
Le rapprochement de données est le sujet central du Master Data Management (MDM) et de la BI, en outre, il joue un rôle clé pour les départements RH, compliance (ex. RGPD) et bien d’autres domaines.
L’idée derrière est de pouvoir identifier que plusieurs morceaux d’information décrivent la même chose (malgré les différences de format, les éventuelles erreurs, le changements, etc). Pour cela, il faut trouver toutes les occurrences existantes d’information personnelle, les doublons des clients, identifier les produits, etc. Ce domaine est fortement lié à la recherche d’information, évidemment.
Le rapprochement de données (connu également en tant que « Record Linkage », « Duplicate Detection » ou parfois « Matching », « Immatriculation » ou encore « Dédoublonnage », même si le dernier terme est ambigu) a été inventé et réinventé plusieurs fois. La personne qui a fait la première grande publication sur le sujet est H.L. Dunn dans les années 1940.
Le nom « record » n’est pas lié ici aux bases de données, évidemment. Il parle bien de « patient record », i.e. l’ensemble d’informations nécessaires pour identifier une personne, en l’occurrence un patient.

En revanche, la vision de H.L. Dunn n’a pas été matérialisée sous forme d’algorithme avant la publication de H. Newcombe en 1959. Celui-ci propose une méthode « statistique » de rapprochement d’information qui peut fonctionner également dans d’autres cas que « patient » et « personne ».
Fellegi et Sunter ont « prouvé » que cette approche est optimale sous certaines conditions en 1969. Aujourd’hui, nous savons faire encore mieux … mais ce n’est pas le sujet de cet article. Actuellement, l’approche de Newcombe-Fellegi-Sunter est perçue comme l’une des plus avancées parmi les approches utilisées en pratique.

Note pour les experts BI : dans BI/DWH, le sujet de rapprochement de données a été « pollué » par l’idée des clés fonctionnelles (i.e. les codes qui sont « certainement corrects » et « certainement uniques »). L’approche basée sur ces clés est super-simple à implémenter et fonctionne assez bien dans certains cas (ex. code de contrat), mais en général nous devons aussi prendre en compte les éventuels changements de données naturels et/ou à cause d’erreurs de saisie. À ce titre, même les systèmes de détection de doublons de factures permettent des erreurs dans le code/date/montant. Pourquoi donc rapprocher avec une clé les informations concernant les personnes/produits/sociétés ?
Revenons vers le modèle de Newcombe et al. En quoi consiste-t-il ?
Si vous avez une paire d’objets (records), vous pouvez assigner à cette paire un score de proximité. Ce score peut être calculé à la base de mesures de proximité de différents champs … Par la suite, ce score sera comparé aux seuils, mais nous y reviendrons plus tard. Continuons :
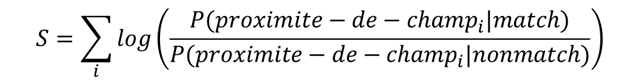
Ici, nous disons que le score est juste une somme d’expressions qui se base sur les mesures de proximité des champs. La preuve de cette formule est très basique via la méthode de Naïve Bayes. Dans le monde des « data scientists », nous pouvons reformuler ce modèle – le score est une somme de « certaines fonctions croissantes » à la base de mesures :
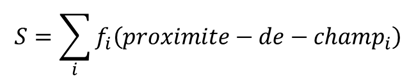
Remarque : cette approche ne spécifie pas, comment obtenir cette proximité des champs (string distance, string metric). Actuellement, les systèmes utilisent les algorithmes de Damerau-Levenshtein, Soft TF-IDF, bigram, Hamming et les autres.
