
Aujourd’hui, de nombreuses sociétés lancent (ou ont déjà lancé) un projet (parfois plusieurs projets) de qualité de données. Le problème récurrent de ce type de projets c’est qu’il faut bien commencer quelque part. Dès lors, comment choisir le premier sujet et comment ensuite prioriser les sujets ?
Voici les choix stratégiques souvent réalisés :
- s’occuper des « master data » (référentiel) avant de se lancer sur d’autres sujets,
- commencer par les données les plus couramment utilisées,
- poser la question aux métiers, la logique est la suivante : « le métier est le client interne d’un projet DQ, le projet doit donc traiter ses problématiques »,
- démarrer par le retour des utilisateurs sur la qualité des rapports BI,
- etc.
Nous avions donné la définition suivante de la DQ :
La qualité des données est un jugement concernant l’utilité des données, dans un contexte donné, souvent du point de vue d’un processus métier…
Source : https://ithealth.io/definir-la-data-quality-notre-proposition/
…veut-il dire qu’il faut commencer par les avis d’utilisateurs ?
L’autre chemin
En réalité, voici ce qui se passe :
- Les « master data » sont souvent correctement gérés ou bien la valeur dans les processus fonctionnels est limité (il est fréquent que vous pensiez l’inverse mais c’est un biais tout à fait normal). Dit autrement, ce n’est pas forcément dérangeant pour la bonne exécution des processus métier.
- Les données les plus utilisées (de nature transactionnelle, du référentiel de master data ou de la nomenclature) concentrent souvent l’attention (et c’est une bonne chose) mais ce n’est pas toujours ce que va apporter plus de valeur.
- L’avis de métier est souvent biaisé. D’ailleurs, il est probable qu’en demandant à 5 départements, vous allez obtenir 5 réponses différentes.
- La qualité des données dans les rapports est un indicateur important, mais c’est encore un avis non-mesurable et subjectif.
- etc.
A mon avis, il n’existe qu’une seule mesure clé (et heureusement pour nous, elle est claire pour les directeurs et/ou au service de finances) – le ROI (return on investment). Le problème avec ce genre de mesure « évidente », c’est que justement, ce n’est pas évident à calculer. Le diable se trouvant dans les détails… Je vous propose donc d’aller dans le détail.
Je vous propose de distinguer deux cas de figure assez fréquents :
- cas de problèmes récurrents dans les systèmes – ROI dit « perpétuel »,
- cas de changements d’architecture SI – ROI dit « ponctuel ».
Exemple. Une grande banque française pour se conformer au LCB-FT devait absolument lancer le projet de rapprochement des données clients. Malgré l’existence d’un outil le permettant, le projet n’ayant pas été initié, quelques mois plus tard, la société a payé 200x le prix de son produit sous forme d’amende pour cause du non-respect de la règlementation en vigueur. Il s’agit donc d’un risque perpétuel, il y a tout intérêt à traiter ce sujet.
Exemple. Je crois que le sujet du ROI dit « perpétuel » est assez clair, mais en ce qui concerne le ROI dit « ponctuel », de quoi parlons-nous ?
Beaucoup de sociétés lancent des projets de type « ERP central » ou « CRM central ». Pour ce type de projets, le ROI est scrupuleusement calculé. Il dépend souvent du temps nécessaire pour la mise en place du nouveau système. Si vous n’avez pas de données « de qualité » disponibles à la reprise, vous allongez le délai de lancement de nouveau système (et de fait, l’arrêt du legacy) – cela peut coûter très cher. Pour cela il y a un bon mot en anglais : « enabler »…
Lors d’un retour d’expérience de « Bank of America » sur la mise en place d’un outil MDM, ils ont amorti l’ensemble du projet grâce à l’économie des charges annuelles du système d’information précèdent (legacy).
