
Avant de commencer, je souhaite vous présenter les résultats que j’ai obtenu en posant la question concernant l’organisation de la consolidation de données :

Il y avait peu de réponses, mais le trend général me montre que cet article risque de provoquer un choc. Alors un conseil, éloignez des écrans toute personne sensible.
The first principle is that you must not fool yourself and you are the easiest person to fool.
Richard P. Feynman
Nous avons besoin de définitions pour établir un langage commun, pour pouvoir échanger sans faire référence à notre expérience personnel et les subtilités de notre perception de la réalité… mais parfois la vision s’évolue et nous devons ajuster l’usage de termes et notre vision de la réalité.
Par contre, il ne faut pas mélanger la mauvaise compréhension de définitions et l’évolution de définitions. Assez souvent pour comprendre qu’on se trompe il suffit d’aller chercher une définition dans le dictionnaire et comparer à vôtre compréhension. Si vous sentez un choque, votre compréhension était juste mauvaise.
Par exemple, voici une définition de Business Intelligence :
Business intelligence (BI) comprises the strategies and technologies used by enterprises for the data analysis of business information. BI technologies provide historical, current, and predictive views of business operations. Common functions of business intelligence technologies include reporting, online analytical processing, analytics, dashboard development, data mining, process mining, complex event processing, business performance management, benchmarking, text mining, predictive analytics, and prescriptive analytics.
https://en.wikipedia.org/wiki/Business_intelligence
J’ai mis en gras les sujets qui choquent beaucoup de personnes autour de moi qui disent « mais c’est la data science, pas BI » ou « mais oui, mais non, c’est l’analyse opérationnel, pas décisionnel »…
Le problème est qu’il y a encore 10-15 ans dans les livres blanches concernant le BI il y avant des notions de machine learning, de l’analyse opérationnel, etc. Je vois très bien, pourquoi les consultants veulent avoir une spécialisation en data science aujourd’hui, mais c’est une différence au niveau de la complexité et pas au niveau technique (je n’ai pas compris, qui a dit « positionnement commercial » ?).
Par contre, j’ai voulu parler d’évolution de notions… En 2020 Gartner a publié un document « Data Hubs, Data Lakes and Data Warehouses: How They Are Different and Why They Are Better Together » et voici un morceau qui m’a particulièrement touché :
It is equally important to recognize that these [Data Hub, Data Lake & Data Warehouse] architectural patterns can bring more value to the enterprise when used in combination. Data and analytics leaders should not simply choose between either a data warehouse, a data lake or a data hub. Instead, they should consider combinations of these structures to support the full range of current and anticipated requirements. The data warehouse, data lake and data hub can be combined to work together in an effective architecture.
Gartner, reprint ID G00465401, 13/02/2020
C’est un sujet complexe car historiquement les équipes qui s’occupent d’intégration d’information (d’où le paterne Data Hub) et les équipes DWH sont souvent séparés… mais cette notion me perturbait avec un sentiment de « déjà vu » – et je suis revenu vers le bible de DWH :

Dans son livre (de l’année 2002, sic!), W. Inmon parle de « nouveau patern » d’utilisation de DWH pour l’intégration de données :
There is, then, an emerging pattern to the indirect use of data warehouse data <…> warehouse is analyzed periodically by a program <…> creates a file in the online environment that contains succint information <…> used quickly and efficiently, fitting in with the style of the other processing in the operational environment…
W.H. Inmon, Building th Data Warehoure, chapitre 3
…et voici le schéma qu’il propose :
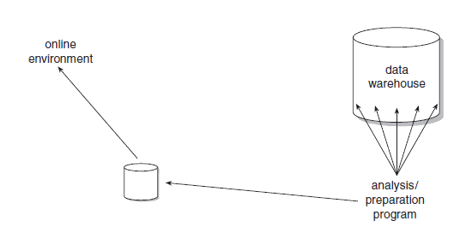
Autrement dit, ici le DWH est utilisé pour l’intégration d’information (i.e. le retour de données consolidées vers OLTP)… même si au moment l’approche (commercialement) dominant était l’EAI, i.e. l’intégration via Message Broker, MQ, etc.
