
A problem well stated is a problem half-solved
Charles Kettering
La qualité de données (Data Quality) semble être un sujet parti pour durer. Les approches d’intégration de données, les éditeurs, les visions vont venir et partir, mais ce problème est visiblement plutôt philosophique que technique.
Quand on cherche à trouver une définition complète de la qualité de données, on trouve de nombreuses approches :
- (via la liste de paramètres souhaitable) la qualité de données c’est le degré de perfection des données suite aux différents axes (dimensions) : complétude, consistance (conflits dans les données), respect de format, précision (données à jour), doublons, etc.
- (données comme un canal de communication) la qualité de données c’est la mesure de « pureté » ou de « précision » de la transmission d’information via un système informatique.
- (via les processus) la qualité de données c’est un processus de planification, implémentation et contrôle d’activités qui appliquent certaines techniques.
On a des problèmes donc … et vous qu’est-ce que vous en pensez ? Notre définition est :
- soit une liste d’actions sans précision de résultat,
- soit une vision abstraite,
- soit un processus déjà bien défini (et la définition se mord la queue).
Je souhaite trouver une définition qui nous permettra d’évaluer la qualité de notre approche par rapport à un certain but, qui soit suffisamment flexible pour s’appliquer aux différentes situations tout en étant assez technique. Idéalement, il faudrait aussi une définition en forme de théorie qui explique pourquoi nous avons des problèmes de qualité des données.
Voici la définition que je vous propose, mais pour être franc, je n’ai pas encore réussi d’obtenir quelque chose de pleinement satisfaisant, même si elle fonctionne en l’utilisant sur des projets :
La qualité des données est un jugement concernant l’utilité des données, dans un contexte donné, souvent du point de vue d’un processus métier par rapport aux données générées par un autre processus métier.
Décryptons :
- Un jugement reste un jugement – ce n’est pas une propriété toujours correctement mesurable sans contexte métier.
- Un jugement qu’on applique est valable dans un certain contexte, i.e. il est possible que les mêmes données soient considérées comme « bonnes », et dans un autre – « mauvaises ».
- Du point de vue de la définition, les dimensions de qualité de données (complétude, consistance, etc) sont les souhaits qu’un processus applique aux données d’un autre processus.
Implications :
- Pour rendre la qualité des données mesurable, il faut appliquer les mesures dans le contexte d’un processus consommateur de données. Assez certainement les bonnes mesures seront en Euro, Dollars, Yen, etc. Cette approche permettra de décider s’il faut corriger les données ou le processus.
- Quand un manager remonte un problème de qualité des données, il faut se poser la question : pourquoi pense-t-il que les données sont « mauvaises » et en quoi doivent-elles être différentes : est-ce que les processus ont les mêmes définitions des données, mêmes obligations, etc. On touche à la gouvernance des définitions.
- Il ne faut pas essayer de respecter l’ensemble des dimensions de qualité des données – uniquement celles qui sont nécessaires pour les deux processus visés.
- La qualité de données ne tourne pas autour des mesures encore moins des outils – elle concerne surtout des processus, des obligations et des moyens.
- La qualité de données ne doit pas forcement être « bonne » – elle doit être « suffisante ».
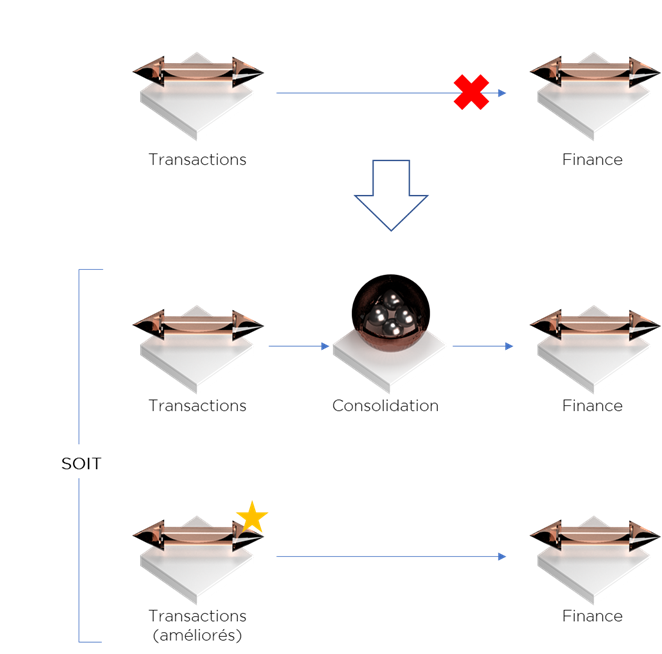
Exemple. Une société a des problèmes de consolidation des crédits donnés à ses clients. L’information à propos de ses clients est dispersée dans une multitude de systèmes transactionnels. Admettons que le département financier remonte un problème de qualité des données. Par contre, les systèmes transactionnels ne sont pas conçus pour gérer les référentiels de données et surtout les processus fonctionnels actuels ne le permettent pas. Si on reprend notre définition, dans notre exemple, le problème est qu’un processus est inter-dépendant d’autres processus en matière de données sans que le premier le sache. Il s’avère que le premier ne dispose pas des moyens pour satisfaire les besoins du deuxième. Pour résoudre ce problème, nous pouvons mettre en place un outil de consolidation (aka Data Quality ou Data Hub) ou ajuster le premier processus afin qu’il puisse mieux gérer son référentiel (modifier ou remplacer les SI).
Qu’en pensez-vous de cette définition ? Laissez-nous un commentaire et indiquez nous si vous appréciez l’article.
Bonne santé à vous et à vos systèmes !
Pingback: Data Quality : vision à l’inverse et Qualitysigner – Ordre d'informaticiens