Exemple basique d’application de notre formule : si nous avons 2 objets JANE DUPONT et JAN DUPONT, le processus de calcul du score peut être représente par ce schéma (d’ailleurs, le résultat est mesuré en Bells) :
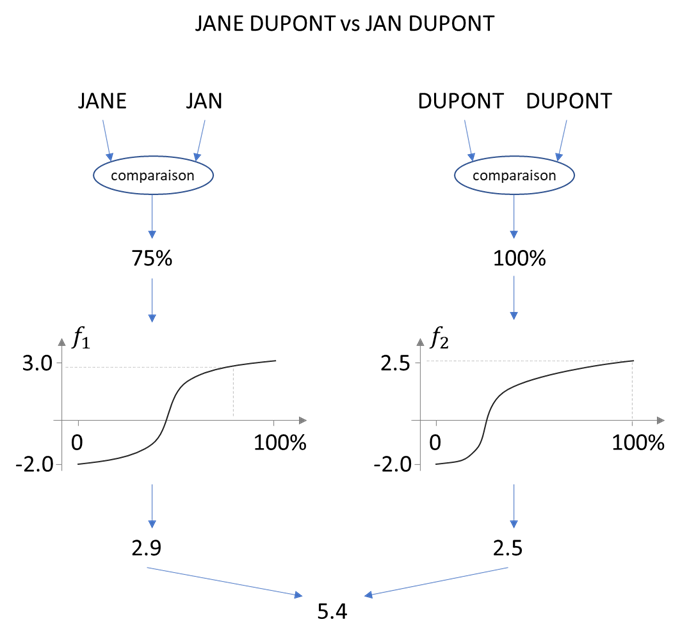
Pour qu’on puisse comparer les données, on les « standardise ». En effet, c’est encore le cas aujourd’hui, nos fonctions de ne sont pas aussi intelligentes que les humains et ainsi ne comprennent pas que la même lettre peut exister en majuscule/minuscule, avec/sans accent, peut représenter la même chose. La même réflexion fonctionne avec les formats des dates, les formats d’adresses, etc.

Note pour les malades de dataqualityisme : la standardisation a été inventée pour faire fonctionner le rapprochement. L’histoire racontée par les éditeurs que « l’adresse doit être en bon format, sinon cela impacte l’image de votre marque » c’est un simple moyen de faire du business. On en reparlera prochainement, c’est promis !
L’approche de Newcombe a été vue comme une « best practice » avant que deux événements ne se produisent :
- L’arrivée des outils de « Data Quality » pour lesquels le rapprochement est juste une étape de traitement d’information parmi d’autres et le paramétrage des « fonctions » c’est compliqué. On les soupçonne de prendre le chemin (raccourci ?) de la simplification !
- Le constat par les chercheurs que quelque chose ne fonctionne pas si bien dans le modèle de Newcombe et al.
On pencherait plutôt vers la complexification !
Les premiers ont souvent simplifié le modèle jusqu’à une somme pondérée (voir Talend, Semarchy, TIBCO/Orchestra, Informatica, etc), mais heureusement, certains font de la résistance …
Le deuxième groupe (de chercheurs) a commencé à complexifier les modèles et est parvenu aux « mixture models », réseaux de neurones, etc.
Pour que nos explications soient plus claires, voici un petit exemple. Nous allons commencer par une préparation de données de deux systèmes que nous voulons rapprocher. Vous pouvez remarquer qu’ils n’utilisent ni les mêmes noms, ni le même nombre de champs ni le même format de dates…
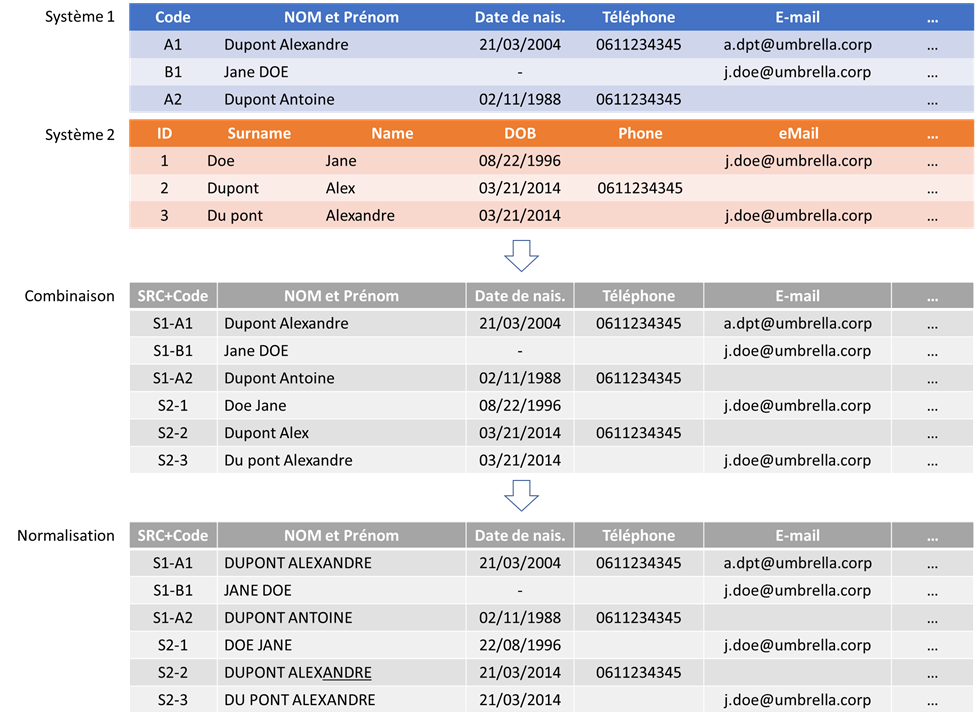
- Durant la phase de combinaison, nous avons réuni les deux structures en un seul et unique modèle de données (nous avons repris le modèle de Système 1 et regardez bien – nous avons créé des identifiants uniques via la combinaison de numéro de système et de clé primaire dans ce système).