Pourquoi cette vision est « légale » ? En effet, un entrepôt de données doit accomplir la consolidation de données, donc de ce point de vu il exécute les mêmes processus que certains types de Data Hub et même certaines styles de MDM :
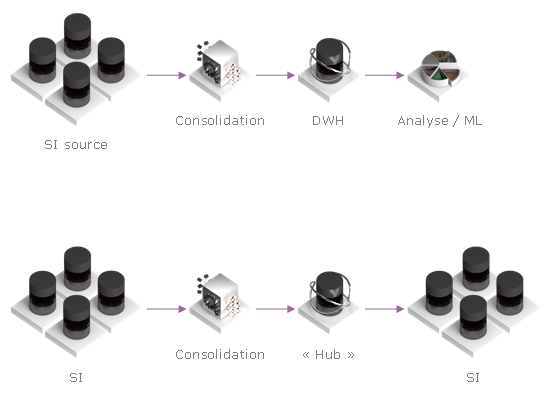
Si c’est le cas, nous n’avons qu’à construire la chaine de la consolidation qu’une seule fois. Nous pouvons l’appeler « Data Hub de Consolidation » ou « Operational Data Store » ou « Data Warehouse » – les paternes se ressemblent autant que Gartner (18 ans après Inmon) conseille de les réunir.
Quid Data Lake ?
Par définition, Data Lake est une source unique de données brutes (aka Landing Area) et c’est important. Si vous n’êtes pas d’accord avec cette définition – vous pouvez lire notre article sur ce sujet : https://ithealth.io/data-lake-retour-vers-la-definition/. Si vous en avez besoin de Data Lake (et ce n’est pas le cas pour 99% d’organisations), il peut bien servir en tant qu’une entrée de votre consolidation :
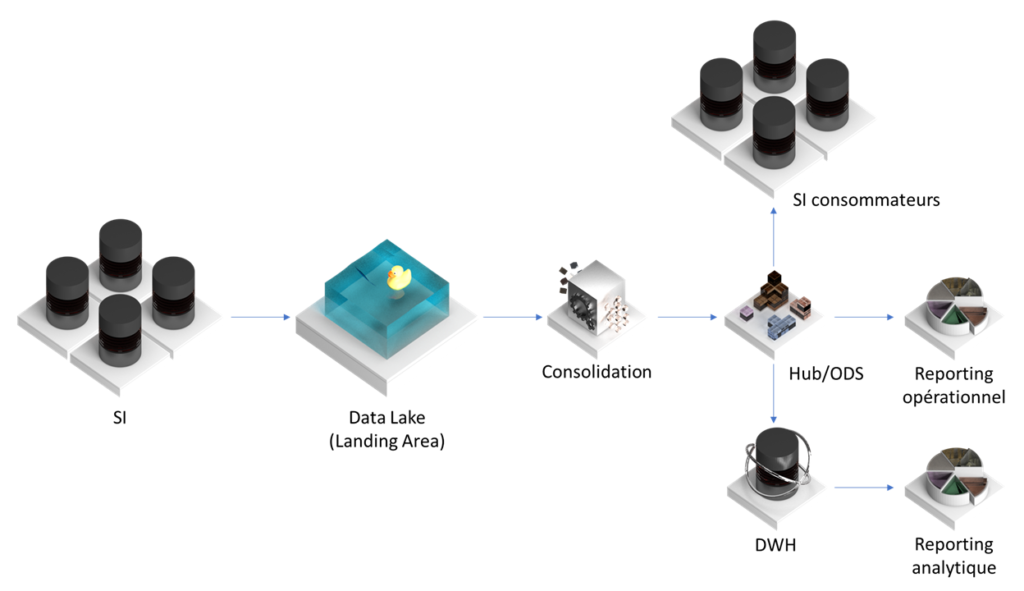
Note : ce n’est pas un schéma technique – le nombre de bases de données et d’outils participants (RDM/DQM/ML/etc) peut être quelconque.
Conclusion
Enfin nous pouvons parler pas seulement de consolidation de données, mais aussi de consolidation d’efforts de consolidation de données. J’espère que les ressources libérés seront utilisés pour créer les solutions plus intelligentes et plus robustes.
Bonne santé à vous et à vos systèmes.