
- fonctionnement en cluster,
- autres techniques d’indexations de données, data skipping,
- etc.
Si l’ensemble des techniques est combiné, les performances peuvent être accrues d’un facteur de 5x à 50x suivant les cas en comparaison avec les bases de données « transactionnelles ».
Nos tests
Nous avons voulu trouver une base analytique pas chère (pas comme Sybase IQ ou HANA), voire gratuite, facile à prendre en main, avec une maturité certaine, disposant d’un support professionnel si nécessaire… et nous pensons l’avoir trouvé !

ClickHouse est un produit développé en interne pour les besoins analytiques des différents services composant Yandex (Yet Another iNDEXer), société ayant un développé un moteur de recherche https://yandex.com/ qui est un concurrent de Google et avec qui il se partage le marché russe.
Clickhouse est une base analytique qui :
- est utilisée en production par Yandex, Badoo, Cloudflare, Bloomberg et autres (https://clickhouse.tech/docs/en/introduction/adopters/),
- basée SQL,
- supporte nativement la gestion des clusters,
- utilise de nombreuses techniques dont nous avons parlé,
- est gratuite (« free as beer »).
Lançons les tests… J’aurais pu utiliser un serveur avec 128 Go de RAM, mais j’imaginais plutôt une personne « lambda » avec un ordinateur portable probablement assez puissant (SSD). Cet utilisateur peut être toujours confiné chez soi donc j’utilise une VM avec 1 vCPU et 4 Go de RAM…
Ce que m’intéresse c’est la facilité d’obtenir un résultat intéressant sans effort colossal donc j’ai posé cette question sur LinkedIn et 9 personnes ont répondu :

Et votre base de données répond avec quelle vitesse sur un Data Mart avec 200 millions de lignes ?
J’ai installé Ubuntu (RIP CentOS) et puis j’ai suivi juste les notes de QuickStart (https://clickhouse.tech/#quick-start) :
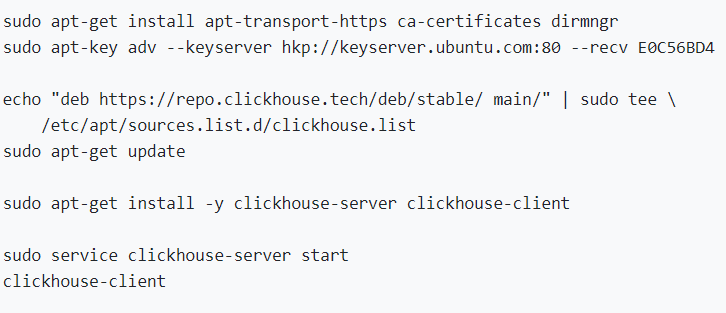
Je n’ai fait aucune configuration supplémentaire !
Maintenant il nous faut des données, donc j’ai utilisé le schéma de cet exemple : https://clickhouse.tech/docs/fr/getting-started/example-datasets/star-schema/ et les données générées par dbgen (https://github.com/vadimtk/ssb-dbgen) avec l’option « -s 30 » pour obtenir autour de 200 millions de lignes.
