
Commençons par le commencement… Au début des années 2000, META Group propose une « définition » du Big Data (futures solutions de data management).
– Pourquoi tu passes du temps à historiser toutes les données ? Nous avons seulement besoin de la version actualisée.
– Et bien, parce que, c’est un data lake !
En 2004, Google publie une recherche qui parle de Map-Reduce. Vu que Google grimpe en notoriété, cela capte rapidement l’attention :

Aspect méconnu de l’histoire, mais entre 1993 et 2001, la société Torrent Systems (Applied Parallel Technologies) a développé la technologie de calcul massivement parallèle qui réalise Map-Reduce mais sans hype.
Hadoop est relisé en 2006.
À la fin de l’année 2010, James Dixon (Pentaho) propose une nouvelle approche : faire les entrepôts c’est compliqué, en outre, le modèle dimensions-faits (Bus de Kimball) nécessite une préparation de données. Au lieu de s’embêter, nous pourrions tout simplement mettre toutes les données ensemble ! https://jamesdixon.wordpress.com/2010/10/14/pentaho-hadoop-and-data-lakes/

En 2011, Forbes publie une serie d’articles « Kill Your Data Warehouse », « Big Data Requires a Big, New Architecture ». Petit à petit, l’idée fait son chemin dans l’esprit des décideurs informatique.
En 2014-2015, James Dixon publie encore des articles sur la construction du Data Lake et, déjà, il doit combattre les définitions incomplètes voir erronées :
- https://jamesdixon.wordpress.com/2014/09/25/data-lakes-revisited/
- https://jamesdixon.wordpress.com/2015/01/22/union-of-the-state-a-data-lake-use-case/.
Version courte :
- Le Data Lake existe pour être la seule source de données (repository).
- Le Data Lake ne doit pas être modélisé ni traité (Not distilled // Marais de données).
- Sans traitement, les données ne sont pas plus utilisables pour répondre à certaines usages que aux autres (universel).
- Il s’agit simplement d’un stockage.
- Le Data Lake gère l’historique (en fait, ça viens aussi du fait que James Dixon propose d’utiliser Hadoop qui par défaut ne permet pas de réécrire les données dans n’importe quel ordre).
- Le Data Lake ne remplace pas la base de données (pas tout de suite).
- Les fonctions proposées du Data Lake : possibilité de remonter le temps (vu que nous sommes en train de stocker toutes les versions) ; probablement une utilité pour la compliance ( ≠ RGPD :)) ; sans parler de l’analyse prédictif (nous avons autant de données, autant s’en servir heh !).
Pour faire encore plus court : Data Lake par définition est la Landing Area avec historisation (pour aller plus loin, voir les explications de notre schéma étape par étape) :
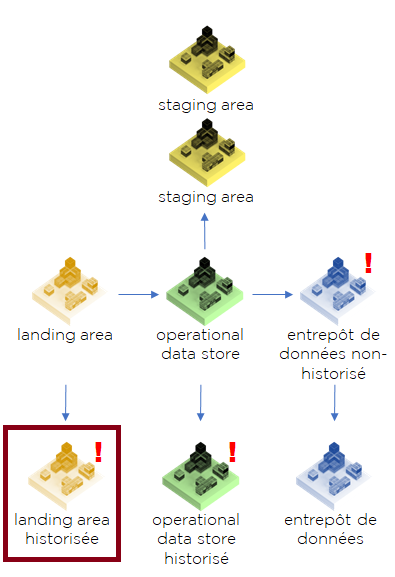
Voici nos objections de l’année 2020 :
- OK pour la source des données, dans ce cas, il suffit de l’appeler « Landing Area sur Hadoop ».
Imaginez un instant cette publication sur LinkedIn « besoin d’expert en construction de Landing Areas sur Hadoop ». - La flexibilité dans l’analyse des données. Elle n’existe pas, mais tout le monde la cherche. Voir reporting ad-hoc, self service, no code/low code.
- Il est difficile d’utiliser les données non-traitées et historisées pour plusieurs raisons :
- pour « distiller » les données non-historisées c’est déjà compliqué, pour les historisées – personne ne s’en chargera.
- au bout d’un certain temps, toute la landing area se change suite aux changements d’application, donc l’historique que nous avons enregistré 5 à 10 ans auparavant ne sera pas d’une grande utilité car probablement personne ne se rappellera de la définition exacte des champs.
- l’analyse « prédictive » nécessite des données sous le bon format et de bonne qualité ainsi que de bons algorithmes. C’est infiniment plus important plus que le simple volume brut.
- Hadoop aura donc beaucoup de mal à remplacer les bases analytiques, tout comme le poids lourd aura bien du mal à doubler une voiture de Formule 1 pour les mêmes raisons.
Question pertinente, pourquoi les personnes qui ont implémenté des Data Lakes ne sont pas forcément satisfaites ? Il y a plusieurs raisons, de mon humble avis :
- Hadoop n’est tout simplement pas conçu pour la charge analytique. Il n’est pas un « low latency storage » à cause de l’absence d’indexes, de compression avancée, etc.
- Hadoop peut certes être utile pour la préparation de données avant l’entrepôt, mais en ce sens, il est bien plus facile d’organiser une Landing Area dans une base de données « classique ».
- Peu de sociétés ont réellement besoin de remonter le temps, du moins, pour l’instant.
- L’intérêt de Data Lake pour la « Data Science ». Le vrai enjeu d’aujourd’hui se situe plutôt dans la recherche de cas d’usages pertinents et/ou novateurs. De ce fait, le ROI n’est pas toujours évident.
On fera remarquer qu’on peut parfaitement exécuter des algorithmes de machine learning (ML) sur l’entrepôt de données. - Les ardeurs excessives du tout analyse seront toujours freinées par le ROI (vous vous souvenez peut être de la hype autour du sentiment analysis sur Twitter, le scrapping de Facebook, l’open data ?).
Autrement dit, c’est un outil spécialisé pour des besoins spécifiques. Il trouvera confortablement sa place chez certains géants comme eBay, Amazon, etc. Mais pas dans chaque société !
Tout ce qu’on a écrit concerne évidemment le Data Lake (le concept), pas Hadoop (la technologie). Sic!
Emportez le corps.
Bonne santé à vous et à vos systèmes.
Pingback: Data Vault – Ordre d'informaticiens
Pingback: La consolidation de données : extraction – Ordre d'informaticiens
Pingback: Reporting Factory – Ordre d'informaticiens