
Aujourd’hui, je voudrais vous parler des données non-structurées. C’est un sujet plus qu’important selon moi, mais pour des raisons différentes que vous imaginez 🙂
Pourquoi ?
Presque toute présentation autour du sujet des « données non-structurées » démarre par des statistiques sur le volume de données générées et consommées dans le monde :
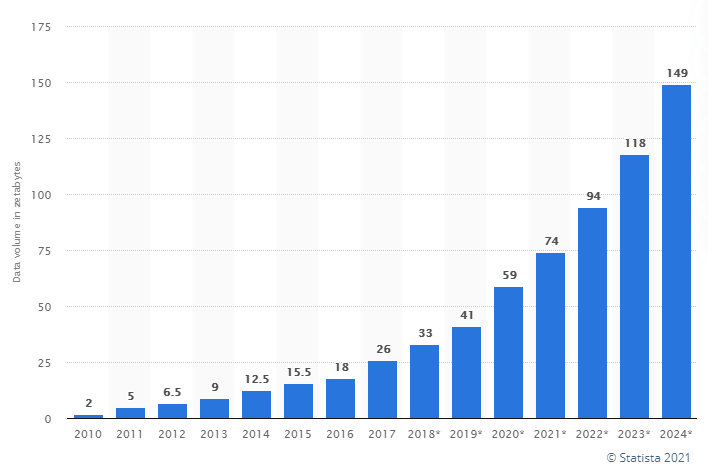
Ce schéma est en zettabytes, où un 1 ZB = 1 073 741 824 TB = 1 180 591 620 717 411 303 424 bytes. Si les données sont correctes, ce sont des chiffres astronomiques, littéralement !
La suite est facilement prédictible : selon les différentes estimations, entre 60% et 95% de ce volume est constitué de données non-structurées (pour l’instant, peu importe ce que cela veut dire) … c’est pour cela que vous devez absolument installer Hadoop / Spark / NiFi / etc aujourd’hui.
Passons quelques instants pour comprendre la structure de cette pile incroyable de données :
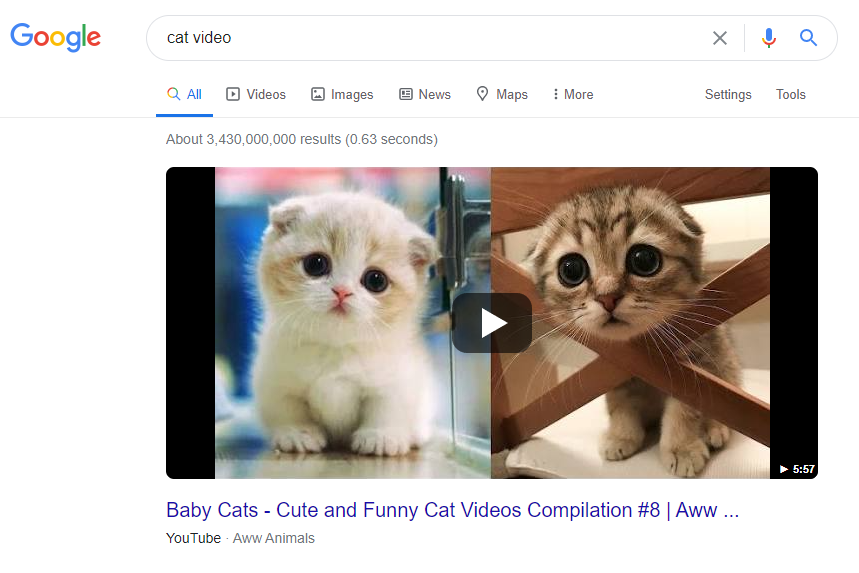
1/ Les vidéos de chatons (autour de 3 430 000 000 de résultats) :
2/ Les stats d’un autre site populaire : https://www.pornhub.com/insights/2019-year-in-review.
En fait, pas loin de 80% du trafic Internet est en réalité un stream vidéo !
