
Le SQL est devenu une compétence pratiquement obligatoire pour tout informaticien (au moins l’expression « select ») pour les raisons suivantes :
- un développeur d’application métier utilisera un ORM, mais dans les cas complexes/debug devra passer par SQL,
- un chef de projet IT doit pouvoir analyser les données – il utilisera probablement le SQL,
- un consultant BI manipulera des objets dans les « univers » avant qu’il ne doit descendre plus bas pour vérifier le code SQL généré,
- les spécialistes en Intégration d’Information, Data Quality, Master Data Management devront accéder aux nombreuses bases de données chaque jour,
- les data scientists doivent prémâcher les données et même s’ils travaillent avec Spark, il existe du Spark SQL (et je ne parle pas de BigQuery, BigSQL, Hive, etc).
Je pense que la structure suivante de « select » est connue de tous, si besoin :
| SQL | Description |
|---|---|
| select … | choix des champs / calcul |
| from … | choix des tables / jointures |
| where … | filtre (ou encore jointure pour les « inner joins ») |
| group by … | les clés d’agrégation |
| having … | encore un filtre, mais après agrégation |
| order by … | champs de trie de résultat |
Nous pouvons imaginer le « select » comme la chaîne suivante :
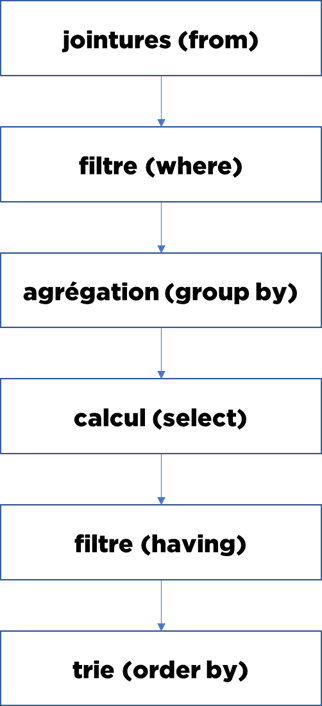
La plupart de personnes qui pratiquent le SQL savent qu’une requête « select » peut être couplée à une autre, avec deux possibilités :
- sous-requête
select ... from (select .. from ...) t1 ....- expression commune
with
t1 as (select ... from ...),
t2 as (select ... from ...),
select ... from t1 ...La deuxième approche (expression commune) permet de diminuer les répétitions dans les requêtes complexes. Elle est supportée par la majorité des bases de données (sauf MySQL qui permet, à ma connaissance, uniquement les sous-requêtes).
Par contre, sauf erreur de ma part, l’utilisation des expressions communes récursives reste pour la majorité de spécialistes le domaine « Vaudou ».
À noter que différentes bases utilisent une syntaxe un peu différente. Cela peut nécessiter des modifications mineures de la configuration pour « permettre » les requêtes récursives.
Voici un exemple de la requête récursive pour PostgreSQL qui génère 1000 lignes à partir de « rien du tout » :
with recursive
t(i) as (
select 1
union all
select i+1 from t where i<1000)
select * from tComment ça marche ?
- nous initialisons une expression commune (t avec un champ i, mais le nombre de champs peut être différent),
- dans cette expression commune nous avons deux parties :
- initialisation qui crée les premières lignes de la réponse (dans notre cas une seule ligne) : « select 1 »,
- fonction récursive avec une condition de la fin : « select i+1 from t where i<1000 » (attention au fait que nous faisons une sélection depuis la même table qu’on génère),
- le moteur de la base de données « reconnait » le pattern récursif et exécutera la deuxième partie de la requête jusqu’au moment où elle n’en produira plus aucune donnée (d’où l’importance du filtre).
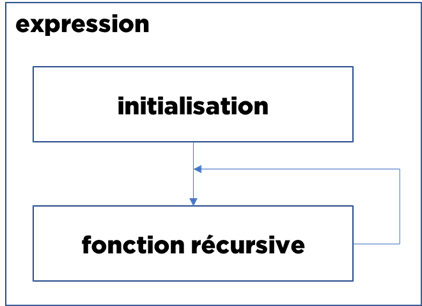
A quoi peut bien servir cette fonctionnalité ?
