
Les défauts des autres enseignent au sage de corriger les siens.
Publilius Syrus (85 – 43 avant JC) – Poète romain
Aujourd’hui je vous propose d’aborder un sujet très appliqué – la qualité de données et la typologie d’erreurs. J’espère que la liste qui va suivre (probablement incomplète) pourra aider nos lecteurs qui se lancent dans un projet Data Quality ou un projet d’automatisation de type ERP, CRM, etc.
Valeurs incorrectes (précision, exactitude)
Les raisons les plus fréquemment rencontrées :
- faute de fparpe :),
- les données, correctes au moment de la saisie, n’ont pas été mises à jour depuis (données périmées) .
Les fautes de frappe sont souvent faciles à identifier : si nous parlons de texte (nom/prénom/adresse), les fautes de frappe produisent les mots uniques ou presque uniques dans la base de données, donc il vous suffit de lancer l’analyse de la fréquence d’apparition des mots et analyser les résultats.
Exemple. Si vous rencontrez dans la liste de prénoms un prénom « Mari », vous pouvez vous poser la question si c’est un vrai prénom ou bien une faute de frappe de « Marie » ou « Maria ». Etant donné que (suivant les statistiques de Forebears https://forebears.io/) le prénom « Mari » (porté par approximativement 800 personnes) est presque 1700 fois moins fréquent en France que les prénoms « Marie » et « Maria », vous pouvez supposer que c’est une faute de frappe.

Dans les autres cas, les fautes de frappe portant sur un code peuvent être identifiées en se servant de la structure du code en question.
Exemple. En France, les codes (SIREN, SIRET, TVA, numéro de sécurité sociale) sont protégés par la formule de Luhn (https://fr.wikipedia.org/wiki/Formule_de_Luhn). Même si vous devez vérifier d’autres types de codes, il est fort probable qu’il existe un certain contrôle de format que vous pouvez appliquer pour assurer la vérification.
Les données périmées sont en général impossibles à détecter sans analyser les sources externes ou croiser plusieurs occurrences des mêmes données.
Exemple. En France, si vous devez vérifier la fraîcheur des données, parfois vous pouvez les trouver sous format Open Data. Par exemple, toutes les sociétés et les établissements actuellement ouverts sont disponible gratuitement sur https://www.data.gouv.fr/fr/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/.
Complétude
L’incomplétude est souvent définie comme le manque de données qui doivent être mises à disposition.
Premièrement, une précision est nécessaire : nous ne parlons pas des données « nulles », de lignes de caractères « vides » ou des chiffres à « zéro », on parle bien de la disponibilité de données utiles car sinon un simple remplacement des nulles par une ligne « N/A » doit permettre de résoudre le problème, mais ce n’est pas le cas.
Deuxièmement, il faut comprendre que parfois les données ne sont disponibles que partiellement. Si vous cherchez les dates de naissance et que je vous envoie les années de naissance, vous ne pouvez pas dire que les données ne sont pas du tout disponibles – elles le sont, mais partiellement, donc nous parlons bien de degré de complétude.
A noter que « null » technique ne veut pas forcément dire que les données sont incomplètes.
Exemple. Chaque voiture qui sort des chaînes de production dispose d’un code VIN, un identifiant unique. Supposons que vous analysez la base de données qui répertorie les ventes de voitures et que vous tombiez sur des VINs vides. Est-ce pour autant un cas d’incomplétude ? Pas forcément ce sont peut être les voitures précommandées à l’usine, mais encore non produites (malgré le fait qu’elles sont déjà payées).
Pourquoi les données peuvent être incomplètes ? En général, il y a deux raisons majeures :
- différence entre les processus fonctionnels (ex. l’équipe avant-vente n’a pas besoin de connaître le code TVA de clients potentiels), donc ces données seront « incomplètes » dans le cadre d’une analyse financière,
- problèmes de modèle de données (i.e. les utilisateurs ne peuvent pas saisir les données dans son outil car le modèle de données est trop restrictif).
Boue (conformité au format)
Ce type d’erreur est un peu plus complexe que les précédents – les consommateurs trouvent les données, elles sont à jour, mais elles sont toujours impossibles à consommer puisqu’elles ne respectent pas le format préalablement défini.
Exemples :
- numéro de sécurité sociale dans un champ « description »,
- les commentaires dans le champ « téléphone » en plus au téléphone lui-même,
- salutation dans le champ « nom »,
- etc.
Pourquoi vos utilisateurs saisissent les données de cette manière ? La raison se trouve dans le besoin de garder cette information quelque part alors que le modèle ne le permet pas, donc ils essaient de contourner les limitations d’outil de cette façon.
Afin d’identifier les cas où les données ne sont pas conformes au format, parfois vous pouvez spécifier le format souhaité et lancer une vérification, mais en général ce n’est pas possible car même le téléphone peut être écrit très différemment tout en restant correct (vous ne pensez pas que le téléphones ne peuvent pas contenir des lettres ?).

Dans la grande majorité des cas, vous allez devoir spécifier un-par-un chaque type d’erreur identifié, donc vos analyses ne seront jamais exhaustives.
Afin d’identifier les différents types d’erreurs, un profiling de patterns peut être utilisé. Si les erreurs sont assez fréquents, vous allez voir les « formats incorrects » apparaître dans vos statistiques :
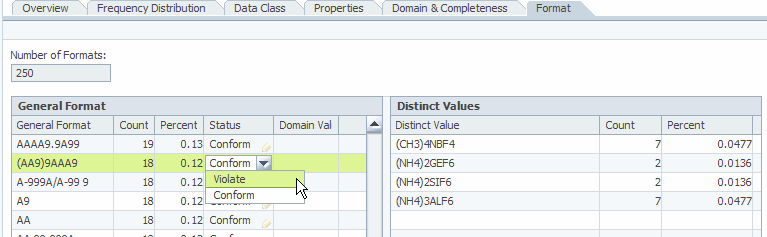
N’oubliez pas que vos analyses vont suivre la loi 20/80, chaque nouvelle amélioration de vos règles deviendra de plus en plus complexe avec l’amélioration de la couverture de tests.
