
Aujourd’hui, je voudrais aborder le problème des données insaisissables dans les dimensions « Master Data ».
Supposons que vous avez une dimension « client » ou « fournisseur » (« personne », « lieux », etc) dans votre entrepôt de données. Vous aurez probablement un nombre important de tables de faits qui pointent vers cette dimension.
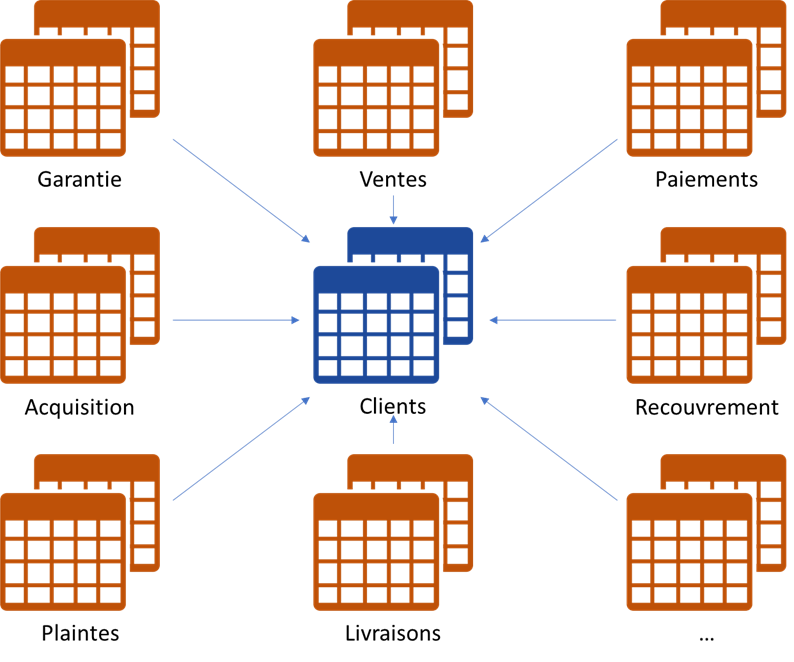
Supposons maintenant que vous cherchez la perfection d’état des données de votre entrepôt, donc vous utilisez une approche statistique pour le rapprochement (https://ithealth.io/rapprochement-de-donnees) de vos « clients » ou « fournisseurs » (ou autre structure « Master Data » aussi important).
Dans ce cas, vous avez des Data Stewards qui essaient de régulariser tout problème de rapprochement des données (ex. identifier les doublons complexes ou diviser les faux positifs).
Rapprochement & faux négatifs/positifs
Supposons que vous avez deux enregistrements (records) dans votre dimension « client » – et votre système automatique n’est pas en mesure d’identifier les deux comme doublons (cas faux négatif) :

…par la suite, un Data Steward a fait une recherche et a déterminé qu’en réalité, les deux décrivent le même objet – et a donc procédé à la fusion de ces records :
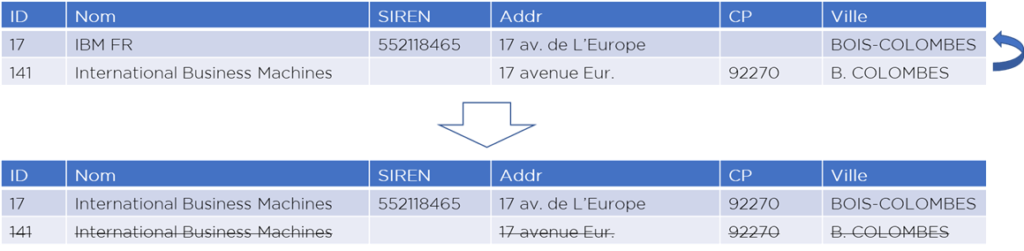
Question : que doit-il se passer dans les tables de faits ?
Vu que les tables de faits ont une clé étrangère qui pointe vers la dimension en question, on doit la mettre à jour – et ce n’est pas compliqué (update fait set id=17 where id=141) en cas de rapprochement de deux lignes, mais que va-t-il se passer si on identifie un faux positif ?
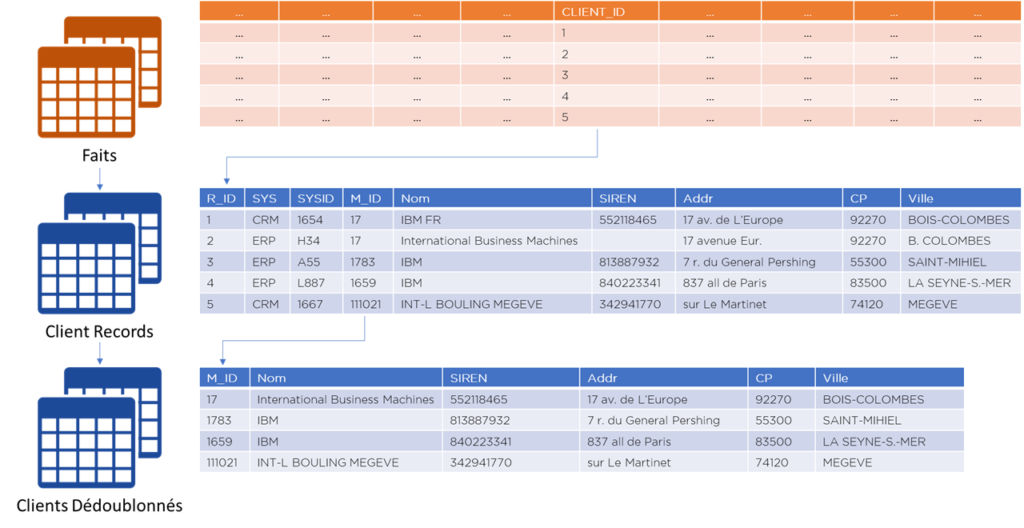
Supposons que maintenant nous avons une seule ligne dans la dimension client :