Le chargement de données a forcément pris un peu de temps, mais rien de surprenant pour cette volumétrie. En plus, j’ai installé l’outil DbVisualizer (https://www.dbvis.com/) pour réaliser mes tests – commençons…
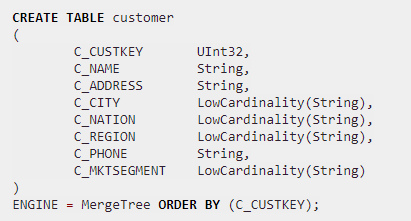
Remarque. Durant la création de modèle vous pouvez voir les types de données étranges comme LowCardinality(String) – ce sont les informations pour le moteur de compression de données, « Low Cardinality » veut dire « il y aura peu de valeurs distinctes » :
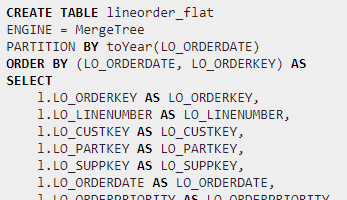
Remarque. Si vous créez une structure dénormalisée pour le même Data Mart (les outils DataViz seront contents!), vous verrez que la table peut être partitionnée et organisée suivant les différentes clés. C’est important pour optimiser l’accès sur la dimension « temps », mais techniquement vous pouvez créer les indexes plus tard (on en reparlera dans un autre article) :
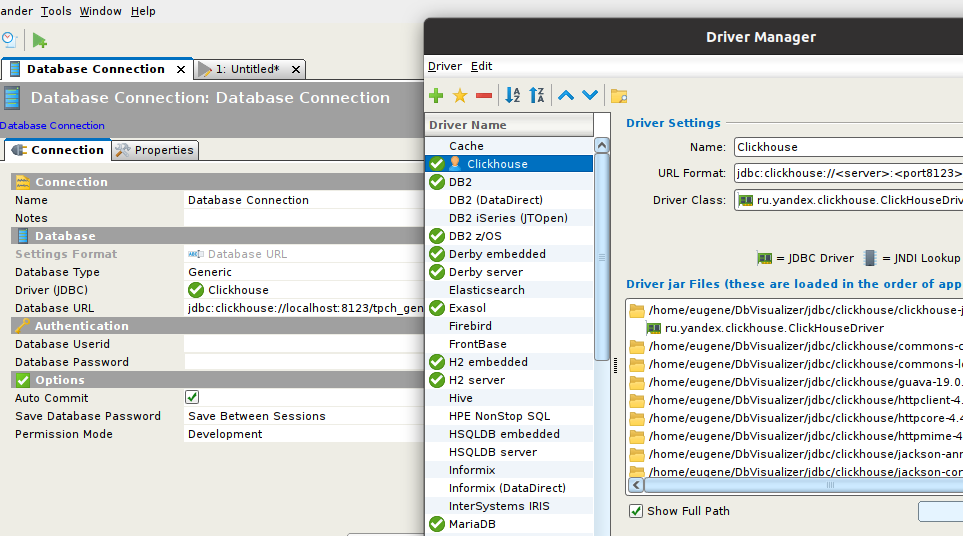
Il faut se dire que ClickHouse a plusieurs méthodes de connexion : via JDBC, ODBC, protocole MySQL (pourtant le dialecte de ClickHouse n’est pas exactement le même et il supporte un nombre d’extensions).
J’ai utilisé le driver JDBC que j’ai du l’importer dans DbVisualizer :
…mais le JDBC de ClickHouse a des timeouts assez courts par défaut, donc il faut les ajuster – la stratégie est simple – trouver tous les paramètres de « Timeout » ou « time » de notre connexion et le passer à 300 000 ms ou plus :
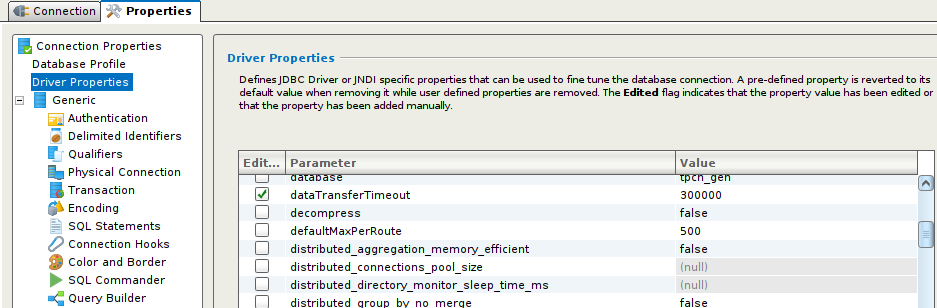
Remarque. Si vous lancez un « insert » depuis la connexion via JDBC et vous avez un « timeout », l’insert va se finir correctement malgré tout. Par exemple, la création de la table lineorder_flat a pris un temps important, donc DbVisualizer a arrêté de la suivre après 5 minutes. Ce qui n’a pas empêché la table d’être créée correctement.
Voici me premiers tests :
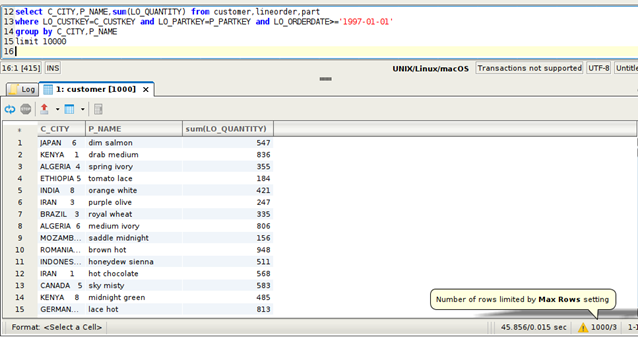
- « Group by » classique sur les attributs de deux dimensions et un filtre sur une année (j’ai limité la sortie à 10 000 records, mais ça ne change pas le temps de réponse) environ ~19,6s.