- Durant la phase de normalisation, nous avons ajusté le format des dates, mis en majuscule les noms/prénoms et remplacé ALEX par ALEXANDRE (via le dictionnaire).
Maintenant, il nous faut choisir toutes les paires de données qui sont des doublons potentiels du même objet fonctionnel (ici – personne). Ensuite, accomplir la comparaison champ-par-champ (on fera deux paires, le processus est très répétitif, pour les données manquantes, nous mettons le score de 0) :
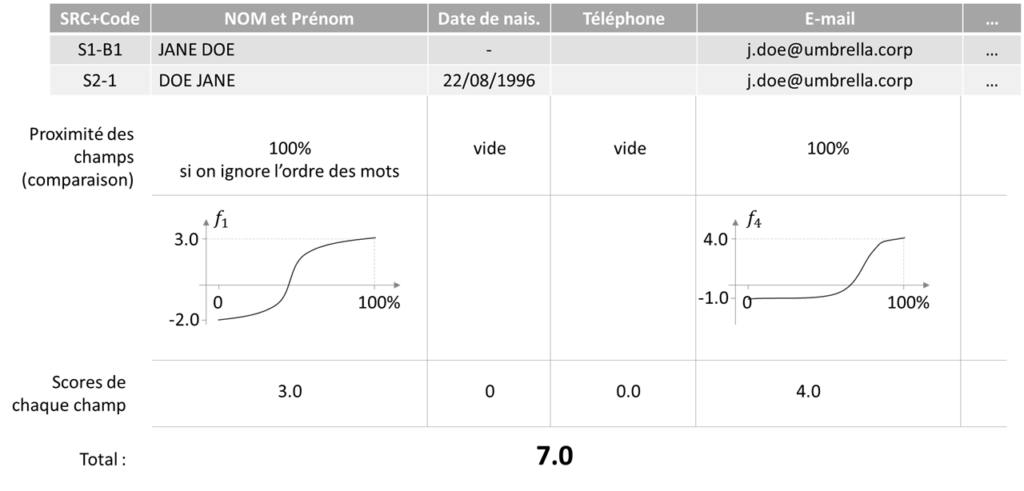
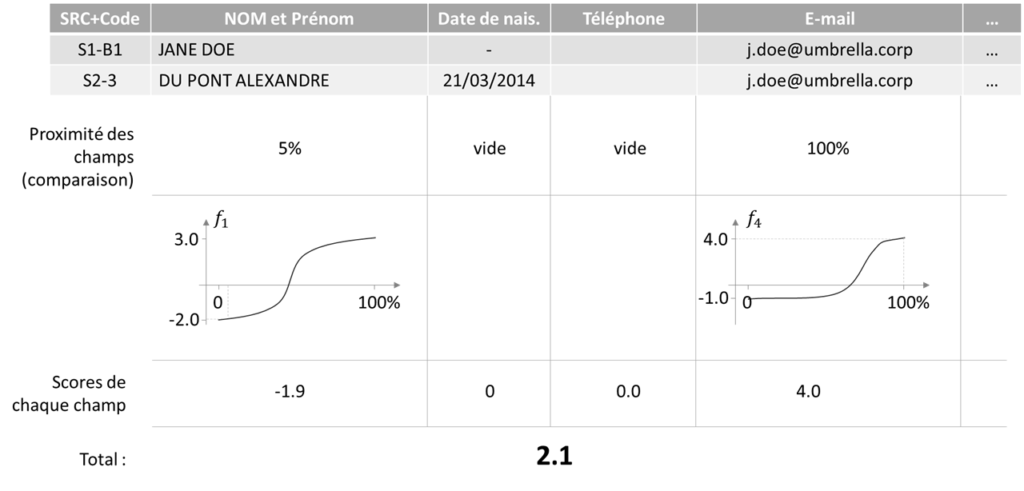
Regardez bien – les fonctions qui convertissent la proximité en score ne sont pas linéaires dans le cas général ! I.e. vous n’avez pas de droit d’utiliser une somme pondérée si vous voulez obtenir le meilleur résultat.