Erreurs logiques (cohérence)
Les erreurs logiques dans les données sont assez souvent liés aux autres types d’erreurs. Nous les distinguons juste à cause de notre capacité de les identifier assez facilement : nous pouvons croiser plusieurs champs (d’un ou de plusieurs jeux de données) et trouver tous les objets qui ne passent pas le test « logique ».
Exemple. Si vous recevez les données d’une transaction de vente à la société liquidée, vous pouvez assez certainement conclure que soit le lien entre la transaction et le client, soit le statut du client est erroné.
Exemple. Vous recevez les données personnelles d’une famille et vous trouvez que la mère est née après sa fille, donc vous savez que l’une de deux dates de naissance est erronée ou l’information de la relation est incorrecte.
De même manière vous pouvez relativement facilement vérifier :
- le sexe du client par son prénom,
- l’enchaînement de dates de différentes procédures appartenant au même workflow,
- les données d’adresses (code postal – ville – pays),
- etc.
Règles fonctionnelles non-automatisées
Ce type d’erreur est une variante des erreurs de logique, mais suffisamment importante pour la considérer séparément. Dans chaque société, il y a des processus métier non-(ou partiellement)-automatisés. Ces processus vont de temps en temps produire des erreurs que nous pouvons analyser post factum au niveau DQ.
Exemple. Supposons que votre société a un grand client qui génère 5% de chiffres d’affaire. Ce client impose ses propres règles de gestion de la documentation : la nomenclature, les codes des factures, etc. Vos processus doivent donc s’aligner avec les demandes du client aussi important. Chaque facture produite avec un code qui ne correspond pas à la nomenclature de ce client risque ne pas être payée…
Doublons
Le sujet de doublons est plus ambiguë et assez certainement très important. Le problème est le suivant : dans un dataset donné il existe plusieurs répétitions non-identifiées de données qui décrivent le même objet métier.
Par exemple :
- dans un système BI, la dimension « clients » a plusieurs lignes qui décrivent la même société ou la même personne,
- le fournisseur nous envoie deux fois la même facture et, à cause, du manque de vérification elle vient d’être intégrée dans le système comptable deux fois,
- la nomenclature « pays » contient deux fois « France » sous les codes « FR » et « FRA »,
- etc.
Assez souvent, les erreurs liés aux doublons ont plus de risque pour le business. Même si ils sont complexes à identifier, je vous conseille de vous concentrer sur ce sujet avant les autres.
Afin de résoudre le problème de doublons, nous devons les identifier et probablement les éliminer (plus d’info ici : https://ithealth.io/rapprochement-de-donnees/).
À noter que pour l’identification de doublons, il existe sa propre notion de « complétude ». Si nous comparons l’objet à lui-même et si l’information n’est pas suffisante pour le rapprochement d’objet à lui-même, il est « incomplet » car donc il ne se rapprochera pas à ces doublons non plus.
Erreurs spécifiques
Les données cachées
C’est un cas de « heisenbug », i.e. un problème qui existe et n’existe pas en même temps.
Si je vous propose de créer le reporting par les régions de la France en vous donnant les adresses concaténées, vous serez confrontés à ce problème – les données sont devant vous, mais il faut encore les « extraire » depuis une ligne de caractères. Si vous prenez en compte les fautes de frappe éventuelles, vous allez comprendre que ce n’est pas une tâche évidente.
Voici un autre exemple. Une grande société utilisait un système comptable n’ayant pas de champ dédié pour enregistrer le code de chaque contrat. Ainsi, le code, la date et le nom du client étaient concaténés dans un « nom du document ». Les données sont disponibles aux humains, mais il est assez difficile d’extraire le code contrat depuis ce champ de façon fiable (imaginez les contrats sous les numéros 1998, 1999, 2000, …, clients avec des chiffres dans les noms, utilisation de « O » au lieu de zéro).
Données insuffisamment traitées
Si vous manipulez les données personnelles, surtout dans le domaine immobilier, vous pouvez avoir besoin d’identifier le ménage (famille qui habite à l’adresse donnée). Si vous consultez la liste des personnes et vous trouvez que les ménages ne sont pas bien identifiés, vous ne pourrez pas potentiellement traiter les données en question.
C’est un exemple de données qui sont probablement parfaitement correctes, mais toujours inutilisables. Vous pouvez remarquer que dans mon exemple je cite un cas particulier de « doublons » (dans le sens de « ménage »).
Problèmes de structure
Un erreur très spécifique si vous manipulez plusieurs datasets, pour lesquels l’intégrité du référentiel n’est pas garanti, vous pouvez bien avoir des clés techniques qui pointent vers les objets « inconnus ».
Exemple. Dans les systèmes ERP, vous utilisez une clé CRM pour rendre les données traçables jusqu’au CRM. Si les données sont supprimées ou mergées dans CRM, cette clé deviendra invalide.
Conclusion
Votre projet de qualité de données est probablement très spécifique, mais les erreurs ne le sont pas forcément. J’espère que cette liste va vous aider à les identifier. Si vous connaissez d’autres types d’erreurs récurrents – laissez-nous un commentaire sur LinkedIn ou via le formulaire de contact.
Bonne santé à vous et à vos données !
Pingback: La consolidation de données : validation – Ordre d'informaticiens