
Dans cet article, nous allons disséquer ensemble la vision globale des flux qui alimentent l’entrepôt de données. Nous tenterons de vous donner le vaccin contre les maux suivants : définitions-abusisme, best-practisme, tout-le-monde-le-faiisme.
Petit rappel utile : l’entrepôt de données est la source de données pour le reporting BI. Différentes approches existent pour construire cette source, mais très certainement vous souhaitez que :
- Les données placées dans l’entrepôt soient le plus simples possible à utiliser pour faciliter la construction de vos rapports (data viz, etc). (Orienté sujet)
- Les données soient assez « propres » pour obtenir des résultats le plus corrects possible. (Intégré)
- Les données en provenance de plusieurs SI puissent être croisées si nécessaire. (Intégré)
- Les données soient stockées dans le temps et ainsi, pouvoir accéder à l’historique si besoin. (Historisé, non-volatil)
On commence toujours notre projet avec les données « moins propres », dispersées dans les différents modèles et non-historisées. Quel est le chemin idéal vers la forme souhaitée de nos données ? (Attention : si vous n’effectuez pas ou accomplissez partiellement certaines étapes, il y aura des effets secondaires)

- Extraire les données. Vous disposez pour cela de 2 options majeures : extraire via les batchs (avec un ETL/SQL/script) ou extraire en temps réel (Change Data Capture, souscription aux événements si supporté par le SI, etc)
- Convertir les données en format « universel » (Canonical Data Model, parfois, également connu sous le nom « Pivot »). Pour y arriver, vous avez besoin d’une compréhension claire et limpide de vos données (d’où la mode aux nombreux dictionnaires sur la gouvernance, etc).
- Dans certains cas, appliquer la « standardisation » des données pour uniformiser le contenu. Puis, remplacer les clés étrangères par les identifiants du modèle final.
- Valider les données.
- Rapprocher, i.e. parmi toutes les données récupérées, trouver les répétitions/doublons, c’est à dire les données qui décrivent le même objet métier. Discipline nommée rapprochement de données, matching ou encore record linkage.
- Parmi toutes les répétitions trouvées, choisir la plus adaptée : étape appelée le dédoublonnage.
- Sauvegarder les données en forme normalisée ou dé-normalisée suivant son besoin.
- Historiser le résultat.
Note pour nos lecteurs experts : vous connaissez probablement un cheminement alternatif des processus, surtout si vous êtes apparentés à l’école Kimbalienne. Dans ce cas, vous ne distinguez pas autant le rapprochement de données, le dédoublonnage et la sauvegarde grâce à l’utilisation de clés fonctionnelles. Nous en parlerons dans un prochain article, mais il faut savoir en quoi et comment cela peut poser des problèmes. De toutes façons, pour notre vision globale de processus, nous pouvons préciser qu’une variation dans l’approche ne change pas automatiquement la règle.
Si nous décrivons le flux de point de vue des données, voici ce que se passe (les étapes les plus importantes) :

Si nous prenons cet image, nous pouvons donner noms aux différentes parties (j’ai inséré un point d’exclamation pour les étapes où nous n’avons pas de convention pour la dénomination dans la théorie B.I.) :
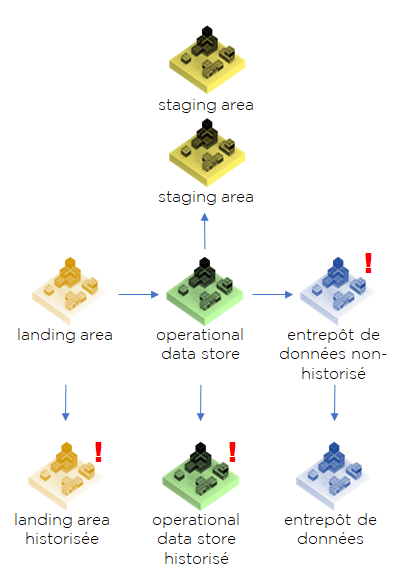
Il est fort probable que certains noms vous soient familiers, notamment quand on évoque le stockage dans une base de données. Techniquement, Landing Area, Staging Area, ODS, etc peuvent exister en forme de fichiers ou d’empreintes mémoires sans être obligatoirement stockés dans une base de données.
Donnons les définitions ?
- Landing Area – espace de réception des données « brutes », non-transformées. Souvent L.A. est perçue comme une partie spécifique de la Staging Area. Nous pouvons l’historiser. Il faut noter que les théories sur l’entrepôt de données la considérait souvent comme une étape inutile.
- Staging Area – espace de données intermédiaires, temporaires ou dérivées. Vous pouvez dire que S.A. contiendra les transcodifications, rejets et autres éléments de suivi. Certains auteurs vont jusqu’à dire que S.A. n’est pas nécessaire d’être stocké dans la base de données. Nôtre avis est le suivant : il existe des éléments obligatoires pour le stockage et d’autres optionnels. Nous y reviendrons en abordant les méthodes incrémentales.