Une fois que nous avons nos scores, nous pouvons les comparer aux seuils. Si, par exemple, le score est supérieur à 7.0, nous allons automatiquement décider qu’il s’agit d’un doublon. Sinon, si le score est inférieur à 2.0 – ignorer la paire. Si le score est entre 2.0 et 7.0, notre système ne pourra pas prendre une décision automatiquement – c’est le moment de faire appel à algorithme organique, dit autrement un être humain (le fameux data steward) ! NB : dans vos modèles, les seuils seront différents.

Dans notre exemple, la paire « Jane Doe vs Du pont Alexandre » sera revue manuellement, alors que la paire « Jane Doe vs Doe Jane » sera rapprochée automatiquement.
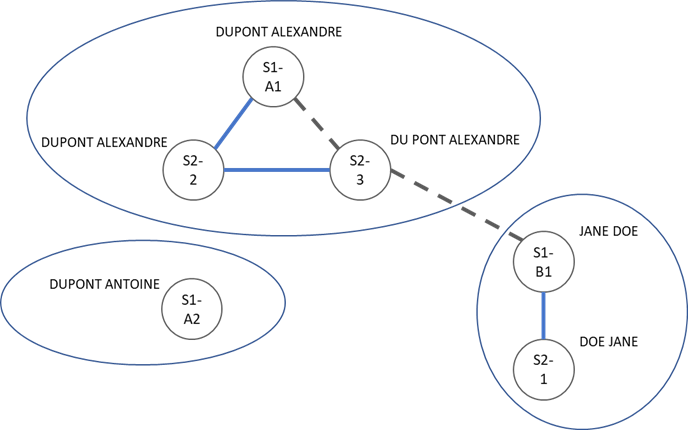
Après le scoring et la comparaison des scores aux seuils, voici notre résultat : trois objets métiers sont identifiés. Il reste une tâche à revoir manuellement (celle qui est interne à l’objet « DUPONT ALEXANDRE » peut être ignorée par transitivité) :
Il ne nous reste qu’à générer les identifiants pour chaque groupe d’objets et sortir une table de transcodification :
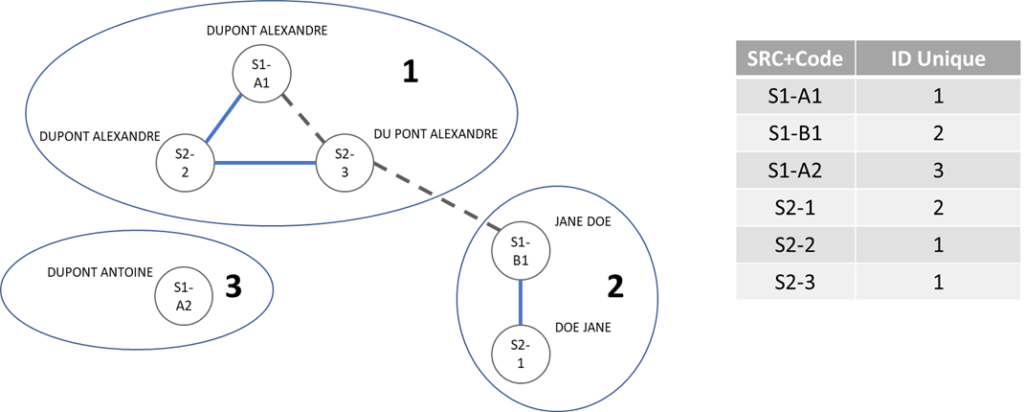
Vous pouvez maintenant utiliser l’ID unique pour la recherche des personnes, pour le dédoublonnage, le chargement d’une dimension dans le DWH, etc.
