
I am not impressed
George Karlin. On religion
Aujourd’hui je voudrais parler de la qualité de données dans un monde parallèle. Ne fermez pas la fenêtre – ça changera, probablement, votre avis.
Nous avons donné une définition à DQ précédemment :
La qualité des données est un jugement concernant l’utilité des données, dans un contexte donné, souvent du point de vue d’un processus métier…
Source : https://ithealth.io/definir-la-data-quality-notre-proposition/
Nous avons essayé de relativiser la compréhension de la notion de la qualité de données – ce n’est pas quelque chose qui existe « hors du contexte métier »… ou si?
Problèmes évidents
Concrètement, dans la majorité des cas d’usage il n’est pas très important si vous écrivez l’adresse du client en TOUTES MAJUSCULES ou en minuscules, de même il n’est pas très important si vous écrivez « av. » au lieu de « avenue », il n’est pas si important si vous mettez la forme juridique dans le champ « raison sociale » ou pas…
Par contre, il y a des choses plus difficiles à ignorer :
- doublons dans la liste de tiers, produits, contrats, factures, matériel,
- information concernant une charge d’un container qui dépasse ses capacités 100x,
- numéro de téléphone qui manque des chiffres,
- numéro de sécurité sociale incorrect,
- code d’emplacement sur stock inexistant,
- facture pour le nettoyage d’un train que personne ne peut identifier,
- un enfant avec une date de naissance dans le futur…
Notre premier réflexe, c’est de corriger l’erreur et de trouver le coupable. Finalement c’est quelque chose qu’on sait faire.
A mon avis, il ne faut pas se poser la question: qui était cet utilisateur lambda qui a saisi les données incorrectes… C’est contre-productif.

Est-ce qu’il existe un autre tao (chemin)? On va essayer de le trouver ensemble.
Regardons ailleurs… En informatique nous faisons beaucoup d’erreurs, mais il existe un nombre d’outils / méthodes préventifs dont les développeurs sont équipés :
- IDE (outils de développement),
- tests unitaires,
- tests d’intégration,
- statistic code analysis,
- etc…
Parfois les informaticiens parlent de niveau de couverture du code par les tests automatisés afin de dire que le code est plus ou moins fiable… De plus, nous avons « canary deployment », « blue-green deployment » et autres modes qui permettent de diminuer l’impact des bugs en production (blast radius)…
Est-ce que nous pouvons appliquer le même modèle à la qualité de données? J’en suis certain. Si on compare la maturité de projets de la qualité de données avec la maturité de certaines équipes de développement, nous verrons que :