Le ROI « perpétuel », en général, consiste à diminuer les différents types de risques :
- risques financiers,
- règlementation (ex. LCB-FT, GDPR),
- fraude,
- risques de dysfonctionnement des processus métiers (ex. la non-détection d’un produit en rupture de stock peut bloquer la chaîne de production),
- plus spécifiquement – risque de perte des clients,
- ou encore – risques liés au double paiement, double travail,
- etc.
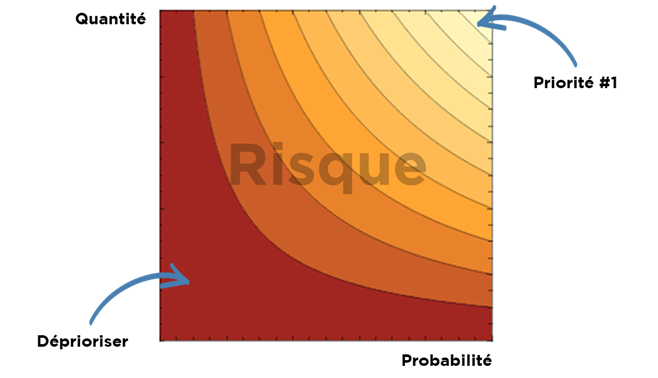
Chaque « risque » par définition est un produit de « la quantité de la perte » à la « probabilité de la perte » :

Dans ce cas, pour estimer l’importance de risque, vous devez estimer le coût moyen que vous pouvez perdre et les chances que cela se produisent réellement.
Pour notre cas d’usage, nous n’avons pas besoin de chiffres très précis – l’ordre de magnitude peut être suffisant pour prioriser notre travail…
Exemple. Supposons le cas d’une société de BTP. Chaque mois, nous recevons 30’000 factures, dont 1 sur 5’000 est une facture « en double » non-détectée (qui a parlé de « fraude » ?). Le coût de chaque facture en double est en moyenne 80’000 euros.
Dans ce cas, notre risque de paiement en double est de 480’000 euros par mois.
Si nous pouvons identifier 90% de factures en double en prenant deux consultants à temps plein au TJM 600 euros/jour pour qu’ils cherchent les doublons à la main, notre ROI est 480’000 * 0,9 – 600*2*20 = 408’000 euros par mois.
Dans ce cas, le sujets à haute priorité sont :
Contre exemple. Les solutions techniques de DQ sont souvent très concentrés sur un nombre de sujets très limité : doublons, standardisation, profiling…
Par conséquence, les sociétés qui achètent ces outils sont « formatées » dans une certaine approche (https://ithealth.io/pattern-darchitecture-toa-et-cela-vous-concerne/). Personnellement, j’ai une adresse pour le moins original, et souvent, je remarque que des sociétés standardisent mon adresse – ils enlèvent une partie importante et donc, je ne peux pas recevoir le courrier ou bien mes colis.
Un outil de Data Quality peut gêner vos processus fonctionnels et un formateur de chez Informatica ne le vous dira pas.
KPI
Une fois que nous avons pu définir le but de notre projet via le ROI (si vous êtes d’accord), il est clair que la vaste majorité de KPIs existants dans le domaine n’ont pas beaucoup de sens. Surtout si nous parlons d’agrégation de « qualité totale de données client », « niveau de qualité de données de la société », etc.
Il faut se dire que que prendre une moyenne pondérée entre le pourcentage de doublons et le nombre de téléphones mal saisis n’a pas beaucoup de sens si la pondération ne se fait pas par rapport au risque d’erreur en question.
En gros, votre « executive DQ dashboard » doit se mesurer en euros et en dollars, pas en pourcentages et nombres de lignes.
Conclusions
L’échange avec le contrôle interne / audit interne / finances peut vous aider identifier les sujets à ROI potentiellement élevé. En suivant cette logique, les réussites dans ces domaines seront mesurables et votre projet pourra prouver son utilité.
Cela n’annule pas les considérations « psychologiques » – aidez au fur et au mesure le métier à enlever les sources de dérangement afin de gagner leur confiance et leur soutien (même si pour vous ce sont des sujets non prioritaires).
Bonne santé à vous et à vos données !