Est-ce complet? Bon, c’est vrai, nous n’avons pas révélé comment obtenir les fonctions de scoring, mais c’est la partie « technique ». De même, nous n’avons pas dit comment faire les interfaces de Data Stewards, mais c’est du UX. Qu’est-ce que nous pourrions avoir oublié ?
Même dans notre revue rapide nous ne pouvons pas passer à côté du problème de nombre de paires. Si vous avez un exemple avec 6 objets, vous devez comparer chaque objet à chaque autre objet et cela nécessite 15 comparaisons. Et si nous parlons de la base de données de 1000 objets, il nous faut 499 500 comparaisons, etc. La complexité en temps est quadratique !
- Heureusement, des solutions existent ! La plus simple est de comparer uniquement les objets ayant un attribut en commun, par exemple, comparer les objets qui ont la même date de naissance, les 3 derniers chiffres identique du numéro de téléphone, le même prénom, etc. Cette méthode s’appelle blocking. I.e. on traite les « blocks » de données. Nous pouvons faire plusieurs itérations avec des blocks construits différemment.
- L’approche la plus avancée c’est l’utilisation d’un index inversé, mais c’est un peu plus compliqué que ça en a l’air.
Finalement, notre processus de rapprochement peut être présenté comme un flux suivant :
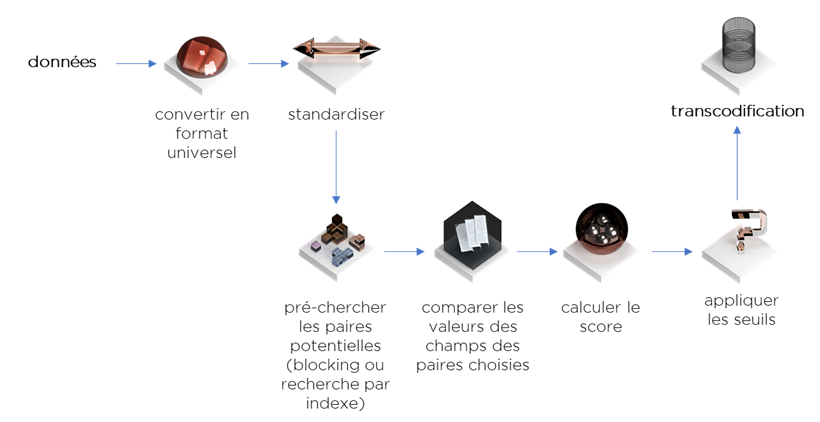
Si vous avez survécu jusqu’ici, vous avez désormais une idée du « state of art » du rapprochement de données. Par contre, vous aurez du mal à trouver un outil qui implémente correctement la méthode de Newcombe et les méthodes avancées d’indexation même si la qualité de données est à la mode, beaucoup de sociétés sont sous la pression du RGPD et encore tout-le-monde-sait-construire-un-entrepôt …
Bonne santé à vous et à vos SI et si la prochaine fois on vous propose d’utiliser une clé fonctionnelle, posez les bonnes questions !
Pingback: Projet Data hub : mythe ou réalité ? – Ordre d'informaticiens
Pingback: Use case : Data Hub de synchronisation – Ordre d'informaticiens
Pingback: Dimensions « Master Data » : problèmes et solutions – Ordre d'informaticiens
Pingback: MDM + BI = 💀/🧡 – Ordre d'informaticiens
Pingback: La gestion des données RH – Ordre d'informaticiens
Pingback: Data Quality : les types d’erreurs – Ordre d'informaticiens
Pingback: don’t-do-it : La clé fonctionnelle (business key) – Ordre d'informaticiens
Pingback: La consolidation de données : rapprochement – Ordre d'informaticiens