| tests en… | développement | Data Quality |
| par vitesse | très proactifs (i.e. ils réagissent avant que le développeur finisse son travail) | les outils de DQ de top de carré magique de Gartner sont réactifs (basés sur ETL, ils réagissent jours ou mois après que l’erreur avait été introduit) |
| par couverture | exhaustifs | très pointus |
| par mise en place | équipes de développement peuvent à tout moment ajouter et supprimer des tests | tests DQ prennent du temps pour mettre en place et nécessitent le cycle spéc/dev/test/prod |
| par l’aide à l’utilisateur | IDEs des développeurs aident à la saisie du code | les outils ERP de point de vue de saisie de données ressemblent à une version graphique de Notepad |
| par certitude | tests complexes en développement (ex. static code analysis) peuvent donner des fausses alertes et c’est Ok car il y aura un humain pour réagir | les tests DQ sont souvent assez « floues » pour ne détecter que des erreurs sûrs et certains car ils fonctionnent souvent en batch et donnent des KPIs |
| par la maîtrise des conséquences | on essaie de maîtriser le blast radius en dev | dans le monde DQ l’erreur peut faire beaucoup de mal avant qu’il est identifié et corrigé |
Autrement dire :
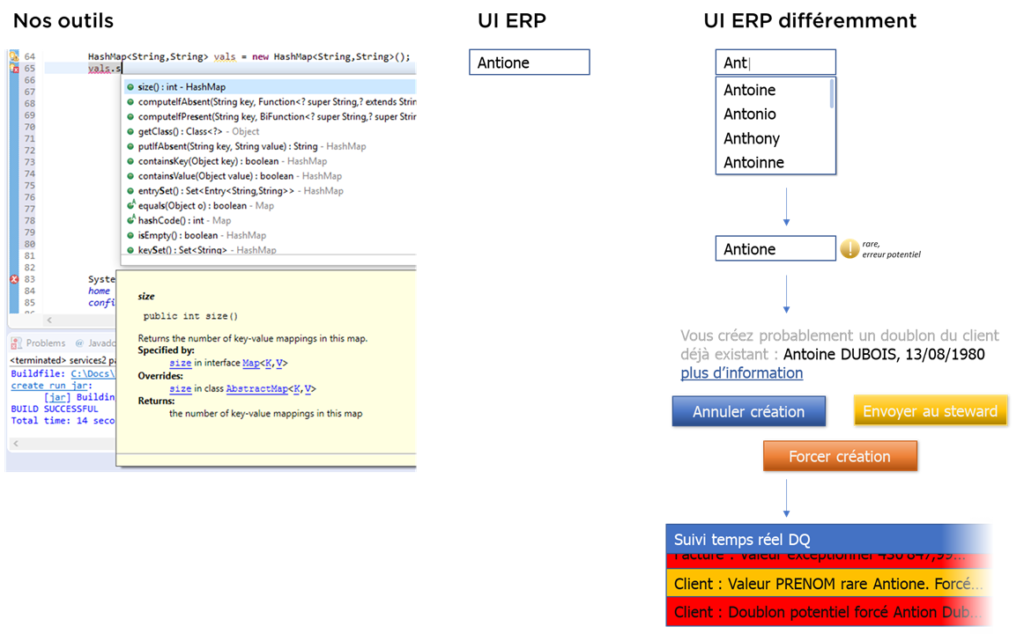
Conclusion intermédiaire :

Causes
Quelle est l’origine de cette situation?
Pourquoi le métier décide de mettre en place un outil? (Aidez-moi via la forme de contact si j’ai oublié des sujets importants).
- Diminuer la charge de travail, surtout en termes de tâches répétitives.
- Aligner les processus métier.
- Améliorer le service et diminuer les coûts
- Simplifier l’analyse de la situation (votre reporting, AI, tout ça).
Quel objectif poursuit le vendeur? Vendre. Il vous réalisera l’automatisation, fera probablement l’étude de best practices des processus métier, ajoutera le reporting…
Vous voulez la qualité de données? Probablement, il vous vendra des outils en plus aussi…
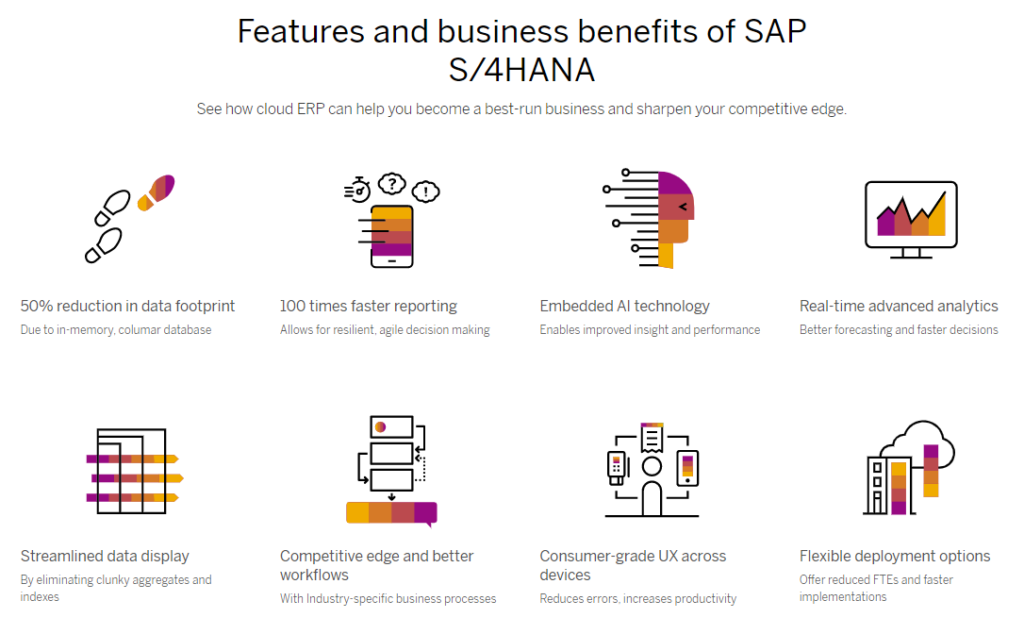
J’ai pris l’exemple de SAP car c’est l’un des éditeurs / vendeurs les plus connus dans le domaine. Voyez-vous la notion « reduces errors » cachée dans « consumer-grade UX »? A noter que SAP effectivement implémente certaines validations de données, mais elles sont tellement basiques, pas du tout complètes et de plus elles sont parfois si limitantes que durant la mise en place de l’ERP, elles sont désactivées.