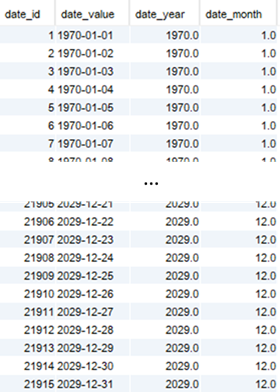
Exemple : génération de dimension « date » (encore PostgreSQL, mais possible sur la majorité de bases de données avec un minimum d’ajustements) :
with recursive
t(date_id, date_value) as (
select 1,
cast('1970-01-01' as date)
union all
select date_id+1,
cast(date_value+interval '1 day' as date)
from t where date_value<cast('2029-12-31' as date))
select date_id,
date_value,
extract(year from date_value) as date_year,
extract(month from date_value) as date_month
from t… et voici le résultat :
Exemple : dénormalisation d’arbres.
Supposons que nous avons un arbre (ou forêt) de la structure suivante dans une table « tree » :
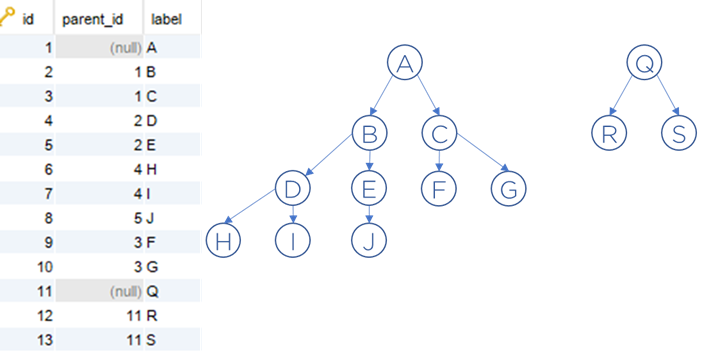
Nous voulons trouver les « chemins » à partir de la racine pour accéder à chaque nœud. Voici la solution :
with recursive
steps(id,steps) as (
select id,
cast(label as varchar(1000))
from tree where parent_id is null
union all
select tree.id,
cast(steps.steps||'->'||tree.label as varchar(1000))
from tree, steps
where tree.parent_id=steps.id)
select * from steps… et voici le résultat qu’on peut utiliser dans notre dimension, par exemple :
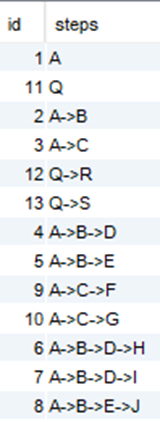
Comment ça marche ?
- toute la magie se passe dans l’expression commune,
- avec notre première requête on choisira les racines d’arbres car elles sont faciles à identifier vu qu’elles n’ont pas de parents (ignorez « cast » – c’est une partie « technique ») :
select id,
cast(label as varchar(1000))
from tree where parent_id is null- par la suite dans la partie récursive (après « union all »), nous prenons les descendants directs de nœuds déjà traités :
from tree, steps
where tree.parent_id=steps.id- et on les concatène avec le chemin jusqu’à leurs parents (qu’on a déjà trouvé précédemment) :
select tree.id,
cast(steps.steps||'->'||tree.label as varchar(1000))
from tree, steps
where tree.parent_id=steps.idVoici donc l’exécution de l’algorithme étape-par-étape:

Facile n’est ce pas ? Le tout sans le moindre script Python !
Pour plus d’exemples, je vous propose de regarder dans DB2 Cook book – un livre incroyable, même si la version originale commence à dater (DB2 est une base de données très standard, il ne faut pas avoir peur si vous n’êtes pas client d’IBM) : https://ithealth.io/wp-content/uploads/2020/06/DB2V97CK.pdf
Bonne santé à vous et à vos systèmes !
Pingback: don’t-do-it : Un séquenceur impératif pour un grand projet – Ordre d'informaticiens