En utilisant la Landing Area et la transcodification, nous pouvons voir les différentes sources qui la composent :
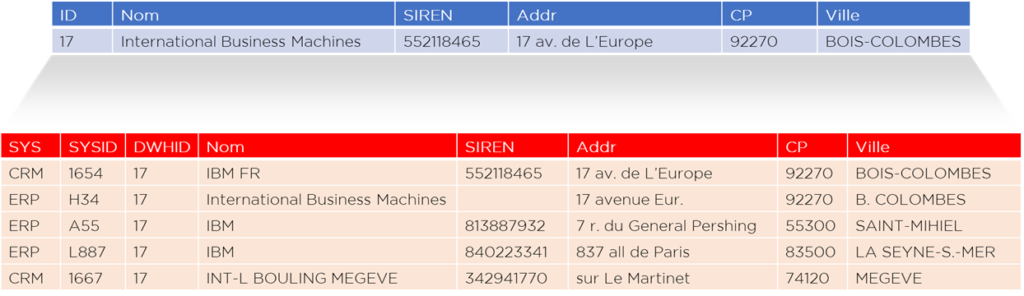
Le Data Steward doit diviser cette ligne car un faux positif est un erreur que nous ne pouvons pas tolérer :

Dans ce cas, nous aurons 4 lignes dans la dimension « client » :
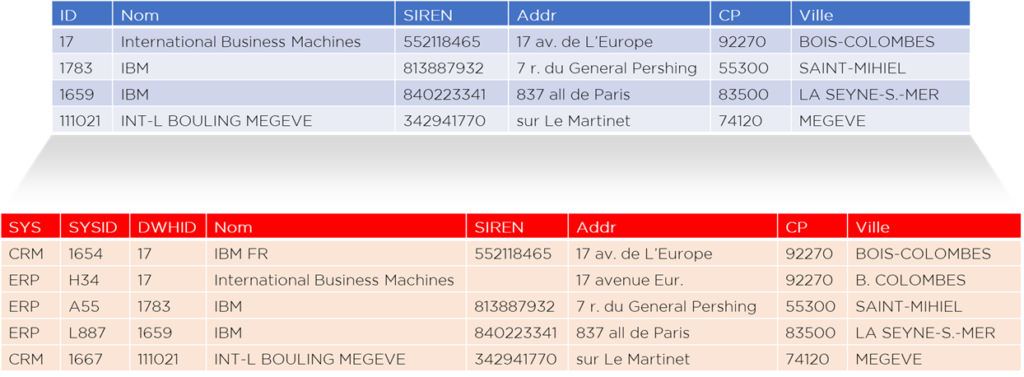
… mais que doit-il se passer dans les tables de faits ? Où allons-nous prendre les données concernant les anciens IDs (logiquement nous devons maintenant repasser sur tous les faits qui sont attachés à l’ancien ID client « 17 » et les mettre à jour) ?
- Nous pouvons garder les IDs des systèmes sources dans les tables de faits, mais c’est contre les normes de modélisation B.I. et si vous utilisez Oracle ou une autre base non-analytique, ça peut dégrader la performance.
- Nous pouvons avoir une Landing Area qu’on ne purge jamais – cela peut être notre source d’information, mais il faut prévoir la reprise de données sur chaque table de fait (ou rendre la jointure avec transco incrémentale : https://ithealth.io/boostez-la-performance-de-vos-flux-10x/).
- Ou… nous pouvons créer une hiérarchie de la dimension « client ».
Solution contre-intuitive
En effet, nous pouvons dire que nous avons bien deux objets différents qui forment une hiérarchie :
- A: écriture telle-qu’elle (« non-rapprochée ») dans un SI source,
- B: écriture rapprochée/dédoublonnée à partir de plusieurs écritures « A ».
Pour les hiérarchies nous avons deux choix :
- dé-normaliser en une table afin de diminuer le nombre de jointures (mais complexifier les flux),
- laisser les tables séparées – et vivre avec les flocons hiérarchies.
C’est la deuxième solution que je propose de considérer ici :
- toute table de faits fais référence aux données non-rapprochées,
- la table avec les données non-rapprochées pointe vers la table de données rapprochées,
- toute opération de rapprochement/division des faux positifs impacte seulement ces deux tables de dimension,
- si l’utilisateur du système analytique veut analyser la composition de données rapprochées – il peut le faire facilement car ces données sont présentes dans le premier niveau d’hiérarchie de la dimension.
Conclusions
Nous avons proposé une approche de stockage de dimensions rapprochées avec un moteur statistique. Cette approche permet facilement (sans re-calculation de tables de faits) accomplir le rapprochement/division de faux doublons (action fréquente pour les DWH bien gérés).
En plus, vous pouvez garder les champs de type « clé fonctionnelle » (code client, identifiant CRM, etc) dans la table de données « non-rapprochées » et les enlever dans la table de données « propres ». Cela permet de résoudre (partiellement) le problème perpétuel de perte de données durant dédoublonnage.
Il y a deux « problèmes » avec cette approche :
- nous allons accomplir une jointure de plus dans presque tout rapport créé,
- nous devrons visiblement abandonner l’idée d’Inmon de consolidation de données dans CIF (Corporate Information Factory).
Qu’en pensez-vous ?
Bonne santé à vous et à votre DWH.