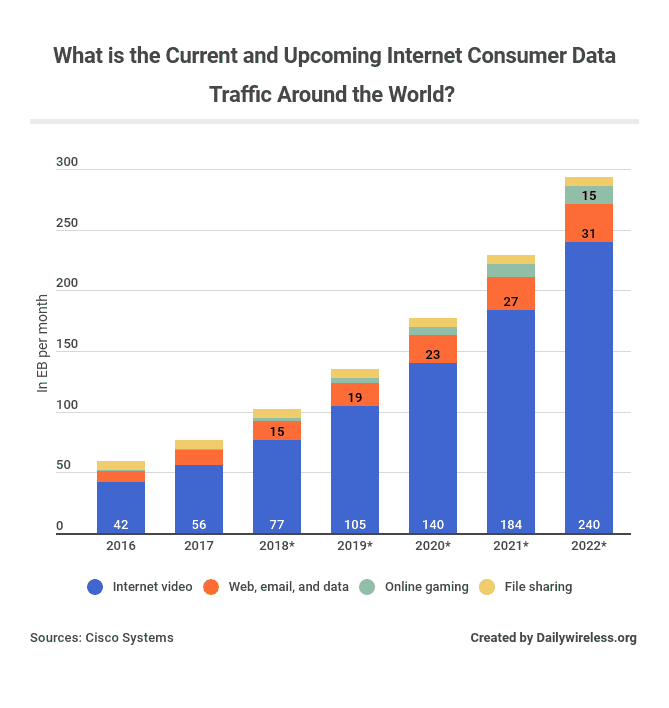
Question primordiale, est-ce vraiment si important pour vous qu’il existe 70 ZB de vidéos, jeux en ligne et de fichiers partagés (dont une majorité de photos) dans le monde ?
Vous avez probablement déjà compris que dans la notion dite « données non-structurées », vous pouvez sentir la hype et les commerciaux pas loin… Bon, admettons que derrière ce hype, il y a quand même quelque chose d’important.
Définition
Les définitions de « données non-structurées » prennent en général deux formes :
- Forme récursive. Données non-structurées – ce sont les données sans structure.
- Forme de la liste infinie. Données non-structurées ce sont : vidéos, audios, images, documents, présentations, e-Mails, chat (encore chat!), données des capteurs intelligents et M2M (IoT, industrie 4.0, etc), données de réseaux sociaux, données scientifiques, open data, etc…
Les deux types de définitions sont assez inutiles, à mon goût. Je vous propose d’essayer de les combiner et de voir le résultat.

Capteurs intelligents et M2M
Voici un exemple de données IoT que j’ai volé sur un site spécialisé :

Devant vous – le JSON – l’un des formats les plus structurés possible (à la mode dans ce domaine, donc ce n’est pas juste un exemple). Afin d’extraire les donnes, dans la plupart de langages et de bases de données, il vous faut faire quelque chose comme new JSON("...").getDouble("DC Voltage 1") ou cast("..." as json)->>'DC Voltage 1'.
La seule possibilité pour dire que JSON est « non-structuré » c’est d’inclure dans la définition la « structure flexible » de ce format (le considérer comme « schema-on-read ») car le format peut s’évaluer en futur, donc l’ensemble pour vous en un « black box »… mais le même est vrai pour n’importe quel autre source de données, donc les données des capteurs ne passent pas notre vérification.
Réseaux sociaux
L’époque à laquelle vous pouviez scrapper Facebook ou LinkedIn est révolue. Maintenant, les plateformes vous proposent d’utiliser des outils (payants) pour accéder aux données avec bien sûr une vision ultra-structurée des données. Comme ça, vous n’avez pas à vous poser des questions concernant la collecte :
À l’inverse :
- si vous travaillez dans la recherche des graphes des réseaux sociaux, vous êtes sûrement au courant qu’il existe des bases orientées « graph », donc ultra-structurées ;
- si vous faites aussi de l’analyse de sentiments sur Twitter, vous êtes probablement une société spécialisée sur NLP (Natural Language Processing), ainsi, vos clients achètent des statistiques et des tableaux annotés et non pas des données brutes, i.e. l’impact de la gestion de ces données « non-structurées » est limité par votre société, alors que pour vos clients tout est bien structuré ;
- etc.