Il est clair que ma VM a été trop « petite » car ClickHouse a utilisé toute mémoire disponible et utilisé le SSD à 100%, mais il a réussi sortir le résultat en moins de 20 secondes.
Cette requête traite 18 676 386 lignes de lineorder (table de faits, 200M+ en total).

- La requête sur une période plus large, traitant 50 540 825 lignes est proportionnellement plus longue : 45,9s (2,3x temps pour volume 2,7x) – mais c’est très bien car complètement prédictible:
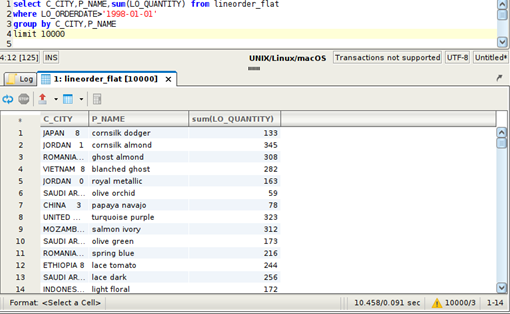
- Maintenant si on utilise la structure dénormalisée (i.e. la table de faits pré-jointée avec les dimensions aka « morte de Kimball ») on trouve que le temps se divise par deux (cela semble systématique).
Je pense que c’est une bonne nouvelle pour les data scientistes ayant besoin de préparer de grandes volumétries de données utilisant des datasets « plats » :
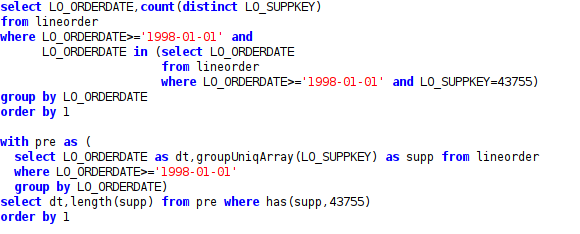
- Je ne peux pas passer à côté d’une fonctionnalité unique qui peut être utile pour les requêtes « embêtantes ». Par exemple « compter le nombre des clients le jour où le client X est venu »… c’est le cas où vous devez utiliser le « in » ou faire la jointure de la table avec elle-même.
Dans le ClickHouse vous pouvez exécuter les deux requêtes suivantes et obtenir le même résultat, mais la deuxième requête (même si elle est un peu plus lente) me semble être plus jolie – et c’est à cause de type « array » nativement supporté par ClickHouse… et contrairement à certaines autres bases de données nous avons des « lambdas » que nous pouvons appliquer aux arrays…
- J’ai aussi testé l’index… en fait les indexes dans Clickhouse sont juste les métadonnées pour le data skipping – notez le « type » d’indexe (ici minmax – stocker la valeur minimale et maximale pour chaque segment de données)… et de plus nos tables sont déjà organisées suivant la « clé primaire », mais assez bizarrement avec les indexes suivants j’ai pu gagner encore 4 et 2 secondes sur la première et troisième requête respectivement (voir la documentation pour les indexes ici : https://clickhouse.tech/docs/fr/engines/table-engines/mergetree-family/mergetree/)

Mes conclusions
Sans prise de tête je peux optimiser mes requêtes analytiques / ELT / data prep… Je suis au courant qu’il existe Spark et d’autres outils pour le traitement de données, mais ici j’ai une vrai base de données à ma disposition et elle est ordres de magnitude plus rapide que Spark ou une base « classique » sur les charges « analytiques ».
De plus, contrairement à Sybase IQ, HANA, VectorWise et les autres, elle est gratuite… et utilisable dans le cloud.
Je crois que j’ai trouvé mon nouveau jouet préféré. Il peut être utile pour un certain nombre de mes projets (et aussi aux data scientistes, consultants BI, flux, etc.). Qu’en pensez-vous ?
Bonne santé à vous et à vos technologies ! Bonnes fêtes !