
Hello!
Today it’s a braindump on a very specific subject – stability if the data flows.
You know what’s the most important thing in the mechanical engineering? It’s rigidity. It means that if you use a lathe, you need it to be as rigid as possible, otherwise you’ll obtain a piece with incorrect dimensions, horrible surface, etc. « Rigid » here means that your tool does not bend under pressure.
The same idea, IMHO, applies to the data flows. The flows should be able to grab on the state of the synchronized systems and ensure the state of the data. Seems evident, doesn’t it?
Let’s compare three implementations of the very same extremely basic data flow – synchronization of a « table » between two systems:
- “Modern” stack: the data is pushed into some kind of middleware in “real time”, which pushes the data into the final system:

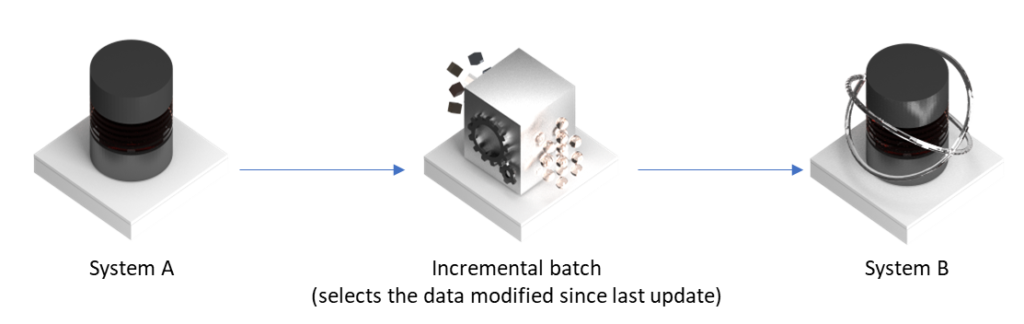
- “Classic” stack: the system A exports the modified data into a database/file, which is incrementally imported to the final system (i.e. we read the recently modified objects only). The most important thing here – incremental nature of the flow. The process may be nearly as fast as the first solution, but way simpler…
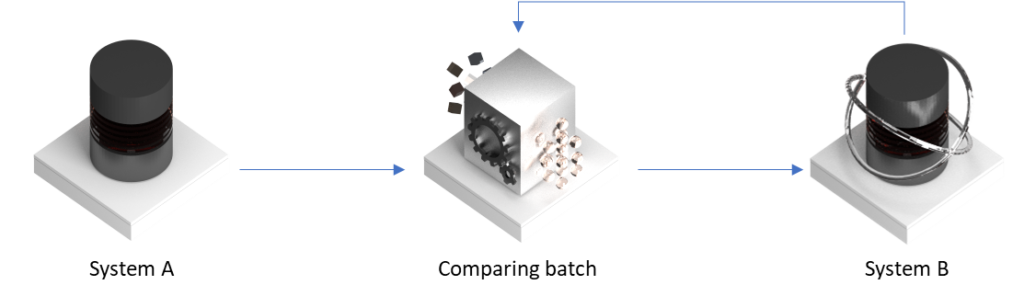
- “Stupid” solution (aka “comparing batch”): the system A exports its whole contents into a database, the data is transformed in “full” and compared to the contents of the final system, the detected difference is loaded. The whole process in much slower – one needs to export the whole data set, transform it, compare both versions and load the delta.
From the point of view of an « average » IT architect, the first solution is the best one – it is modern, it is fast, one can do some Kafka/MQ… but there is a catch (Catch-22).
Case example. Let’s see, what happens if a bunch of data is lost (for whatever reasons – system B has its database restored from a backup, the data gets incorrectly changed in B, there’s a bug in our data flow, there is a slight change in the filter applied by any component):
- First case – “real-time-ish”: the data is lost, it will never appear on the radar of our middleware if it is not re-published (thus one has to go and find it, force the re-publishing if it is possible, cope with a spike of the workload). The problem is often more complicated than the data flow itself. I’m not even talking about the complexity of the incremental data flows here.
- Second case – “incremental batch”: usually one doesn’t need to republish, but still has to find the differences and produce a specific workflow to re-load them.
- Third case – “comparing batch”: just re-run the batch – it will find the differnces itself. The only problem one has to cope with – a potential spike in the workload for the system B.
You see? Somehow the third case automagically copes with this problem. It will just work. Probably, it will adjust the data before anyone notices the problem. This is our “stability” (or « rigidity ») – in case of any problems, the state of the data will be restored without any additional effort from the humanware.
Let’s see another case. Imagine you have to load the data from an in-house CRM system. The data is exposed in form of views in a database. You’re free to implement an incremental data flow because every view contains the “last modification date”. Let’s suppose you do implement the data flow in an incremental manner (just ingesting every hour or so all new and modified rows). Oh, after years of the flow running, there are lots of rows lost (for unknown reasons), but what is worse – you learn that the views use “joins”:
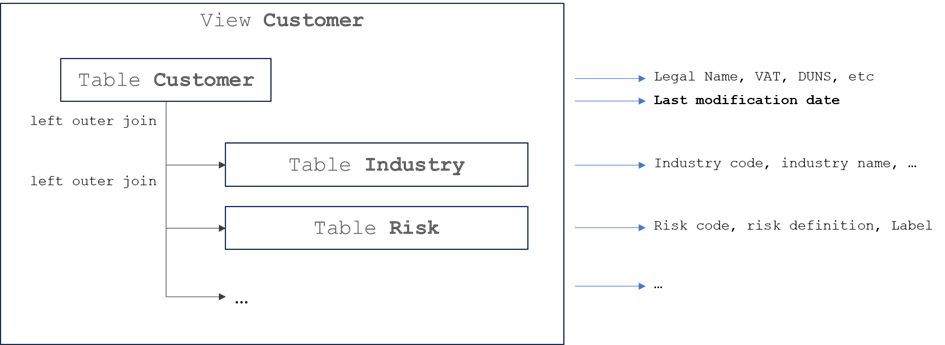
Quite clearly, the last modification date is populated from the “base” table, so the changes in the “secondary” tables do not affect the “Last modification date”… so if you use it to detect the changes and populate the system B, any changes made in the secondary tables (Industry, Risk, etc) will not trigger the data flow and the modifications will be lost. Thus, if the system B consumes the denormalized industry name, it will contain the value which was used at the moment of the last modification of the customer, not the current industry name.
If the data flow was “stable” (i.e. “self-correcting”), it would have detected such cases and produced the correct result each and every time.
It’s a real-world case, the error was made by the developers with quite a lot of experience. Do you think you yourself will not make such mistakes?
I’ve just wanted you to think about it the next time you specify a new data flow.
Just a side note for the users of Spark Streaming: the creators of the Spark engine seem to push you to the incorrect solution. If you use Spark Streaming with joins – that will give you an « instable » data flow. Just bear this in mind.
Good health to you and to your data flows.