
…and now for something completely different.
Monty Python
Aujourd’hui, je vous propose d’analyser, en pratique, un sujet à la mode : la Data Virtualization. Vous en avez probablement entendu parler, en effet, c’est une approche où vous utilisez un outil magique qui peut reprendre toutes vos sources de données, le tout sans ETL, et cela vous donne la vision unifiée des données (ou au moins le moyen pour les requêter via SQL). L’alternative c’est de copier toutes vos données dans une Staging Area, mais visiblement cela pose quelques problèmes, notamment la « fraîcheur » des données.
Pour donner un peu de contexte historique, Data Virtualization a dans son cœur la même technologie que Enterprise Information Integration (EII) proposée en 1998. Pour être franc, les outils spécialisés de Data Virtualization proposent un peu plus que simplement « virtualization », i.e. la capacité de « faire le join entre les tables de deux bases de données différentes », notamment les vendeurs de « Data Virtualization dream » proposent le data lineage, le suivi des requêtes, etc. Nous allons nous concentrer sur le cœur du sujet.
Voici comment Data Virtualization est vendue :
- accès aux données en temps réel sans réplication (aka sans Staging Area),
- haute performance,
- sources hétérogènes,
- publication des données sous format adéquat et prêtes à être consommées,
- etc.
Je vais développer uniquement les deux premiers sujets car, sans performance, votre solution ne sera pas exploitable, n’est ce pas ?
Use case #1 : un réseau de distribution utilisant la Data Virtualization pour réaliser l’intégration
Un jour quand DV s’appelait EII et on cherchait une solution de temps réel pour intégrer deux SI après un upgrade de deux systèmes, nous avons remarqué nombreux problèmes de passage d’information entre l’ERP et le système financière (FI). Il fallait trouver une solution vite et respecter les délais de synchronisation.
Solution : Elle était sous nos yeux : nos bases de données permettait la « fédération des données ». Un système expose la view, l’autre l’importe et pour tous les scripts, elle ressemble à une view native (SQL Server : Linked Server, DB2 : Data Federation, Oracle : Heterogeneous Connectivity).
Résultats : 1 port ouvert, 0 technologies supplémentaires, synchronisation en temps réel, 0 nouveaux flux physiques. Nous avons du, en revanche, ajuster le nombre de requêtes vers cette nouvelle view car elle était quand même moins rapide que « native » (simple optimisation des scripts).
Morale : pour réaliser un projet de Data Virtualization, jetez un œil à ce que vous avez en stock, souvent, vous avez déjà ce qu’il faut !
Use case #2 : un entrepôt de données virtualisé
J’ai été invité, en tant qu’un expert, au démarrage et à la fin de ce projet initié par une organisation issue de l’Union Européenne. Les architectes du projet ont commencé la refonte des SI. La question suivante se posait : « faire une ville ou un village » du point de vue d’architecture.
Mes propositions :
- au début du projet nous avons pu choisir une base analytique pour tenir la charge,
- la data virtualization ne permettait pas d’accomplir la gestion de la qualité des données comme il le fallait,
- avant la refonte, il était possible de construire un seul système en réduisant la complexité de l’ensemble.
Solution choisie : Les architectes ont finalement choisi une architecture distribuée avec l’idée que l’entrepôt de données c’est le passé, tout pouvant être intégré via EAI ou Data Virtualization (EII).
Résultats : L’entrepôt de données virtualisé fonctionnait mal voir pas du tout, certaines requêtes prenaient plusieurs heures, les architectes du projet pensaient que la cause venait de la configuration des outils, ou bien des prestataires, etc (si la cause est interne, vraisemblablement, quelqu’un devait perdre son poste).
Morale : Votre attrait pour une technologie, les résultats du PoC ne peuvent pas remplacer le bon sens.
Analyse & Conclusion
Effectivement, aujourd’hui vous pouvez mettre en place la Data Virtualization et le nombre de possibilités est incroyable :
- Joueurs « du marché »
- Red Hat JBoss Data Virtualization (père de data virtualization)
- TIBCO (Cisco)
- Denodo
- IBM (plusieurs offres différents)
- Informatica Data Virtualization
- Oracle (plusieurs offres différents)
- etc.
- Autres possibilités :
- Microsoft SQL Server
- Spark SQL
- etc.
Toutes les technologies de ce type peuvent être représentées par ce schéma et, surprise, ici il n’y a rien d’incroyablement nouveau depuis 1998 :
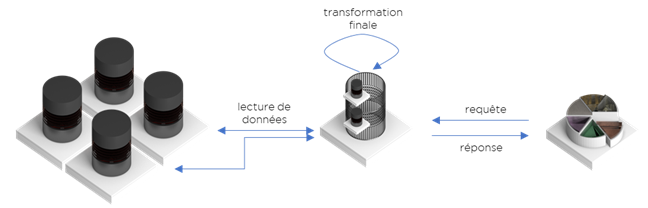
Il reste deux possibilités techniques :
- DV sans cache – la performance de la solution va dépendre sur la capacité des SI existants à exécuter les requêtes pour sortir les données pour l’analyse,
- DV avec cache – nous n’avons pas de données fraîches par définition – la solution revient à l’ELT fait autrement.
Assez certainement dans le monde des bases de données, le principe « No Free Lunch » fonctionne aussi : si vous ajoutez une fonctionnalité, vous perdez quelque chose en retour.
Dans le cas d’une Data Virtualization, nous perdons en proximité des données (notre moteur est séparé de stockage), en connaissance des statistique des données (partiellement), en gestion de mode du stockage des données (https://ithealth.io/le-monde-inegal-des-bases-de-donnees/), donc automagiquement nous perdons en performance. Si nous permettons le « cache » des données, nous perdons notre « temps réel » sans avoir la possibilité de mettre en place les flux incrémentaux.
Conclusion : Data Virtualization est une bonne option. Parfois. Mais ce n’est pas un « silver bullet ». À utiliser avec modération, donc.
Bonne santé à vous et à vos systèmes.
Post Scriptum. Nous n’avons pas parlé de cold/hot storage et de l’intégration entre les deux. Même si la technologie est la même, très peu de d’architectes considèrent ce cas comme une Data Virtualization.