Pour résumer, les données des réseaux sociaux, même si à certain moment, elles peuvent exister sous forme de texte quelque part, cela ne change pas grand chose pour la majorité des sociétés car à la fin, la structure sera extraite et traitée.
Données scientifiques, open data, …
Ce sujet est encore plus anecdotique :
- les chercheurs n’ont jamais eu beaucoup de problèmes pour stocker les données / échanger avec les données sous des formats différents, etc ;
- nous pouvons assez facilement éliminer toutes données « scientifiques » dans les formats tabulaires (CSV/TSV/etc) car ce sont les données parfaitement structurées – il est facile de le prouver car tout chercheur en quelques minutes fera l’import de ces fichiers dans son Matlab/Mathcad/etc ;
- les images (ex. imagerie médicale) quand ils sont le sujet de traitement ne sont pas ni plus ni moins les grands tableaux croisés de chiffres, même s’il est vrai qu’il n’existe aucun algorithme idéal pour extraire depuis ce tableau la réponse à la question « est-ce qu’il y a un tumeur ou pas », c’est ça le but de la recherche – quand un statisticien lambda regarde les tableaux d’analyse financière, il ne peut pas comprendre grande chose, mais cela ne rend pas pour autant les données financières « non-structurées ».
Ici, nous voyons bien que les deux définitions se contrarient encore une fois.
Conclusion intermédiaire
Nous avons vu que certaines données considérées comme « non-structurées » sont en fait juste « autrement formattées », mais il reste encore des données « vidéo », « image » et « texte » qui sont « non-structurées », n’est-ce pas ?
Techniques avancées
Les données « complexes », tels que vidéos, images ou le texte en langage naturel sont souvent traités pour une certaine raison et les utilisateurs n’attendent pas que le vidéo puisse être « requêtée » en direct avec un langage semblable à SQL. Qu’attend le métier et avons-nous vraiment des difficultés techniques ?
Par exemple, le sujet récurrent de traitement de vidéo est la détection d’objets : personnes, machines, défects de production. Le réseau de neurones comme YOLO (https://pjreddie.com/darknet/yolov2/) est en capacité de détecter avec une bonne précision les objets en temps réel sur un téléphone portable. Ce que vous allez obtenir à la fin, c’est un tableau avec tous les objets, les types et les positions. Est-ce que ce tableau est structuré ? Absolument. Dans ce cas, nous pouvons probablement « oublier » le vidéo et clore le sujet des données non-structurées ?

Je voulais simplement ajouter que vos bases de données sont aussi stockées sur les HDDs/SSDs sous format très complexe. Vous ne le voyez pas car vous avez un moyen pour y accéder via SQL et ainsi, ignorer les subtilités du format de stockage. Dans ce cas, au lieu du SQL, j’utilise YOLO. Quelle est la différence ? (Sauf pour le chercheur qui a créé ce réseau, mais pour lui c’était le but final, i.e. nos arguments précédents concernant les données scientifiques s’appliquent).
Si nous considérons le texte et l’une des tâches populaires – l’analyse des sentiments, nous allons arriver à la même conclusion : il est « compliqué » d’extraire le sentiment depuis le texte. En effet, le texte lui-même n’est pas dans un format tabulaire… Il doit être « non-structuré ». Mais c’est une vision de très haut niveau car pour le data scientiste, le format texte est parfaitement structuré et une fois qu’il a lancé ses algorithmes, nous allons obtenir un format tabulaire avec les sentiments. Étonnamment, on revient encore à des données parfaitement structurées…
Hadoop ≠ non-structuré
Nous pouvons sincèrement reconnaitre l’existence de différents formats de données, les uns plus complexes à utiliser que les autres. Pour autant, pourquoi faire autant de bruit ?