- Operational Data Store – on utilise la définition de base (aka Corporate Information Factory, très bien décrite et critiquée ici : https://www.kimballgroup.com/2004/03/differences-of-opinion/, même si c’est l’invention de B. Inmon). C’est un stockage de données qui fait suite à l’intégration de tous les systèmes comme si nous avions un seul système transactionnel. Nous devons y trouver l’objet « Client » dans une seule structure et sans doublons. La même règle s’applique aux autres objets, évidemment. ODS peut être historisé, mais c’est inutile dans la plupart des cas.
- Entrepôt de données, Data Warehouse, DWH – une structure dénormalisée, souvent en forme des « dimensions » et des « faits », ce que Kimball appelle « Bus ». Techniquement, par définition, le DWH doit être historisé, mais dans un grand nombre de projets la vision historisée est secondaire, donc nous voyons les cas des structures dénormalisées en dimensions-faits, mais non-historisées. Une autre notion liée au DWH, c’est le Data Mart.
- Data Mart, magasin de données est une partie de l’entrepôt, rien de plus. Si vous faites un zoom sur une table de faits avec ces dimensions, vous pouvez parler d’un Data Mart au lieu de parler d’ensemble de l’entrepôt.
Malheureusement, la définition des différentes étapes de stockage sont souvent données AVANT la description des flux de données auquel elles doivent servir – et cela crée forcément des confusions (même dans les têtes de certains professeurs de certaines écoles !). On espère que vous voyez désormais d’où proviennent ces étapes.
À partir de notre schéma, vous pouvez définir plusieurs versions d’architecture de votre DWH. La vraie différence entre deux « pures » architectures est dans l’existence de la couche ODS (du vrai aka CIF). Le fait qu’elle existe permet à Inmon de proposer des Data Marts plus taillés aux besoins d’utilisateurs. Par contre, l’ODS a un coût supplémentaire non négligeable. On précisera que Kimball n’est pas « pour » le stockage de landing/staging area physiquement dans la base de données, mais il n’est pas, visiblement, complètement « contre ».
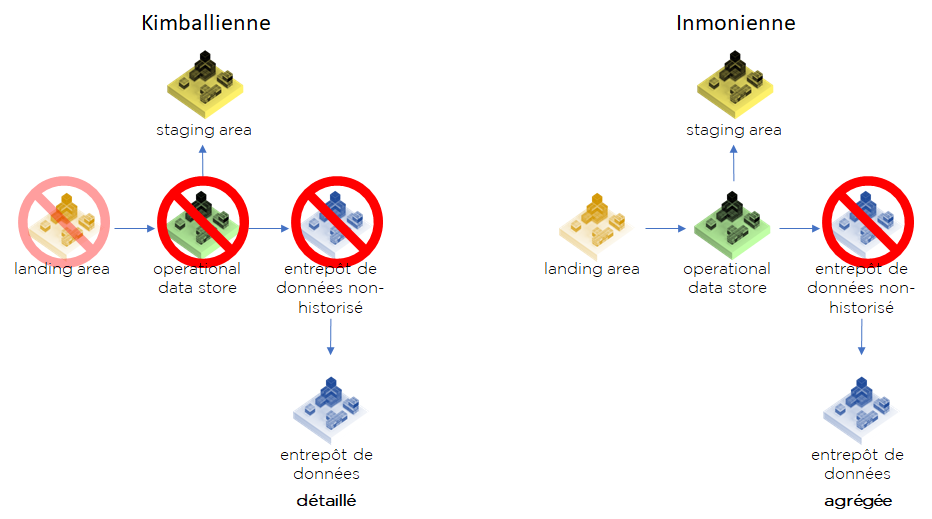
Attention ! Nous ne pensons pas toujours nécessaire la mise en place de l’ensemble de couches de stockage pour l’ensemble de tables, il est préférable de décider pour chaque structure de données si vous voulez la garder dans la SA, dans l’ODS ou au niveau du DWH. Par exemple, pour une gestion optimisée des référentiels, vous pouvez le matérialiser sur l’ensemble des étapes de traitement, mais stocker les données transactionnelles uniquement au niveau de DWH afin de minimiser l’espace utilisé.
Où sont les autres parties ?
Landing Area historisée par définition est un data lake. Si vous lisez le père de Data Lake, James Dixon, c’est plus ou moins la définition qu’il a donné : https://jamesdixon.wordpress.com/2015/01/22/union-of-the-state-a-data-lake-use-case/
ODS historisé existe-t-il ? Visiblement, pas vraiment ou bien pas comme on pourrait l’imaginer, même s’il existe quelques initiatives, Data Vault parmi les exemples les plus connus.
Pour résumer, nous avons commencé par la définition, puis développé les différentes étapes du processus pour enfin jeter les bases d’un modèle afin de concevoir les différentes architectures de l’entrepôt. Vu que ce modèle d’analyse a été développé avant la publication de la définition de Data Lake, on peut dire qu’elle a eu une force prédictive.
Bonne santé à vous et à vos SI.
Pingback: Data Lake : retour vers la définition – Ordre d'informaticiens
Pingback: Projet Data hub : mythe ou réalité ? – Ordre d'informaticiens
Pingback: MDM + BI = 💀/🧡 – Ordre d'informaticiens
Pingback: MDM : ce que IBM, Semarchy, Informatica et EBX vous cachent – Ordre d'informaticiens
Pingback: Choc : redéfinition de l’entrepôt de données, de data hub et de data lake – Ordre d'informaticiens