En plus vous êtes coupables. Oui, vous. Si vous achetez un système d’automatisation, vous vérifiez quels paramètres? Disponibilité en cloud? Nombre de fonctions que vous pouvez acheter? Le prix? Joli interface web?

Futur
Je peux faire une prédiction ? Je pense qu’en futur proche nous allons voir le nouveau métier apparaître : qualitysigner (ou qualityops, qualitiste, <envoyez-moi votre proposition>). Le rôle de ce spécialiste sera de mettre en place un tel UI et tels modèles de données et algorithmes de validation que tout système ERP/CRM/TMS/FI/… aidera vraiment les utilisateurs de gérer la qualité de données sans aucune formation supplémentaire (juste comme vous n’avez pas passé de formation pour utiliser votre smartphone).
Je rêve qu’un jour :
- je vais saisir un client et le système m’avertira que j’ai probablement fait un erreur de saisie, puis le système vérifiera automatiquement pour moi que je ne crée pas de doublon,
- je vais importer la facture – et le système m’avertira de double paiement potentiel (et pas que moi – mon responsable également si la somme est assez importante),
- je vais saisir l’adresse – et le système le validera,
- le système saura faire une distinction entre « société », « établissement », « contact » et « compte »,
- dans les situations où je trouve un erreur et je n’ai pas de droit de le corriger – le système sera assez gentil pour me laisser faire une proposition de correction sans sortir d’outil et sans créer de ticket,
- le métier pourra renforcer les règles de validation si nécessaire,
- sinon les algorithmes vont analyser les données existantes et détecter les « outilers » encore au moment de saisie,
- les erreurs introduits dans les systèmes seront remontés aux chefs d’équipes ou aux Data Stewards et ils pourront analyser la situation chaque jour avant que les données n’arrivent dans le BI ou dans les autres SI,
- il n’y aura plus de Master Data Management,
- …ni d’outils externes de qualité de données.
Quand qualitysigner verra les « Maturity Models » de nos jours, il certainement s’exclama juste : « N’importe quoi ! »
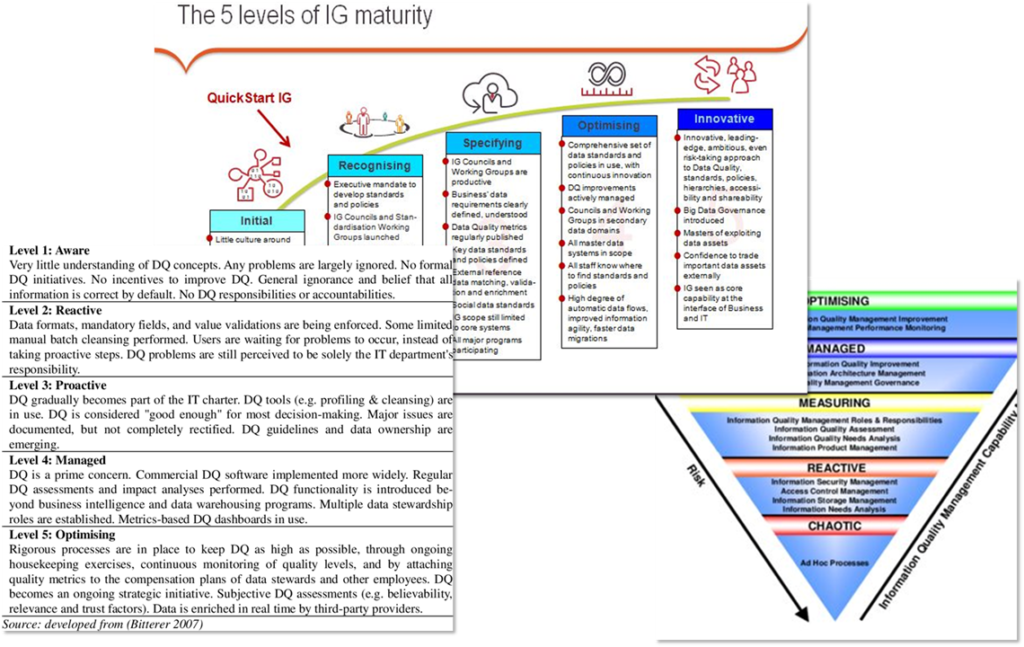
Demandez plus aux vendeurs des SI !
Bonne santé à vous et à vos systèmes aujourd’hui.