J’ai rencontré beaucoup d’informaticiens (autrement très bons) « convertis » par les commerciaux des solutions BigData. On peut entendre :
« Notre Master Data est en format non-structuré. On l’avait mis en format ORC dans Hadoop. »
ou
« Nous n’avons pas décidé quoi faire avec cette information, mais au cas où, on va tout garder dans un multi-cloud. »

C’est cette vision (qui est beaucoup plus fréquente que des projets de traitement de vidéo / image / NLP) qui m’embête le plus. Le format sur HDD / SSD n’est pas important. La seule chose importante est votre capacité de manipuler l’information de manière la plus optimale possible.
Conclusion intermédiaire
Passons à l’instant « généralisation », pour cela, je vous propose de considérer deux axes :
- « la difficulté d’accès » – soit le niveau de complexité d’utilisation de données dans un but donné;
- « le niveau de besoin » – soit le niveau d’abstraction du besoin fonctionnel ou technique.
Si nous mettons certaines tâches dont nous avons parlé sur ces deux axes, nous devons retrouver l’image suivante :
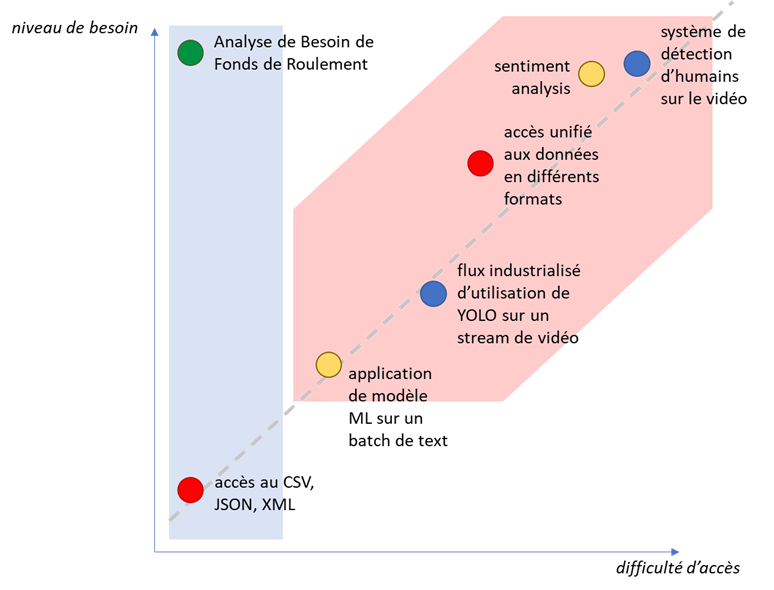
Sur la diagonale, il y aura des données « non-structurées », mais toutes données avec « difficulté d’accès » assez bas, elles sont donc « structurées »… cela illustre que ce n’est pas probablement la propriété de données en tant que tel mais plutôt notre vision des tâches liées à ces données qui n’est pas structurée. Ce qui peut se comprendre ! Ce n’est pas un chaos non-structuré, c’est juste la complexité que l’on perçoit, et ça change tout.

Pour l’organisation
Dans une logique purement pragmatique, nous pouvons juste considérer deux sujets :
- la valeur de données pour nous (combien je vais perdre si je supprime / ignore les données en question) ;
- le coût d’accès (combien je vais dépenser pour accéder aux données dans ce format / convertir les données dans les autres formats).
Je peux me tromper, mais je suis persuadé que la majorité des sociétés, après avoir reçu le devis d’un spécialiste en NLP, se dira que le traitement de mails/chats/Twitter et leur analyse n’est finalement pas si attractif ou au moins peut être sous-traité.
Conclusion
Selon moi, il n’existe pas de données « sans structure » car sinon ce ne sont pas des données. En revanche, oui, il y a des données qui sont plus ou moins faciles à manipuler et à extraire dans un contexte donné. Ces notions, plus complexes, sont bien moins « vendeur », mais beaucoup plus « éthiques » vis-à-vis des clients.
Bonne santé à vous et à vos données.
PS : N’hésitez pas à lancer vos tomates si vous n’êtes pas d’accord – soit via LinkedIn, soit via notre formulaire de contact.